Sharding: a model parallel approach
A commonly used technique for porting models to the IPU is sharding, which is a concept derived from the model parallel paradigm where the same graph is segregated into separate components, or shards, and deployed to separate compute threads. In the current context, the graph is deployed to separate IPUs. Models that oversubscribe the memory of a single IPU can be deployed to multiple IPUs by breaking the network into smaller components and then communicating output activations of one shard to the input tensors of another shard.
The diagram below is taken from the Targeting the IPU from TensorFlow guide:
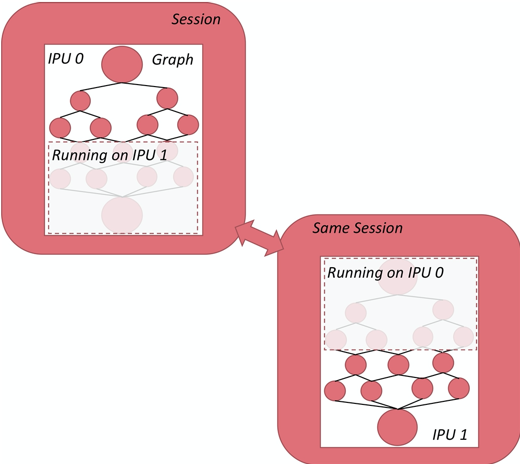
The sharding concept
There are a number of ways to conduct sharding, and the Targeting the IPU from
TensorFlow guide should be the first point of reference. Given here is a very
abridged code example based on the script simple_sharding.py from
Graphcore’s examples repository on GitHub. It presents a manual and automatic
sharding code example:
from tensorflow.python.ipu import autoshard
...
# With sharding all placeholders MUST be explicitly placed on the CPU device:
with tf.device("cpu"):
pa = tf.placeholder(np.float32, [2], name="a")
pb = tf.placeholder(np.float32, [2], name="b")
pc = tf.placeholder(np.float32, [2], name="c")
# Put part of the computation on shard 1 and part on shard 2 for manual sharding
def manual_sharding(pa, pb, pc):
with scopes.ipu_shard(0):
o1 = pa + pb
with scopes.ipu_shard(1):
o2 = pa + pc
out = o1 + o2
return out
# Use autosharding to determine the points to best split up a network
def auto_sharding(pa, pb, p c):
with autoshard.ipu_autoshard():
o1 = pa + pb
o2 = pa + pc
out = o1 + o2
return out
def my_graph(pa, pb, pc):
with tf.device("/device:IPU:0"):
if opts.autoshard:
result = auto_sharding(pa, pb, pc)
else:
result = manual_sharding(pa, pb, pc)
return result
...
cfg = utils.auto_select_ipus(cfg, NUMBER_OF_SHARDS)
As can be seen from the code sample, in the manual sharding example, the graph
is segregated by using the scopes.ipu_shard calls at the splice points in
the graph. In the automatic sharding example, the graph as a whole is fed to
the ipu_autoshard function and the API handles the splicing of the graph.
Please refer to the simple_sharding.py script for further details of
implementation.
Limitations of sharding
Sharding technology simply partitions the model and distributes it on multiple IPUs. Multiple shards execute in series and cannot fully utilise the computing resources of the IPUs. As shown in the figure below, the model is partitioned into four parts and executed on four IPUs in series. Only one IPU is working at any one time.

Sharding profile
Sharding is a valuable method for use cases that need more control with replication, for example random forests, federated averaging and co-distillation. It can also be useful when developing/debugging a model, however for best performance pipelining should be used in most cases.