2. IPU Inference Toolkit architecture
This chapter introduces the Graphcore software stack and describes the model compilation and model runtime aspects of the IPU Inference Toolkit architecture.
2.1. Model servers
Usually, a model server, like Triton Inference Server and TensorFlow Serving is used to deploy a trained model. When a client sends inputs for inference, the model server passes the inputs to the model.
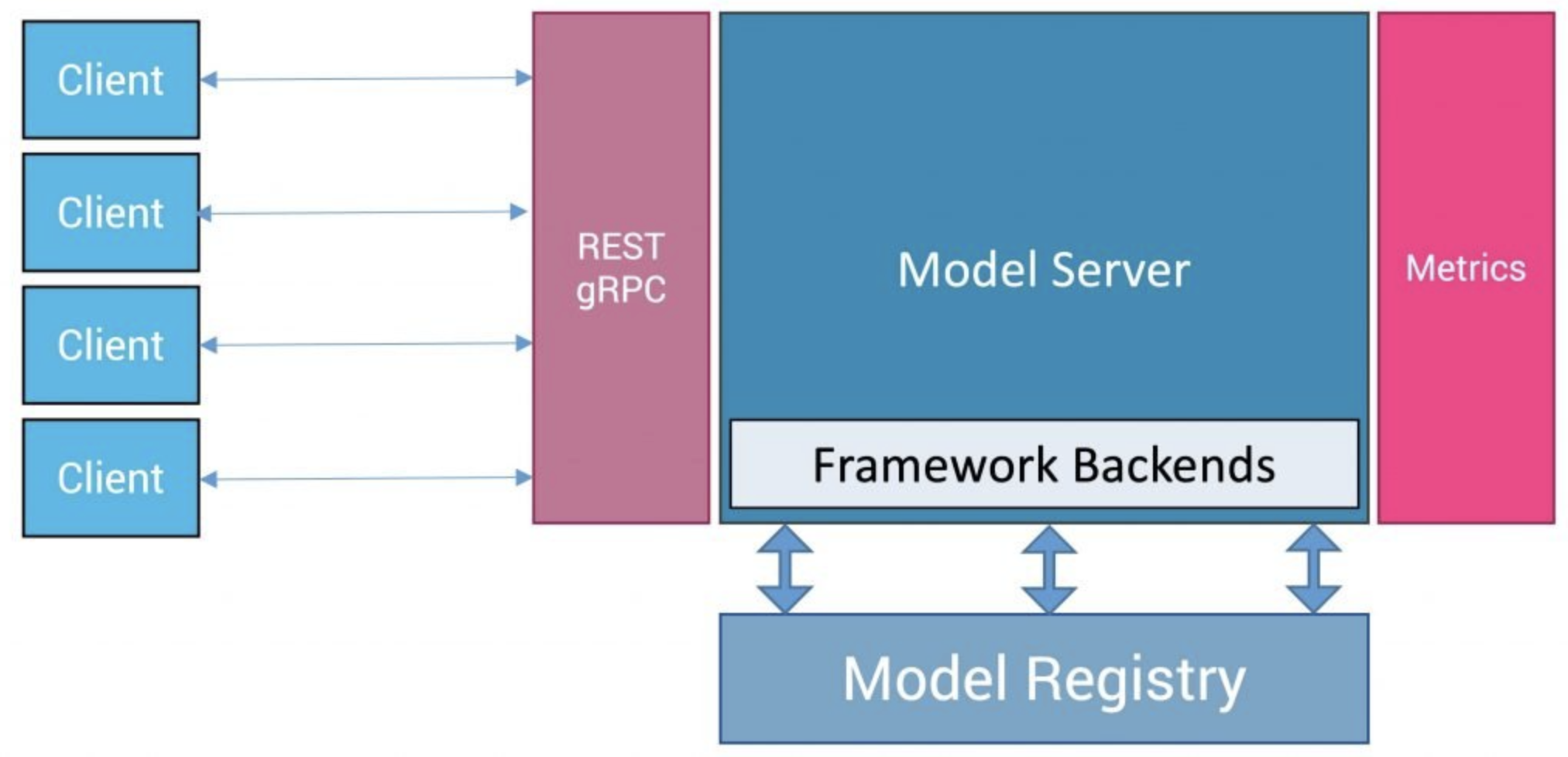
Fig. 2.1 Model Serving Overview
Model servers usually provide HTTP REST or gRPC interfaces for front-end applications. In the model server framework, functions such as model management, request management, data monitoring and data tracking are generally available, and the requests are distributed to the corresponding machine learning framework and hardware through the framework back-end for inference. In the current open source market, there are various model servers.
In the IPU Inference Toolkit, the Triton Inference Server and TensorFlow Serving model servers are supported. In addition, the Poplar Exchange Format (PopEF) and PopRT allow for easy integration with various model servers or machine learning frameworks.
2.2. Graphcore Poplar software stack
The Graphcore Poplar software stack (Fig. 2.2), provides multiple levels of programming interfaces. You can develop or run models using the APIs of familiar machine learning frameworks, or directly develop more efficient operators for the IPU with the Poplar API. The model will be compiled with the Poplar graph compiler and run on the IPU on the Poplar graph engine. To learn more about IPU programming, refer to the IPU Programmer’s Guide.
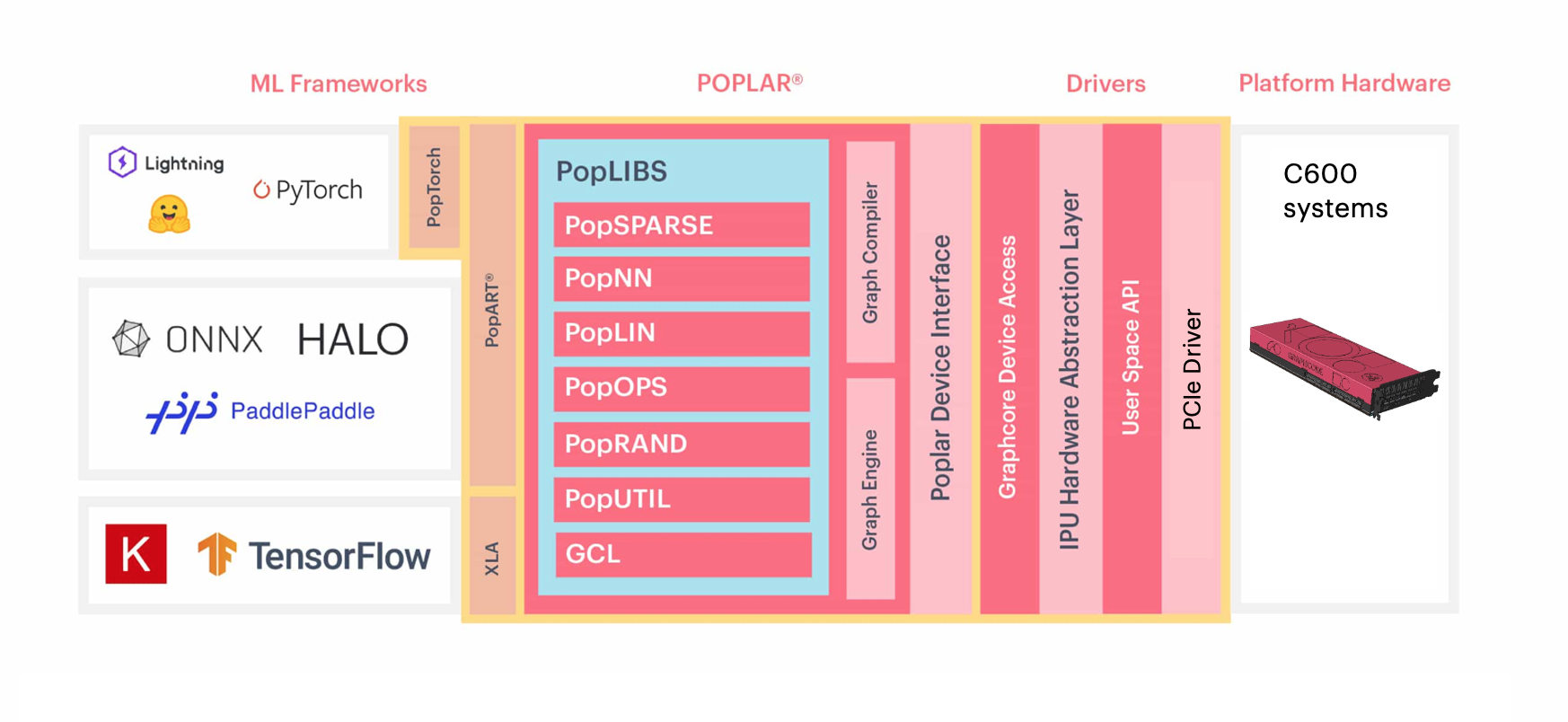
Fig. 2.2 Poplar software stack
2.2.1. PopART
The Poplar Advanced Run Time (PopART) is the ONNX-based machine learning framework included in the Poplar SDK. PopART can be used to build and train models, as well as load and run ONNX models from other machine learning frameworks. For more information about PopART refer to the PopART User Guide.
2.2.2. PopEF and PopRT Runtime
The Poplar Exchange Format (PopEF) is a unified file format included in the Poplar SDK for importing and exporting models. PopEF contains the binary code compiled by the Poplar compiler that can be run on the IPU, the input and output of the model, and the hardware information required to run the model. For more information about PopEF refer to the PopEF: User Guide.
PopRT Runtime is a runtime environment for loading and running PopEF models. It provides different levels of API to quickly load and run PopEF models, as well as easy and flexible integration with model server frameworks or machine learning frameworks.
2.3. Using the IPU Inference Toolkit
As shown in Fig. 2.3, preparing models for inference on an IPU is divided into two phases:
The model compilation phase compiles the model into a PopEF file, while the model runtime phase is responsible for loading and running the PopEF model generated in the compilation phase.
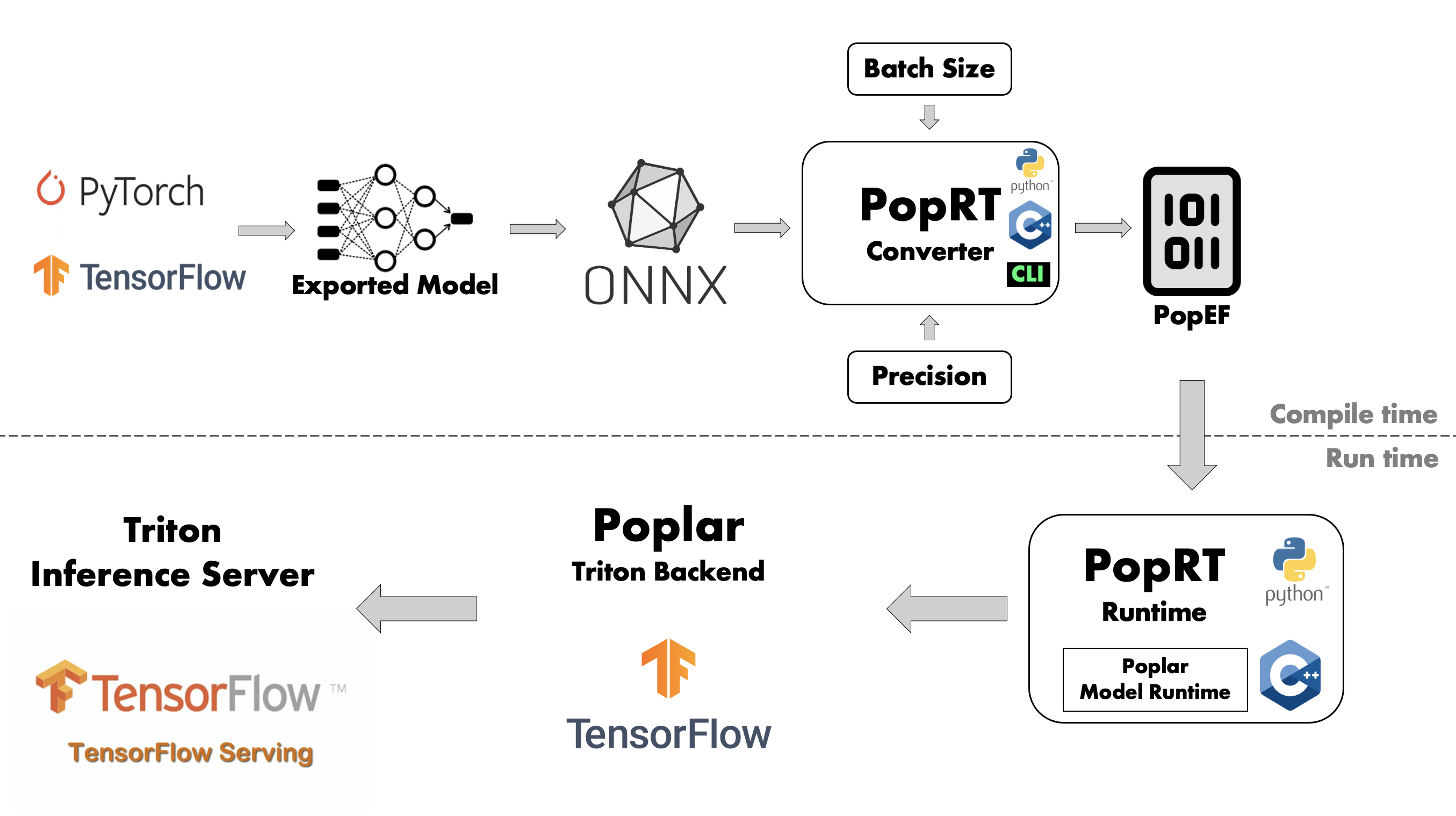
Fig. 2.3 Workflow to prepare a trained model for deployment on a system using IPUs for inference
2.3.1. Model compilation overview
Model compilation is the process of compiling a deployable model into PopEF so that the model can be run on the IPU. Model compilation (Fig. 2.4) includes model export, batch size selection, precision selection, model conversion and compilation.
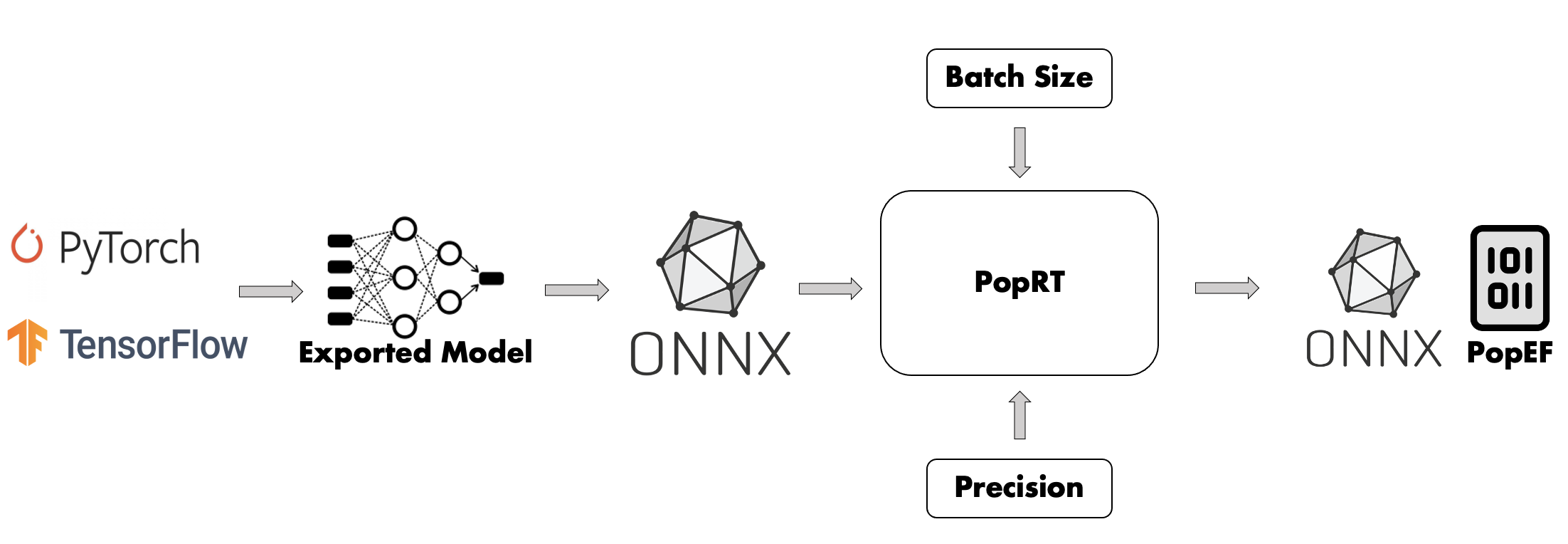
Fig. 2.4 Model compilation
Examples of compiling models in the different frameworks are presented in Section 4, Model compilation.
Model export
There are various machine learning frameworks, such as PyTorch, TensorFlow and PaddlePaddle, and each of them has their own format for exporting models between frameworks, such as the PyTorch pt format, the TensorFlow SavedModel format and the PaddlePaddle pdmodel format. ONNX provides a bridge for model conversion between frameworks. Most frameworks contain a method to convert their model format to ONNX – either provided by the framework or written by the ONNX community. For example use tf2onnx to convert a SavedModel model to ONNX. Full details of model conversion to ONNX are described in Section 4, Model compilation.
The model conversion tool PopRT in the IPU Inference Toolkit will accept an ONNX model as input, and after a series of conversion and optimisation steps, will return the ONNX model that can be compiled and run using PopART. The model conversion tool then compiles the ONNX model into a PopEF file.
Batch size selection
You need to specify the value of the batch size in the compilation phase. Generally, a small batch size means a lower latency, and a large batch size means a higher throughput. You need to determine the batch size according to the application requirements.
Since the IPU only supports static graphs, if the model input has other dynamic dimensions besides the batch size, these dimensions also need to be determined in the compilation phase.
Precision selection
You need to specify the precision that the model will adopt in the compilation phase. The IPU can achieve higher performance on float16 while maintaining the same accuracy as float32. Therefore, float16 shall be used for the precision of the model as much as possible, and float32 shall be used only when float16 does not meet the precision requirements.
Model conversion
Model conversion is the process of converting the ONNX model exported by users into an ONNX model that can be run on PopART. Model conversion also makes a series of optimisations to the model. The optimisations include general optimisations and optimisations for IPU features. For more information about model conversion and optimisation, refer to the PopRT documentation.
Model compilation
Model compilation is a process in which the ONNX model obtained by model conversion is exported to a PopEF file after being compiled by the PopART framework and Poplar compiler.
2.3.2. Model runtime overview
The PopEF file generated by model compilation can be run in three ways:
- PopRT Runtime API
The PopRT Runtime provides Python and C++ APIs, which can quickly run models or integrate with deep learning frameworks and model servers. For more information, refer to the PopRT documentation.
- Triton Inference Server
Graphcore implements a Poplar Triton Backend plug-in with the Poplar Model Runtime API, so as to deploy PopEF models to the Triton Inference Server. For more information, refer to the Poplar Triton Backend: User Guide.
- TensorFlow Serving
The Poplar Model Runtime API is used to write a TensorFlow custom op which handles the loading and running of PopEF models. Then, the compiled PopEF model can be deployed with TensorFlow Serving. For more information, refer to the Poplar Model Runtime documentation.
Examples of deploying and running models on different model servers are presented in Section 5, Model runtime.