2. Sharding
Sharding means partitioning a neural network, represented as a computational graph, across multiple IPUs, each of which computes a certain part of this graph.
For example, we plan to train a model on an IPU-POD16 DA that has four IPU-M2000s and 16 IPUs. As shown in Fig. 2.1, the model we are training has 32 layers, which cannot fit in one IPU. Logically, we shard the model into 16 subgraphs across the IPUs, where each IPU computes two subgraphs. The direction of the arrows indicates the computation process of the entire model. IPUs communicate with each other through IPU-Links, with bidirectional bandwidth of 64 GB/s.
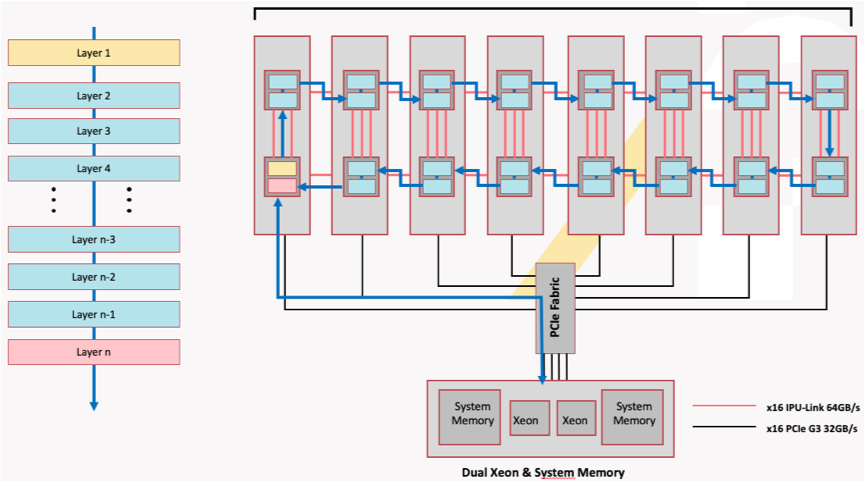
Fig. 2.1 Model sharding over 16 IPUs
Note
The number of IPUs that a model is split over must be a power of 2.
Fig. 2.2 shows how we shard a neural network that is implemented in TensorFlow. Even though this model is evenly partitioned across two IPUs and each subgraph can only be visible to its assigned IPU, these two subgraphs are encapsulated within the same session instance and therefore can be trained in a distributed manner.
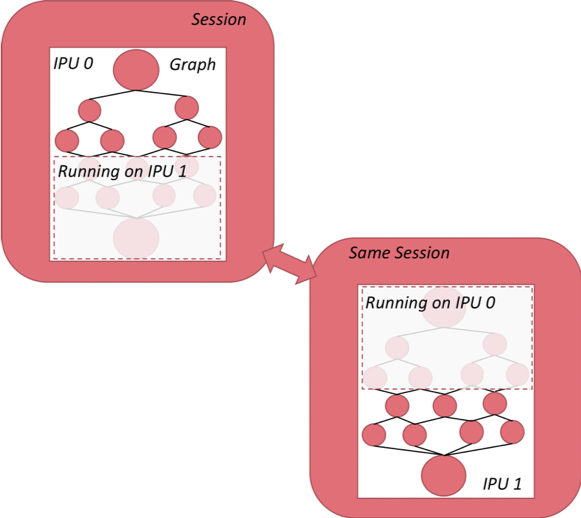
Fig. 2.2 Graph sharding with TensorFlow
Shown on the left in Fig. 2.3 is the computational graph we would like to execute. Let’s say we assign a part of the graph (P0, P1, P2, P3) to the CPU, and partition the rest into two shards across two IPUs. The original computational graph (shown on the left) is transformed into the graph on the right. When the variables required for computation in TensorFlow are distributed on different types of TensorFlow devices (such as CPU and IPU), TensorFlow will add Send and Recv nodes to the graph. If we use sharding, copy nodes will be added between pairs of IPU shards to exchange variables. Copy nodes are implemented with IPU-Link technology.
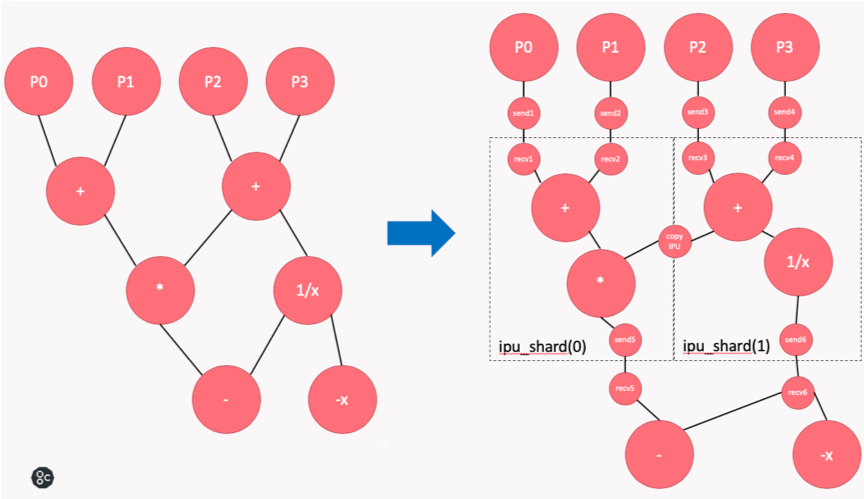
Fig. 2.3 Graph transformation with sharding
2.1. Graph sharding
We provide an API for manual graph sharding, allowing you to arbitrarily designate sharding points of the graph to achieve maximum flexibility.
2.1.1. API
The manual model sharding API:
tensorflow.python.ipu.scopes.ipu_shard(index)
Model sharding of a group of operations.
Parameters:
index: IPU index indicates which IPU the operation group is partitioned onto.
2.1.2. Code example
A code example is shown in Listing 2.1 for TensorFlow 1 (download source code):
1# Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2
3import numpy as np
4import tensorflow.compat.v1 as tf
5from tensorflow.python import ipu
6from tensorflow.python.ipu.scopes import ipu_scope
7
8tf.disable_v2_behavior()
9
10NUM_IPUS = 4
11
12# Configure the IPU system
13cfg = ipu.config.IPUConfig()
14cfg.auto_select_ipus = NUM_IPUS
15cfg.configure_ipu_system()
16
17# Create the CPU section of the graph
18with tf.device("cpu"):
19 pa = tf.placeholder(np.float32, [2], name="a")
20 pb = tf.placeholder(np.float32, [2], name="b")
21 pc = tf.placeholder(np.float32, [2], name="c")
22
23
24# Distribute the computation across four shards
25def sharded_graph(pa, pb, pc):
26 with ipu.scopes.ipu_shard(0):
27 o1 = pa + pb
28 with ipu.scopes.ipu_shard(1):
29 o2 = pa + pc
30 with ipu.scopes.ipu_shard(2):
31 o3 = pb + pc
32 with ipu.scopes.ipu_shard(3):
33 out = o1 + o2 + o3
34 return out
35
36
37# Create the IPU section of the graph
38with ipu_scope("/device:IPU:0"):
39 result = ipu.ipu_compiler.compile(sharded_graph, [pa, pb, pc])
40
41with tf.Session() as sess:
42 # sharded run
43 result = sess.run(
44 result, feed_dict={pa: [1.0, 1.0], pb: [0.0, 1.0], pc: [1.0, 5.0]}
45 )
46 print(result)
auto_select_ipus on line 12 selects four independent IPUs for this task. The selected IPUs are automatically chosen from the idle IPUs available to the system when the IPUConfig instance is used to configure the IPU system. sharded_graph() on lines 22-31 defines a simple graph that consists of some simple additions. Most importantly, the entire graph is partitioned into four shards by calling the ipu.scopes.ipu_shard() API four times.
2.2. Limitations of sharding
Sharding simply partitions the model and distributes it on multiple IPUs. Multiple shards execute in series and cannot fully utilise the computing resources of the IPUs. As shown in Fig. 2.4, the model is partitioned into four parts and executed on four IPUs in series. Only one IPU is working at any one time.

Fig. 2.4 Sharding profile
Sharding is a valuable method for use cases that need more control with replication, for example random forests, federated averaging and co-distillation. It can also be useful when developing or debugging a model, however for best performance pipelining should be used in most cases.