5. Efficient data batching
By default PopTorch will process the batch_size which you provided to
the poptorch.DataLoader.
When using the other options below, the actual number of samples used per step varies to allow the IPU(s) to process data more efficiently.
However, the effective (mini-)batch size for operations which depend on it (such as batch normalization) will not change. All that changes is how much data is actually sent for a single step.
Note
Failure to use poptorch.DataLoader may result in
accidentally changing the effective batch size for operations which depend on
it, such as batch normalization.
5.1. poptorch.DataLoader
Poptorch provides a thin wrapper around the traditional torch.utils.data.DataLoader
to abstract away some of the batch sizes calculations. If poptorch.DataLoader
is used in a distributed execution environment, it will ensure that each process uses
a different subset of the dataset.
If you set the DataLoader batch_size to more than 1 then each operation
in the model will process that number of elements at any given time.
See below for usage example.
5.2. poptorch.AsynchronousDataAccessor
To reduce host overhead you can offload the data loading process to a
separate thread by specifying mode=poptorch.DataLoaderMode.Async in the
DataLoader constructor. Internally this uses an
AsynchronousDataAccessor. Doing this allows you to reduce
the host/IPU communication overhead by using the time that the IPU is running
to load the next batch on the CPU. This means that when the IPU is finished
executing and returns to host the data will be ready for the IPU to pull in again.
1 opts = poptorch.Options()
2 opts.deviceIterations(device_iterations)
3 opts.replicationFactor(replication_factor)
4
5 loader = poptorch.DataLoader(opts,
6 ExampleDataset(shape=shape,
7 length=num_tensors),
8 batch_size=batch_size,
9 num_workers=num_workers,
10 mode=poptorch.DataLoaderMode.Async)
11
12 poptorch_model = poptorch.inferenceModel(model, opts)
13
14 for it, (data, _) in enumerate(loader):
15 out = poptorch_model(data)
Warning
AsynchronousDataAccessor makes use of the Python
multiprocessing module’s spawn start method. Consequently, the entry point of
a program that uses it must be guarded by a if __name__ == '__main__': block
to avoid endless recursion. The dataset used must also be picklable. For more
information, please see https://docs.python.org/3/library/multiprocessing.html#the-spawn-and-forkserver-start-methods.
Warning
Tensors being iterated over using an
AsynchronousDataAccessor use shared memory. You must clone
tensors at each iteration if you wish to keep their references outside of each
iteration.
Consider the following example:
predictions, labels = [], []
for data, label in dataloader:
predictions += poptorch_model(data)
labels += label
The predictions list will be correct because it’s producing a new tensor from the
inputs. However, The list labels will contain identical references. This line
would need to be replaced with the following:
labels += label.detach().clone()
5.3. poptorch.Options.deviceIterations
If you set deviceIterations() to more
than 1 then you are telling PopART to execute that many batches in sequence.
Essentially, it is the equivalent of launching the IPU in a loop over that number of batches. This is efficient because that loop runs on the IPU directly.
1from functools import reduce
2from operator import mul
3
4import torch
5import poptorch
6
7
8class ExampleModelWithLoss(torch.nn.Module):
9 def __init__(self, data_shape, num_classes):
10 super().__init__()
11
12 self.fc = torch.nn.Linear(reduce(mul, data_shape), num_classes)
13 self.loss = torch.nn.CrossEntropyLoss()
14
15 def forward(self, x, target=None):
16 reshaped = x.reshape([x.shape[0], -1])
17 fc = self.fc(reshaped)
18
19 if target is not None:
20 return fc, self.loss(fc, target)
21 return fc
22
23
24class ExampleDataset(torch.utils.data.Dataset):
25 def __init__(self, shape, length):
26 super().__init__()
27 self._shape = shape
28 self._length = length
29
30 self._all_data = []
31 self._all_labels = []
32
33 torch.manual_seed(0)
34 for _ in range(length):
35 label = 1 if torch.rand(()) > 0.5 else 0
36 data = torch.rand(self._shape) + label
37 data[0] = -data[0]
38 self._all_data.append(data)
39 self._all_labels.append(label)
40
41 def __len__(self):
42 return self._length
43
44 def __getitem__(self, index):
45 return self._all_data[index], self._all_labels[index]
46
47
48def example():
49 # Set the batch size in the conventional sense of being the size that
50 # runs through an operation in the model at any given time
51 model_batch_size = 2
52
53 # Create a poptorch.Options instance to override default options
54 opts = poptorch.Options()
55
56 # Run a 100 iteration loop on the IPU, fetching a new batch each time
57 opts.deviceIterations(100)
58
59 # Set up the DataLoader to load that much data at each iteration
60 training_data = poptorch.DataLoader(opts,
61 dataset=ExampleDataset(shape=[3, 2],
62 length=10000),
63 batch_size=model_batch_size,
64 shuffle=True,
65 drop_last=True)
66
67 model = ExampleModelWithLoss(data_shape=[3, 2], num_classes=2)
68 # Wrap the model in a PopTorch training wrapper
69 poptorch_model = poptorch.trainingModel(model, options=opts)
70
71 # Run over the training data with "batch_size" 200 essentially.
72 for batch_number, (data, labels) in enumerate(training_data):
73 # Execute the device with a 100 iteration loop of batchsize 2.
74 # "output" and "loss" will be the respective output and loss of the final
75 # batch (the default AnchorMode).
76
77 output, loss = poptorch_model(data, labels)
78 print(f"{labels[-1]}, {output}, {loss}")
5.4. poptorch.Options.replicationFactor
replicationFactor() will replicate the model over
multiple IPUs to allow automatic data parallelism across many IPUs.
1 # Create a poptorch.Options instance to override default options
2 opts = poptorch.Options()
3
4 # Run a 100 iteration loop on the IPU, fetching a new batch each time
5 opts.deviceIterations(100)
6
7 # Duplicate the model over 4 replicas.
8 opts.replicationFactor(4)
9
10 training_data = poptorch.DataLoader(opts,
11 dataset=ExampleDataset(shape=[3, 2],
12 length=100000),
13 batch_size=model_batch_size,
14 shuffle=True,
15 drop_last=True)
16
17 model = ExampleModelWithLoss(data_shape=[3, 2], num_classes=2)
18 # Wrap the model in a PopTorch training wrapper
19 poptorch_model = poptorch.trainingModel(model, options=opts)
20
21 # Run over the training data with "batch_size" 200 essentially.
22 for batch_number, (data, labels) in enumerate(training_data):
23 # Execute the device with a 100 iteration loop of batchsize 2 across
24 # 4 IPUs. "output" and "loss" will be the respective output and loss of the
25 # final batch of each replica (the default AnchorMode).
26 output, loss = poptorch_model(data, labels)
27 print(f"{labels[-1]}, {output}, {loss}")
5.5. poptorch.Options.Training.gradientAccumulation
You need to use
gradientAccumulation()
when training with pipelined models because the weights are shared across
pipeline batches so gradients will be both updated and used by subsequent
batches out of order.
Note gradientAccumulation()
is only needed by poptorch.PipelinedExecution.
See also poptorch.Block.
1 # Create a poptorch.Options instance to override default options
2 opts = poptorch.Options()
3
4 # Run a 100 iteration loop on the IPU, fetching a new batch each time
5 opts.deviceIterations(400)
6
7 # Accumulate the gradient 8 times before applying it.
8 opts.Training.gradientAccumulation(8)
9
10 training_data = poptorch.DataLoader(opts,
11 dataset=ExampleDataset(shape=[3, 2],
12 length=100000),
13 batch_size=model_batch_size,
14 shuffle=True,
15 drop_last=True)
16
17 # Wrap the model in a PopTorch training wrapper
18 poptorch_model = poptorch.trainingModel(model, options=opts)
19
20 # Run over the training data with "batch_size" 200 essentially.
21 for batch_number, (data, labels) in enumerate(training_data):
22 # Execute the device with a 100 iteration loop of batchsize 2 across
23 # 4 IPUs. "output" and "loss" will be the respective output and loss of the
24 # final batch of each replica (the default AnchorMode).
25 output, loss = poptorch_model(data, labels)
26 print(f"{labels[-1]}, {output}, {loss}")
In the code example below, poptorch.Block introduced in
poptorch.isRunningOnIpu is used to divide up
a different model into disjoint subsets of layers.
These blocks can be shared among multiple parallel execution strategies.
1class Network(nn.Module):
2 def __init__(self):
3 super(Network, self).__init__()
4 self.layer1 = nn.Linear(784, 784)
5 self.layer2 = nn.Linear(784, 784)
6 self.layer3 = nn.Linear(784, 128)
7 self.layer4 = nn.Linear(128, 10)
8 self.softmax = nn.Softmax(1)
9
10 def forward(self, x):
11 x = x.view(-1, 784)
12 with poptorch.Block("B1"):
13 x = self.layer1(x)
14 with poptorch.Block("B2"):
15 x = self.layer2(x)
16 with poptorch.Block("B3"):
17 x = self.layer3(x)
18 with poptorch.Block("B4"):
19 x = self.layer4(x)
20 x = self.softmax(x)
21 return x
22
23
24class TrainingModelWithLoss(torch.nn.Module):
25 def __init__(self, model):
26 super().__init__()
27 self.model = model
28 self.loss = torch.nn.CrossEntropyLoss()
29
30 def forward(self, args, loss_inputs=None):
31 output = self.model(args)
32 if loss_inputs is None:
33 return output
34 with poptorch.Block("B4"):
35 loss = self.loss(output, loss_inputs)
36 return output, loss
37
38
You can see the code examples of poptorch.SerialPhasedExecution,
poptorch.PipelinedExecution, and
poptorch.ShardedExecution below.
An instance of class poptorch.PipelinedExecution defines an
execution strategy that assigns layers to multiple IPUs as a pipeline. Gradient
accumulation is used to push multiple batches through the pipeline allowing
IPUs to run in parallel.
1 training_data, test_data = get_mnist_data(opts)
2 model = Network()
3 model_with_loss = TrainingModelWithLoss(model)
4 model_opts = poptorch.Options().deviceIterations(1)
5 if opts.strategy == "phased":
6 strategy = poptorch.SerialPhasedExecution("B1", "B2", "B3", "B4")
7 strategy.stage("B1").ipu(0)
8 strategy.stage("B2").ipu(0)
9 strategy.stage("B3").ipu(0)
10 strategy.stage("B4").ipu(0)
11 model_opts.setExecutionStrategy(strategy)
12 elif opts.strategy == "pipelined":
13 strategy = poptorch.PipelinedExecution("B1", "B2", "B3", "B4")
14 strategy.stage("B1").ipu(0)
15 strategy.stage("B2").ipu(1)
16 strategy.stage("B3").ipu(2)
17 strategy.stage("B4").ipu(3)
18 model_opts.setExecutionStrategy(strategy)
19 model_opts.Training.gradientAccumulation(opts.batches_per_step)
20 else:
21 strategy = poptorch.ShardedExecution("B1", "B2", "B3", "B4")
22 strategy.stage("B1").ipu(0)
23 strategy.stage("B2").ipu(0)
24 strategy.stage("B3").ipu(0)
25 strategy.stage("B4").ipu(0)
26 model_opts.setExecutionStrategy(strategy)
27
28 if opts.offload_opt:
29 model_opts.TensorLocations.setActivationLocation(
30 poptorch.TensorLocationSettings().useOnChipStorage(True))
31 model_opts.TensorLocations.setWeightLocation(
32 poptorch.TensorLocationSettings().useOnChipStorage(True))
33 model_opts.TensorLocations.setAccumulatorLocation(
34 poptorch.TensorLocationSettings().useOnChipStorage(True))
35 model_opts.TensorLocations.setOptimizerLocation(
36 poptorch.TensorLocationSettings().useOnChipStorage(False))
37
38 training_model = poptorch.trainingModel(
39 model_with_loss,
40 model_opts,
41 optimizer=optim.AdamW(model.parameters(), lr=opts.lr))
42
43 # run training, on IPU
44 train(training_model, training_data, opts)
Fig. 5.1 shows the pipeline execution for multiple batches on IPUs. There are 4 pipeline stages running on 4 IPUs respectively. Gradient accumulation enables us to keep the same number of pipeline stages, but with a wider pipeline. This helps hide the latency, which is the total time for one item to go through the whole system, as highlighted.
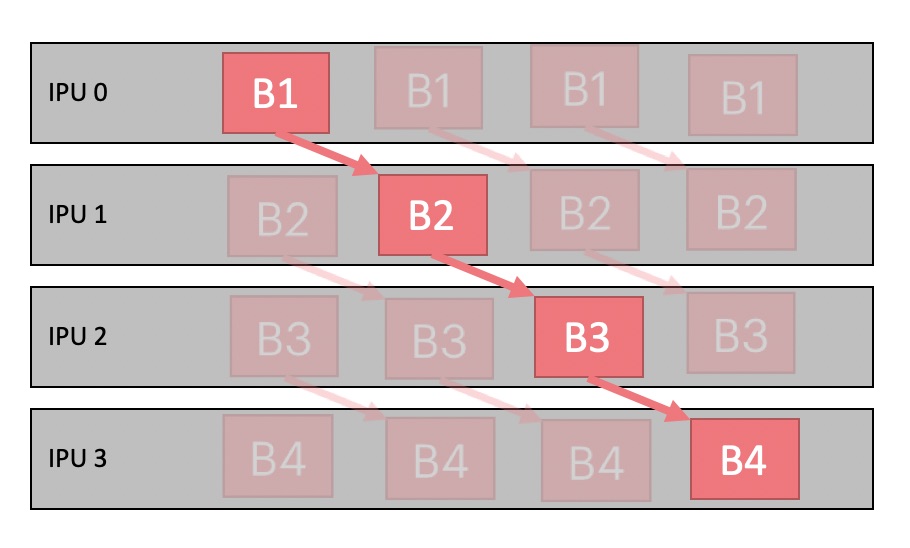
Fig. 5.1 Pipeline execution with gradient accumulation