1. 概述
IPU Inference Toolkit Quick Start将以 ONNX 模型为例,讲述如何通过Graphcore提供的工具编译、运行模型并将模型部署到 Triton Inference Server 。
备注
本文假设IPU硬件和SDK都已经安装无误
1.1. IPU推理方案架构
如图 Fig. 1.1 所示, IPU推理方案分为编译和运行时两个部分。编译阶段通过 PopRT 将部署的模型编译为 PopEF 文件,而运行时负责加载编译阶段产生的PopEF并进行推理。
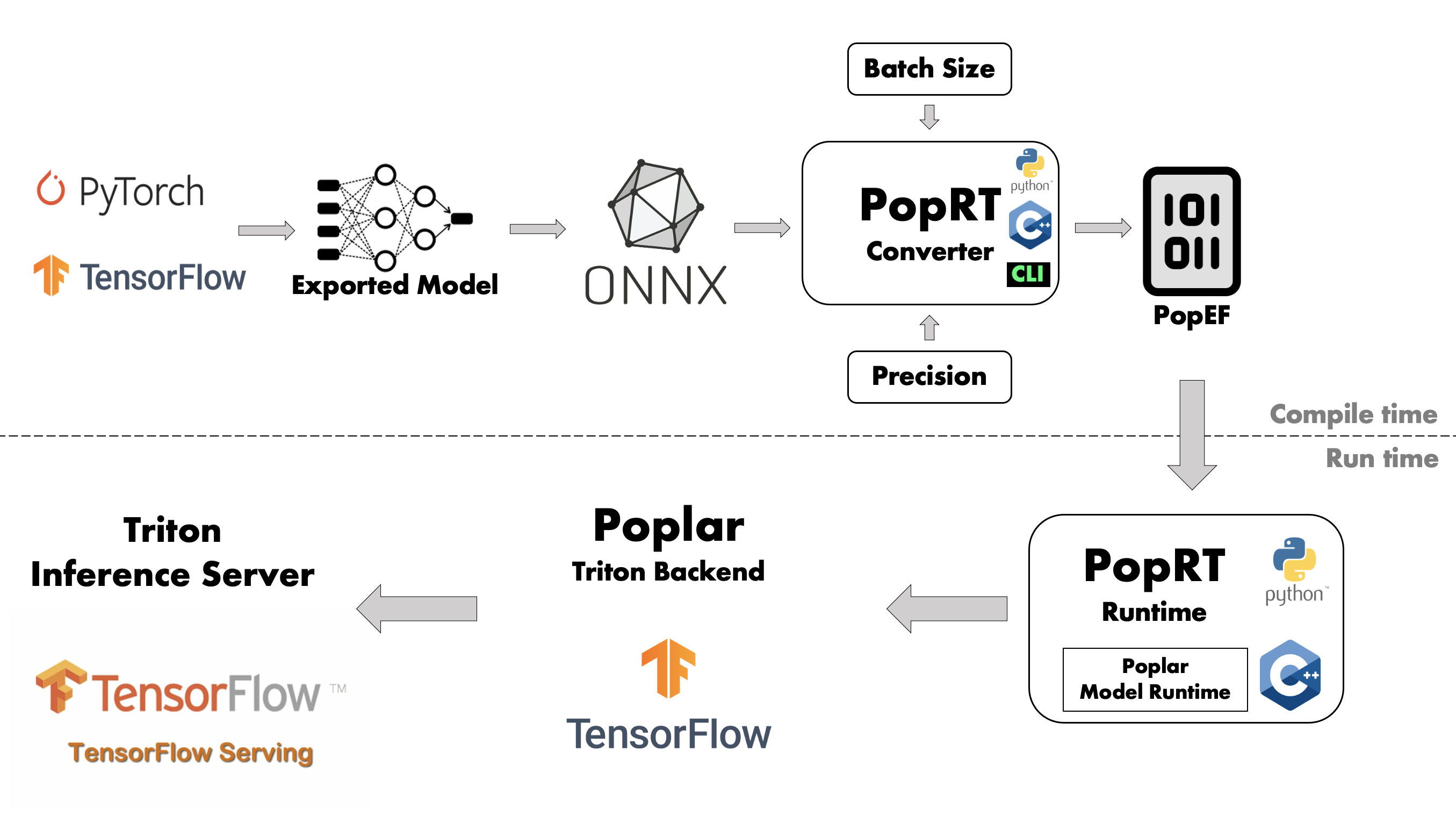
Fig. 1.1 IPU推理方案架构
PopRT以ONNX模型作为输入,其他格式的模型需要先通过深度学习框架或者ONNX社区提供的工具转换为ONNX。 例如,tensorflow-onnx 可以将TensorFlow的模型转换为ONNX, 更多相关工具请参考 ONNX GitHub repositories 。
PopRT提供了Ubuntu 20.04和Debian 10的容器镜像,本文中将以ONNX模型和Ubuntu 20.04镜像为例, 讲述如何将模型编译并运行到IPU硬件上。
备注
关于如何获取本文中使用的容器镜像,请联系 Graphcore Sales 。