4. Creating an IPUJob
Once the CRDs and the IPU Operator are installed, you can start submitting
IPUJobs (MPI-based AI/ML jobs that use IPUs).
4.1. Training job
There are two ways of running a training job:
a single
WorkerPod - the IPU Operator directly starts aWorkerPodmultiple
WorkerPods with a dedicatedLauncherPod - the IPU Operator starts aLauncherPod and multipleWorkerPods;
The first approach is used for training that uses only one node.
The second approach is used for distributed training to multiple Pods
that may run on multiple nodes. It utilizes mpirun or poprun in a
Launcher Pod, that spawns workloads inside Worker Pods.
4.1.1. Simple training
The first IPUJob example shows how to run simple training on one node
using a single Worker Pod.
The following YAML file is an example of an IPUJob with training using
the MNIST PyTorch application:
apiVersion: graphcore.ai/v1alpha1
kind: IPUJob
metadata:
name: mnist-training
spec:
# jobInstances defines the number of job instances.
# More than 1 job instance is usually useful for inference jobs only.
jobInstances: 1
# ipusPerJobInstance refers to the number of IPUs required per job instance.
# A separate IPU partition of this size will be created by the IPU Operator
# for each job instance.
ipusPerJobInstance: "1"
workers:
template:
spec:
containers:
- name: mnist-training
image: graphcore/pytorch-tutorials:3.0.0
workingDir: "/opt/tutorials/simple_applications/pytorch/mnist"
command: ["bash"]
args: ["-c", "pip3 install -r requirements.txt && python3 mnist_poptorch.py --epochs=1"]
restartPolicy: Never
Download mnist-training-ipujob.yaml
There are several fields specific to IPUJob:
- jobInstances
This defines the number of jobs. In the case of training it should be 1.
- ipusPerJobInstance
This defines the size of IPU partition that will be created for each job instance.
- workers
This defines a Pod specification that will be used for
WorkerPods.
Save the above specification file as mnist-training-ipujob.yaml then run:
$ kubectl apply -f mnist-training-ipujob.yaml
ipujob.graphcore.ai/mnist-training created
Now you can inspect what happens in the cluster and you should see something similar to:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ipu-operator-controller-manager-6dc5cb7976-hv4ht 2/2 Running 0 4d18h
ipu-operator-vipu-proxy-669d7fd755-jh4hl 1/1 Running 0 4d18h
mnist-training-worker-0 0/1 Running 0 50s
You can also list the IPUJobs in the cluster and see their status:
$ kubectl get ipujobs
NAME STATUS AGE
mnist-training Running 40s
And you can inspect more details about a specific IPUJob as follows:
$ kubectl describe ipujobs mnist-training
Name: mnist-training
Namespace: default
Labels: <none>
Annotations: <none>
API Version: graphcore.ai/v1alpha1
Kind: IPUJob
Metadata:
Creation Timestamp: 2022-10-25T09:46:32Z
Finalizers:
ipu.finalizers.graphcore.ai
Generation: 3
Managed Fields:
API Version: graphcore.ai/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:spec:
.:
f:ipusPerJobInstance:
f:jobInstances:
f:workers:
.:
f:replicas:
f:template:
.:
f:metadata:
.:
f:labels:
.:
f:app:
f:spec:
.:
f:containers:
f:restartPolicy:
Manager: kubectl-client-side-apply
Operation: Update
Time: 2022-10-25T09:46:32Z
API Version: graphcore.ai/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:finalizers:
.:
v:"ipu.finalizers.graphcore.ai":
f:status:
.:
f:conditions:
f:currentReplicas:
f:desiredReplicas:
f:iPUPartitionCreated:
f:lastMessage:
f:launcherStatus:
f:restartCount:
f:workersStatus:
Manager: manager
Operation: Update
Time: 2022-10-25T09:46:44Z
Resource Version: 112884653
UID: b7eaa6bb-5d01-4702-a1ac-321ec7e97df1
Spec:
Clean Pod Policy: None
Ipus Per Job Instance: 1
Job Instances: 1
Model Replicas Per Worker: 1
Restart Policy:
Back Off Limit: 3
Type: Never
Workers:
Replicas: 1
Strategy:
Rolling Update:
Max Surge: 25%
Max Unavailable: 25%
Type: RollingUpdate
Template:
Metadata:
Labels:
App: mnist
Spec:
Containers:
Command:
python3
mnist_poptorch.py
--epochs=1
Image: bencet/test-operator:latest
Name: test-ipujob
Resources:
Restart Policy: Never
Workers Per Job Instance: 1
Status:
Conditions:
Last Transition Time: 2022-10-25T09:46:44Z
Last Update Time: 2022-10-25T09:46:44Z
Message: Waiting for resources to be ready.
Reason: IPUJobPending
Status: False
Type: Pending
Last Transition Time: 2022-10-25T09:46:51Z
Last Update Time: 2022-10-25T09:46:51Z
Message: All instances are running
Reason: IPUJobRunning
Status: False
Type: Running
Last Transition Time: 2022-10-25T09:47:56Z
Last Update Time: 2022-10-25T09:47:56Z
Message: One or more instances finished successfully
Reason: IPUJobSucceeded
Status: True
Type: Succeeded
Current Replicas: 0
Desired Replicas: 1
I PU Partition Created: false
Last Message: One or more instances finished successfully
Launcher Status: Completed
Restart Count: 0
Workers Status:
Events: <none>
4.1.2. Distributed training
In the case of distributed training a Launcher Pod with multiple
Worker Pods is used.
The following YAML file is an example of an IPUJob with distributed
training using the MNIST PyTorch application:
apiVersion: graphcore.ai/v1alpha1
kind: IPUJob
metadata:
name: mnist-distributed-training
spec:
jobInstances: 1
ipusPerJobInstance: "2"
workersPerJobInstance: "2"
modelReplicasPerWorker: "1"
launcher:
command:
- mpirun
- --allow-run-as-root
- --bind-to
- none
- -np
- "2"
- bash
- -c
- cd /opt/tutorials/simple_applications/pytorch/mnist; pip3 install -r requirements.txt && sed -i 's/poptorch.Options()/poptorch.Options\(\).randomSeed\(0\)/g' mnist_poptorch.py && python3 mnist_poptorch.py --epochs=1
workers:
template:
spec:
containers:
- name: mnist-distributed-training
image: graphcore/pytorch-tutorials:3.0.0
Download mnist-distributed-training-ipujob.yaml
There are several fields specific to IPUJob that are relevant to
distributed training workloads:
- jobInstances
As in the example above, this should be set to 1 for training jobs.
- workersPerJobInstance
This defines the number of workers and can be used to scale down or scale up the number of
Workerpods.- modelReplicasPerWorker
Number of model replicas that will be made available for each worker (parallel data technique), details below.
- ipusPerJobInstance
This defines the size of IPU partition that will be created for each job instance.
Having seen both single worker and multiple worker training IPUJobs we
can now explain the logical structure of IPUJob.
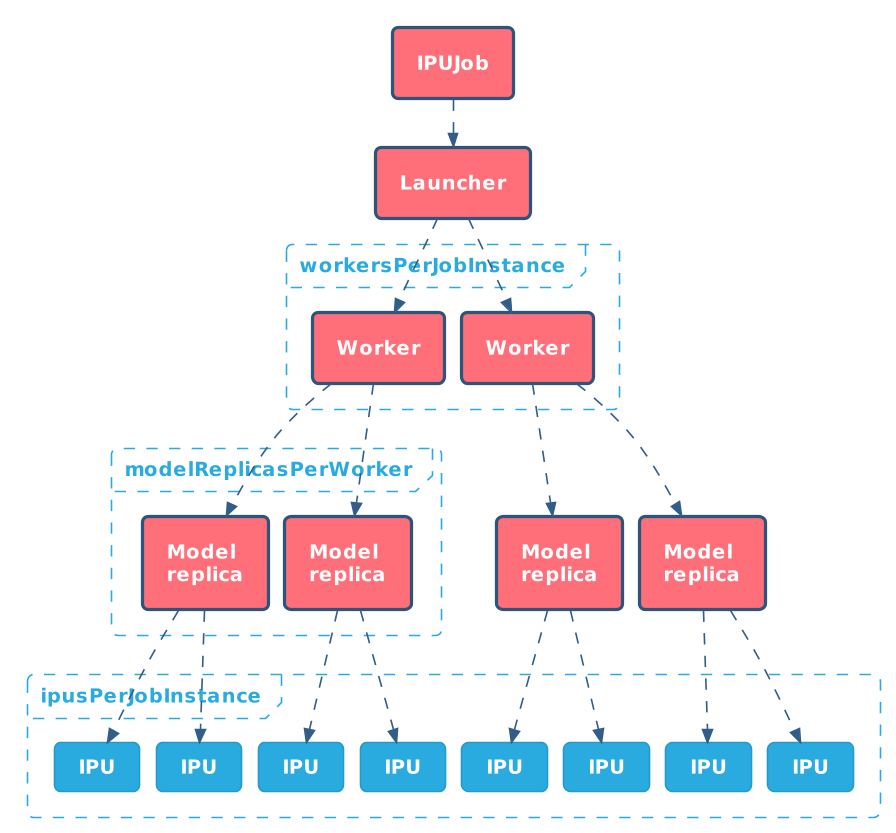
The picture above shows relations between various entities within
IPUJob.
IPUJob may have zero or one Launcher. This is controlled by
the presence of a launcher field. There could be more than one
Launcher if the jobInstance field is greater than 1, but it
does not make sense in case of training, for which it should be set to 1.
There can be one or more Worker Pods. The number of workers
is defined by workersPerJobInstance. This allows the distribution
of training to multiple nodes.
If we want to leverage the parallel data technique for training to
speed it up, we may increase the number of model replicas by increasing
modelReplicasPerWorker field. Generally, it should be set to 1 or
to a power of 2 (for example 2, 4, 8 and so on).
Having set the above numbers, the ipusPerJobInstance field needs
to be adjusted. It should contain the number of IPUs required by one
model replica multiplied by number of replicas and number of
Worker Pods.
Let’s go back to our example and run it. Save the above
specification file as mnist-distributed-training-ipujob.yaml then
run:
$ kubectl apply -f mnist-training-ipujob.yaml
ipujob.graphcore.ai/mnist-training created
Now you can inspect what happens in the cluster and you should see something similar to:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ipu-operator-controller-manager-6dc5cb7976-vlj72 2/2 Running 0 45h
ipu-operator-vipu-proxy-669d7fd755-jh4hl 1/1 Running 0 7d13h
mnist-distributed-training-launcher 0/1 Completed 0 16h
mnist-distributed-training-worker-0 1/1 Running 0 16h
mnist-distributed-training-worker-1 1/1 Running 0 16h
You may notice that now there is a new Launcher Pod (previously
there was no Launcher) and 2 Worker Pods (previously there was 1).
You can also list the IPUJobs in the cluster and see their status:
$ kubectl get ipujobs
NAME STATUS AGE
mnist-distributed-training Running 40s
And you can inspect more details about a specific IPUJob as follows:
$ kubectl describe ipujobs mnist-training
4.2. Inference job
IPU Operator supports running inference jobs, especially scaling them
up and down. The following is an example of an IPUJob
specification that emulates inference serving by running sleep
infinity.
apiVersion: graphcore.ai/v1alpha1
kind: IPUJob
metadata:
name: mnist-inference
spec:
jobInstances: 1
ipusPerJobInstance: "1"
workers:
template:
spec:
containers:
- name: mnist-inference
image: graphcore/pytorch-tutorials:3.0.0
command: ["sleep", "infinity"]
Download mnist-inference-ipujob.yaml
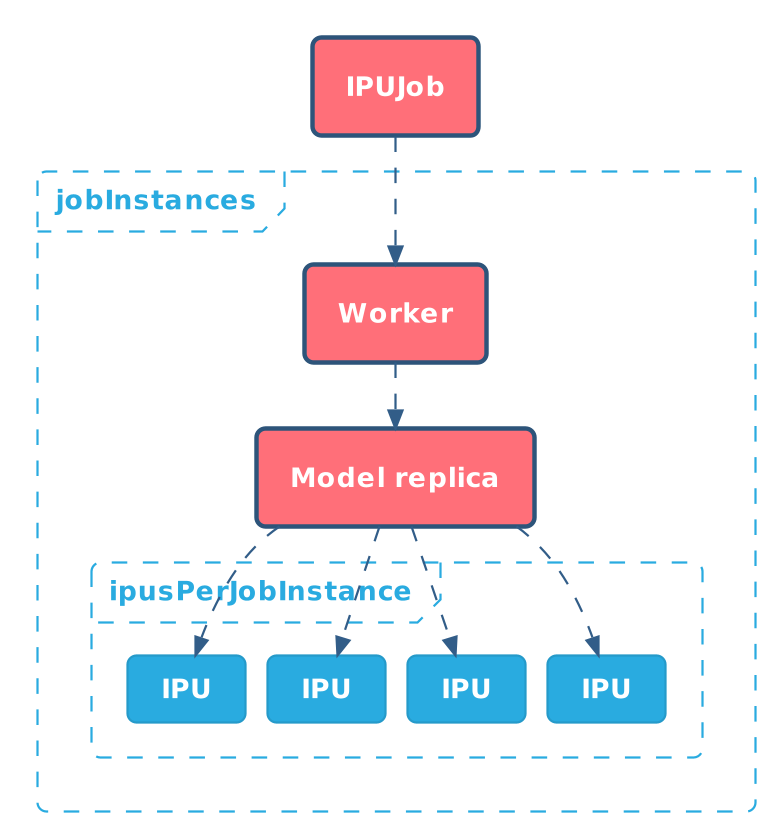
A critical field from the inference perspective is jobInstances
field. It can be used to scale down or scale up the number of Worker Pods that
serve inference requests. When the kubectl scale command is used it changes the
value of this field.
Save the above specification as mnist-inference-ipujob.yaml, then run:
$ kubectl apply -f mnist-inference-ipujob.yaml
ipujob.graphcore.ai/mnist-inference created
Now, you can inspect what happens in the cluster and you should see something similar to:
$ kubectl get pods,ipujobs
NAME READY STATUS RESTARTS AGE
pod/ipu-operator-controller-manager-6dc5cb7976-vlj72 2/2 Running 0 117m
pod/ipu-operator-vipu-proxy-669d7fd755-jh4hl 1/1 Running 0 5d17h
pod/mnist-inference-worker-0 1/1 Running 0 11s
NAME STATUS CURRENT DESIRED LASTMESSAGE AGE
ipujob.graphcore.ai/mnist-inference Running 1 1 All instances are running 17s
4.2.1. Scale up or down operations
To scale up the number of Worker instances to 2, run the following command:
$ kubectl scale ipujob/mnist-inference --replicas 2
ipujob.graphcore.ai/mnist-inference scaled
$ kubectl get pods,ipujobs
NAME READY STATUS RESTARTS AGE
pod/ipu-operator-controller-manager-6dc5cb7976-vlj72 2/2 Running 0 118m
pod/ipu-operator-vipu-proxy-669d7fd755-jh4hl 1/1 Running 0 5d17h
pod/mnist-inference-worker-0 1/1 Running 0 118s
pod/mnist-inference-worker-1 1/1 Running 0 34s
NAME STATUS CURRENT DESIRED LASTMESSAGE AGE
ipujob.graphcore.ai/mnist-inference Running 2 2 All instances are running 2m4s
Note that now there are two Pods (mnist-inference-worker-0 and
mnist-inference-worker-1) and CURRENT and DESIRED Pod
counters in mnist-inference IPUJob have grown from 1 to 2.
Let’s scale further to 4 job instances:
$ kubectl scale ipujob/mnist-inference --replicas 4
ipujob.graphcore.ai/mnist-inference scaled
$ kubectl get pods,ipujobs
NAME READY STATUS RESTARTS AGE
pod/ipu-operator-controller-manager-6dc5cb7976-vlj72 2/2 Running 0 122m
pod/ipu-operator-vipu-proxy-669d7fd755-jh4hl 1/1 Running 0 5d17h
pod/mnist-inference-worker-0 1/1 Running 0 5m28s
pod/mnist-inference-worker-1 1/1 Running 0 4m4s
pod/mnist-inference-worker-2 1/1 Running 0 14s
pod/mnist-inference-worker-3 1/1 Running 0 14s
NAME STATUS CURRENT DESIRED LASTMESSAGE AGE
ipujob.graphcore.ai/mnist-inference Running 4 4 All instances are running 5m34s
As you can see, the number of Pods has grown to 4.
And now let’s scale down the number of job instances to 1, by running the following command:
$ kubectl scale ipujob/mnist-inference --replicas 1
ipujob.graphcore.ai/mnist-inference scaled
$ kubectl get pods,ipujobs
NAME READY STATUS RESTARTS AGE
pod/ipu-operator-controller-manager-6dc5cb7976-vlj72 2/2 Running 0 124m
pod/ipu-operator-vipu-proxy-669d7fd755-jh4hl 1/1 Running 0 5d17h
pod/mnist-inference-worker-0 1/1 Running 0 7m14s
NAME STATUS CURRENT DESIRED LASTMESSAGE AGE
ipujob.graphcore.ai/mnist-inference Running 1 1 All instances are running 7m20s
Scaled down to 1.
4.3. Automatic restarts
You may want your IPUJob to automatically restart in certain
cases. Currently, we support four types of restart policies which can
be defined under the IPUJob specification in restartPolicy field:
Always– the job will be always restarted when finished regardless of success or failure.OnFailure– the job will only be restarted if it fails regardless of why it failed.Never– the job will never be restarted when finished regardless of success or failure.ExitCode– the job will be restarted only in the event of the prior run having exited with code(s) you specify
The IPU Operator will check these exit codes to determine the behaviour when an error occurs, for example:
1-127 – permanent error, do not restart.
128-255 – retriable error, will restart the job.
An example of an IPUJob with restart policy defined:
apiVersion: graphcore.ai/v1alpha1
kind: IPUJob
metadata:
name: mnist-training
spec:
jobInstances: 1
ipusPerJobInstance: "1"
# IPUJob should be restarted only when the process exits with code between 10 and 20.
# IPUJob is considered as failed after 7 retries.
restartPolicy:
type: ExitCode
exitCodes: "10-20"
backOffLimit: 7
workers:
...
4.4. Clean up resources and IPU partitions
Once the job is finished and is no longer going to be restarted, the
IPU Operator can perform an automatic cleanup to free the Kubernetes
resources that are no longer needed. This can be defined in
cleanPodPolicy under the IPUJob specification. The following values
can be set:
Workers– delete theWorkersonly when the job is finished.All– delete all Pods (LauncherandWorkerPods) and release IPU resources when the job is finished. It is also worth mentioning that if thecleanPodPolicyis set like so, it will take priority over anyrestartPolicy. It means that therestartPolicywill act as if it was set toNever.None– don’t delete any Pods when the job is finished. This is the default setting.
An example of IPUJob with cleanup policy defined:
apiVersion: graphcore.ai/v1alpha1
kind: IPUJob
metadata:
name: mnist-training
spec:
jobInstances: 1
ipusPerJobInstance: "1"
# Only workers should be deleted when the job is finished.
cleanPodPolicy: "Workers"
workers:
...