1. Overview
The IPU Inference Toolkit is designed to provide end-to-end inference solutions with low-latency and high-performance, enabling users to deploy models to Graphcore IPU products conveniently and quickly.
This quick start guide gives an introduction to the IPU Inference Toolkit.
Note
You need to have the correct IPU hardware (C600) and the Poplar SDK installed before using the IPU Inference Toolkit.
1.1. IPU inference architecture
As shown in Fig. 1.1, IPU inference is divided into two parts: compilation and runtime. During compilation, deployed models are compiled into PopEF files via PopRT. At runtime, the PopEF files generated in the compilation phase are loaded and inference is performed.
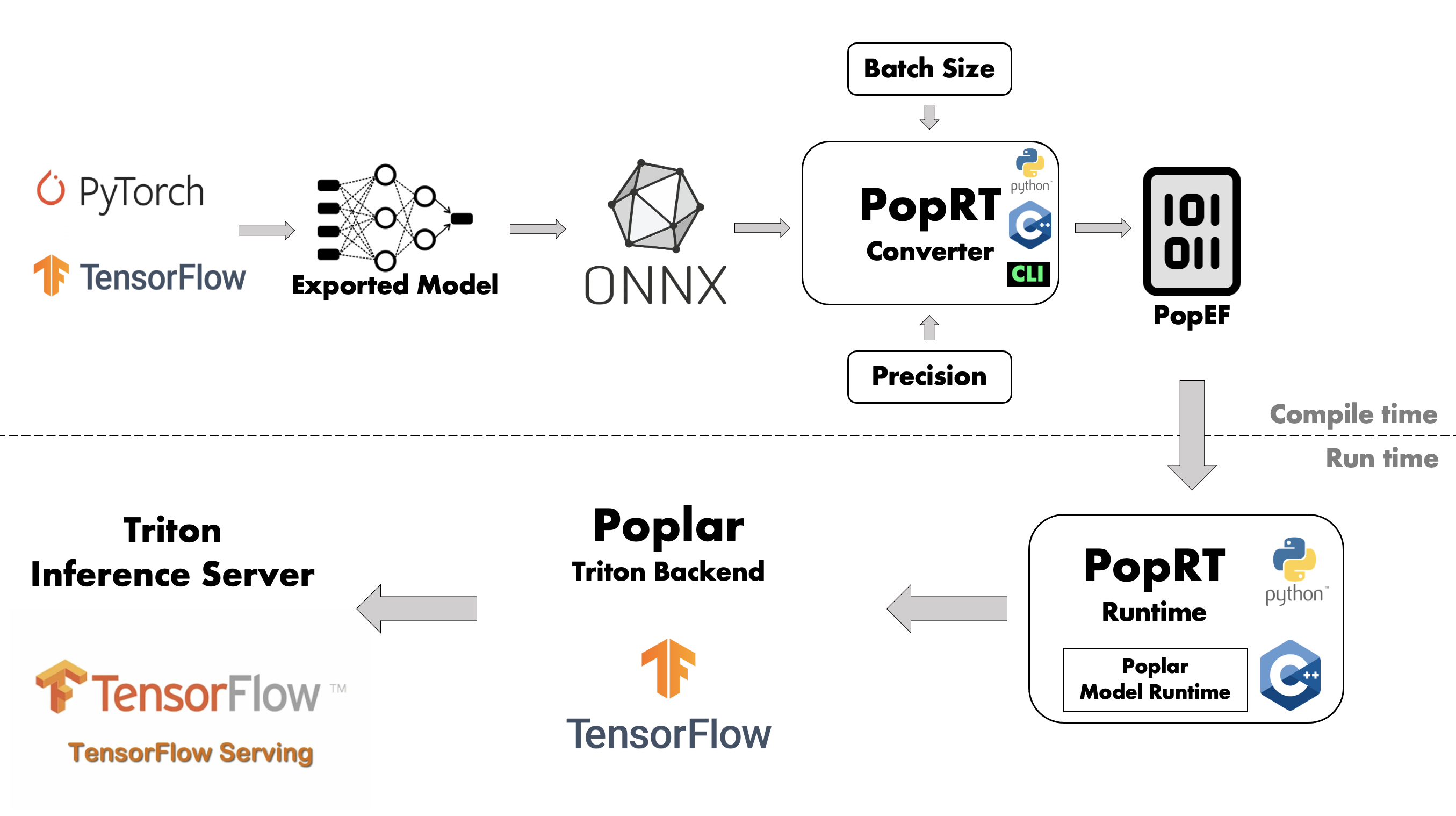
Fig. 1.1 IPU inference architecture
PopRT uses ONNX models as input. Models in other formats will need to be converted to ONNX before they can be used – there are tools provided by the ONNX community that can perform this conversion, for example tensorflow-onnx to convert a TensorFlow model to ONNX. More information about such tools can be found in the ONNX GitHub repositories.
PopRT provides container images for Ubuntu 20.04 and Debian 10. In this quick start guide we use an ONNX model and the corresponding Ubuntu 20.04 image as an example of how to compile and run models on IPU hardware.
Note
Please contact Graphcore Sales for details on how to access the container images used in this quick start guide.