6. NLP 端到端在线搜索解决方案
6.1. 引言
在今天的信息时代,人们对于在线搜索的需求越来越高,从搜索引擎中获取信息、与智能助理进行语义交互、在社交媒体上进行实时搜索等已经成为日常生活中的常见场景。 而这些在线搜索场景中,自然语言处理(NLP)技术发挥着重要作用。NLP不仅需要处理海量的文本数据,还需要深入理解复杂的语义信息,以满足用户的查询需求。 然而,NLP在线搜索面临着诸多挑战,如实时性要求、动态batch等。 为了解决这些问题,硬件厂商积极研发创新的解决方案,包括模型转换、推理服务和监控系统等,以提高NLP在线搜索的性能和效果。
Graphcore为NLP在线搜索等领域提供高效、高性能的解决方案。 通过使用PopRT工具,用户可以将自然语言处理模型优化并部署到 Graphcore IPU 上,充分发挥其强大的计算能力,从而实现在NLP在线搜索场景中的高性能推理。 同时,Graphcore通过提供丰富的模型转换、推理服务和监控系统等支持,帮助用户在NLP在线搜索中取得卓越的性能和效果。
6.2. NLP在线搜索的应用场景
NLP(自然语言处理)在线搜索应用广泛,涵盖了多个领域。在传统的搜索引擎中,NLP技术被应用于谷歌、百度等搜索引擎,用户可以通过输入自然语言查询来搜索网页、新闻、图片、视频等信息。 此外,NLP在线搜索还在语义搜索、智能助理、社交媒体搜索、企业内部搜索以及问答系统等领域得到了广泛应用。 通过NLP技术,搜索引擎可以实现更加精准的语义搜索,理解查询的语义含义,而不仅仅是关键词匹配。 智能助理,如Siri、Alexa、小度等,也借助NLP在线搜索技术,实现了用户通过语音或文字与智能助理进行自然语言交互,获取天气、新闻、日历、路线等信息的功能。 同时,社交媒体平台如Twitter、微博等也应用了NLP在线搜索,用户可以通过输入自然语言查询来搜索关注的话题、用户、标签等信息。 在企业内部,NLP在线搜索可用于知识管理和信息检索,帮助员工查找和获取企业内部的文档、报告、资料等信息。 另外,NLP在线搜索还可以用于问答系统,帮助用户通过自然语言查询获取问题的答案,例如在线客服、知识图谱等。 随着NLP技术的不断发展和应用的深入,未来可能会涌现出更多新的应用场景。
6.3. NLP在线搜索的一些挑战和问题
随着互联网的发展,NLP在线搜索在信息检索、智能客服、社交媒体分析等领域得到了广泛应用。然而,传统的NLP模型在处理长文本序列时面临着多个挑战:
实时性要求: 在线搜索场景通常需要在实时或接近实时的时间内进行推理处理,以满足用户的实时查询需求。因此,模型的推理性能和响应时间对于在线搜索场景至关重要。
高并发处理: 在线搜索场景可能会涉及到大量的并发请求,需要能够高效地处理多个请求,同时保持良好的推理性能。
模型适配和部署: 将已有的NLP模型适配到在线搜索场景中,并在不同的环境中进行部署和管理,可能需要考虑模型的转换、部署、扩展性和可维护性等方面的问题。
监控和调优: 在线搜索场景中需要对模型进行监控和性能调优,以保障推理性能、稳定性和可靠性,并及时发现和解决潜在的问题。
可扩展性: 在线搜索场景可能需要处理大规模的数据和用户请求,因此需要具备良好的可扩展性,包括在硬件和软件层面的扩展性,以应对未来的业务增长和需求变化。
为了解决这些问题,Graphcore 积极研发创新的解决方案包括模型转换、推理服务和监控系统等,以提高NLP在线搜索的性能和效果.
实时性要求,高并发处理: IPU 包含 1472 个独立处理单元和 8832 个独立线程,每个线程可以并行处理不同任务。 与此同时,采用片上分布式 SRAM 的独特存储架构,将内存分布在每个计算单元中,内存和计算单元耦合在一起极大缩减了内存和计算距离。 提高整体的推理效率,从而满足在线搜索场景的实时性要求。
模型适配和部署: Graphcore 提供了 PopRT 这个模型转换工具可以轻松的将训练好的模型文件直接转换成 IPU 可以运行的模型文件,可以轻松的将模型部署到 IPU 上,从而简化了模型适配和部署的过程。
监控和调优: 提供可以服务镜像并支持开源的 Grafana 和 prometheus 监控系统,可以对 IPU 进行监控和调优,以保障推理性能、稳定性和可靠性,并及时发现和解决潜在的问题。
可扩展性: 在软件层面,Graphcore为 Triton 和 TFserving 提供了 IPU 的后端支持,从而可以轻松的将模型部署到 Kubernetes 集群中,以应对未来的业务增长和需求变化。 在硬件层面,可以通过 IPU-Link 其进行互联扩展,组成更大规模的训练或推理集群。
总之,为了满足NLP在线搜索的高性能和实时性要求,Graphcore研发了许多创新解决方案。 通过强大的IPU芯片、软硬件优化以及完善的监控体系,NLP在线搜索场景提供了高性能、实时且可扩展的端到端解决方案。
6.4. 模型转换
为了解决在线搜索场景中的模型适配和转换问题,并且实现不同NLP模型之间的无缝转换,Graphcore提供了模型转换和优化的工具。 能够将主流的NLP模型,如BERT、RoBERTa、XLNet等转换为统一的IPU芯片的部署格式,在转换过程中自动优化模型以降低延时、提高吞吐。
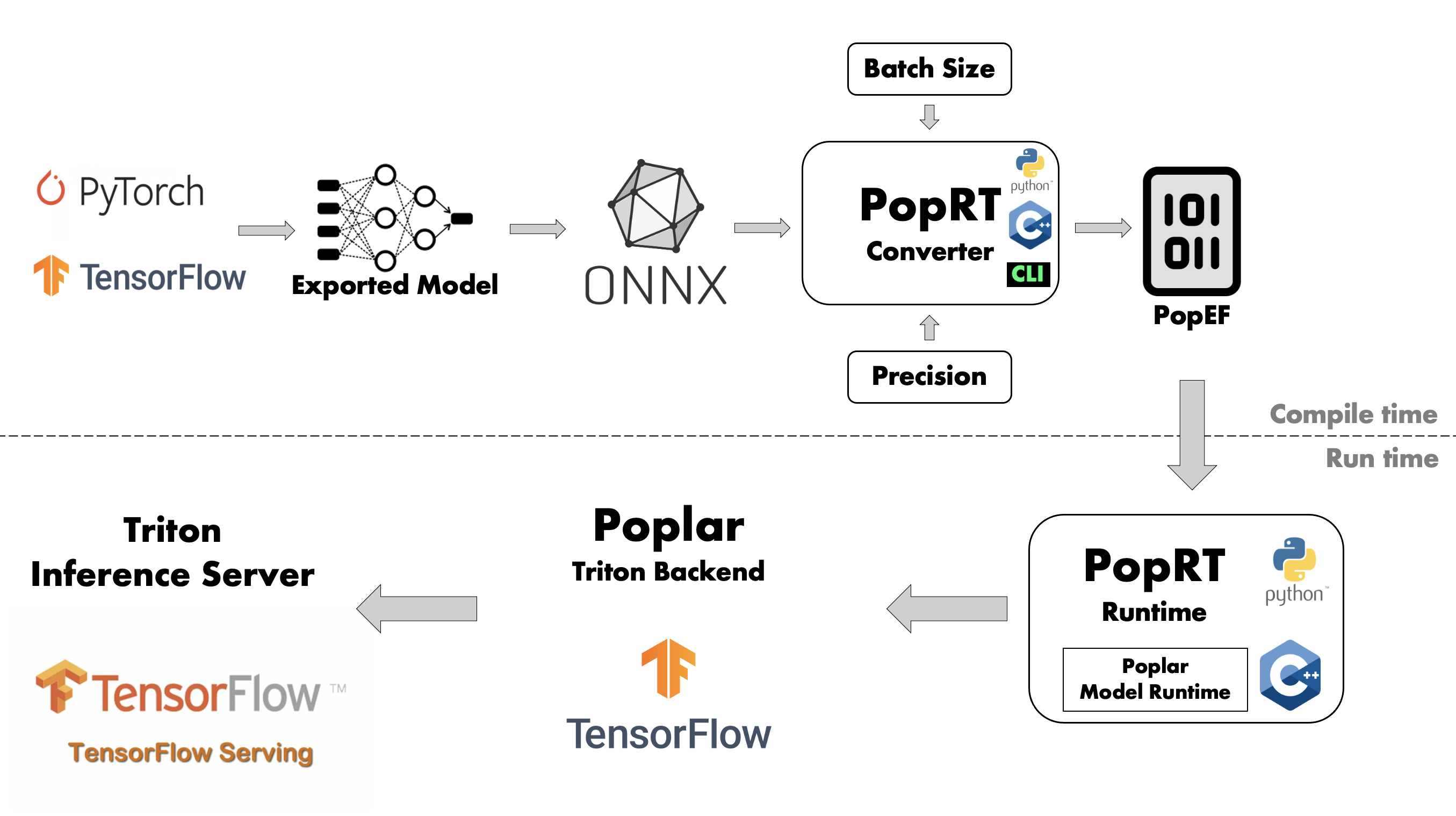
具体来说,模型转换工具首先会针对不同模型的结构和格式进行分析,然后提取其中的模态与权重参数。 在保留模型本质的同时,PopRT 支持将 FP32 模型转换为 FP16 可以将模型大小减小一半,并加速内存读写和提高IPU上的运算速以及降低计算资源占用。 其次,IPU 由于直接加载模型和权重到芯片上,减少了 CPU-IPU 或 CPU-IPU 之间的数据传输,这种设计适合部署在在线模型推理场景上,可以实现快速且低延时的推理。 另外,PopRT 还提供了算子融合(Operator Fusion)和优化功能,可以进一步提高IPU上的推理速度,减少中间数据的存储可以将一些小的矩阵乘法运算优化成更高效的设计等。 经过模型转换工具的优化处理,不同来源的NLP模型以一致的格式被统一部署到开源流行的服务架构上,例如 Triton Server 或者 TFserving。
接下来会以在线搜索领域中常用的开源模型 roberta 为例子,利用 PopRT 将其转换成IPU部署的通用格式 popef。请在有IPU硬件的机器上运行以下流程。
首先,先从 onnx 官方模型库里下载 roberta
其次,拉取 poprt 的官方镜像
运行转换脚本和命令,这里采用
batch_size = 4和sequence_length = 128。
将模型和 popef 文件更改权限组 (非必需项)
6.5. 模型部署
为了进一步增强模型部署的通用性,Graphcore同时支持将优化后的NLP模型部署到TFServing和Triton Server等主流的机器学习模型服务引擎上。
对于 TFserving 和 Triton Server 以上两种Graphcore会提供相对应的IPU版本推理引擎框架的服务镜像。 NLP研究人员和开发者可以通过PopRT工具一键将其模型导出为统一的IPU可执行文件格式 POPEF 格式并将模型部署至两种服务引擎中的任意一种。 这种部署方式不但可以重用现有的服务引擎来进行NLP模型的相关推理,还可以根据具体需求选择更加适合的推理服务框架来部署模型, 以获得更优的性能或更低的成本亦适用于那些对低延迟和高并发有苛刻要求的在线服务场景。
Graphcore 通过支持 Triton Server 的后端和TFServing,使模型部署方案在保留了通用部署能力的同时,又具备了面向低延迟场景的高性能部署选择。 这种同时兼顾通用与高性能的部署系统设计,使服务引擎能更好地满足不同NLP在线服务场景下的部署需求,为NLP模型在更广范围内落地提供了可能。
以下以 Triton Server 为部署服务推理框架, 来将转换之后的 roberta 模型进行部署:
首先,创建一个
config.pbtxt
将上述配置文件拷贝到
models/roberta/与此同时将 popef 文件拷贝到models/roberta/1/
拷贝上述内容到
/model/roberta目录下的config.pbtxt中拉取 Triton Server 镜像
启动 Triton Server 推理服务
6.6. 模型请求和压力测试
为确保线上部署的NLP模型能够稳定高效地服务用户请求,Graphcore提供了模型请求与压力测试功能。这个功能可以生成模拟的模型查询流量和负载, 对正在服务中的NLP模型进行压力测试,并收集模型在高负载条件下的性能指标与问题反馈。
具体来说, 压测程序可以根据历史查询日志自动生成大量模拟请求,这些请求可以伴随真实流量一同发送到目标模型,对模型的并发处理能力和延迟性能进行测试。 同时会实时监控并记录模型在压力测试期间的各项性能数据,如每秒查询数(QPS)、平均延迟(LATENCY)和资源利用率等。
此外,在压力测试过程中还会收集模型推理日志与异常反馈,并进行分析汇总。 这可以帮助研发团队进一步理解模型在高负载下的行为模式与薄弱点,并及时进行模型优化或部署策略调整。 相比于简单的性能抽测,压力测试可以在更显著和全面地暴露出模型生产环境中的各类问题, 这是确保模型稳定性和高可用性的有效手段。通过对正在服务的NLP模型进行模拟请求与有序的压力测试, 可以持续评估和提高模型的并发处理能力与稳定性。这可以最大限度地减少模型在线上发生故障的可能性, 提高其实际在线服务质量。这项功能与监控、报警等其他服务相结合, 有助于NLP模型产业化后快速进入稳定高效的运营状态。
拉取压测镜像
保存以下配置文件到
config.json
启动压测程序
我们可以在 Triton Server 端看到以下输出
6.7. 模型推理服务监控
为全面监控线上部署的NLP模型的运行状态和性能,Graphcore提供了模型服务监控功能。 这个功能可以实时跟踪模型实例的吞吐量和延迟等指标,快速发现模型服务运行过程中的问题,以实现持续稳定的模型运营。
具体来说,Graphcore的模型推理服务兼容开源的监控解决方案 Prometheus 和 Grafana,监控模块可以监控模型的QPS、LATENCY和任务错误率等性能指标, 更加精准地捕捉模型性能的异常变化。
Prometheus是一款开源的监控报警系统和时序数据库。模型推理服务使用Prometheus来收集模型部署环境中的各类监控指标, 如:模型实例的资源利用率、吞吐量、延迟、错误率以及其他自定义指标。 Prometheus采用拉取的方式从监控对象处收集时序数据,并将其长期存储以支持历史查询分析。
Prometheus的存储是以时序数据的形式,以 timeseries-mertic-labels 的数据模型储存监控指标的数据。
时序(time series)是指一系列时间轴上的数值, mertic 代表监控指标的名称,labels代表监控指标的维度与标签。
这种数据模型使Graphcore可以在Prometheus的表达式语言PromQL下以高度灵活的方式查询和聚合时序数据。
平台管理者可以通过Prometheus的HTTP API和获取监控指标的时序数据,或在PromQL下进行复杂的聚合查询与分析。 这两种方法都可以方便的与其他系统集成,在NLP模型服务中构建出完备的监控与报警机制。对很多特定的监控指标, Prometheus都有成熟的管理方法,用户只需要进行简单的配置便可上手。
Grafana是一个开源的数据可视化与仪表盘工具。它可以查询Prometheus等时序数据源,并通过丰富的图表与UI组件构建出生动形象的监控Dashboard。 平台管理者可以在Grafana上将Prometheus收集到的监控指标进行可视化,观察各项指标随时间变化的曲线与图表,优化模型或者排查问题。 相比直接分析Prometheus采集的原始数据,Grafana提供了更加直观的监控报表,可以高效发现问题,也使得分享监控数据变得更加容易。
通过Prometheus采集的详尽监控指标,监控模块可以监控模型的QPS、LATENCY和任务错误率等性能指标,并根据历史数据更加精准地捕捉模型性能的异常变化。 平台管理者可以方便地在Grafana Dashboard上查看模型性能数据的走势图,这有助于更快速地发现模型存在的问题。 这使Graphcore在NLP模型服务的监控场景下,拥有了一个易于使用、功能强大且性能稳定的开源解决方案。 这大大增强了平台的监控能力,也极大简化了监控系统的研发和维护工作。 基于这个方案,研发团队可以更加专注在机器学习模型本身的开发与优化上。
搭建 prometheus 服务
首先我们保存以下内容到
visual_config/prom.yaml
其次启动
node-exporter
开启 prometheus 服务
搭建 grafana 可视化前端服务
拷贝以下内容到
visual_config/grafana.ini
启动 Grafana 服务
6.7.1. Grafana 的网页前端导入模版流程
访问地址
http://localhost:13000

登录到系统 用户名:
admin密码:admin

点击添加数据源
选择 prometheus

填入
http://localhost:19090并且点击save & test按钮.

使用下述
grafana 模版文件grafana 模版文件 文件导入Grafana模板。您可以选择将文件内容复制并粘贴到名 “通过面板JSON导入” 的区域,或者单击 “上传JSON文件” 按钮。之后,应单击 “加载” 按钮。

选择 “prometheus” 数据源选项,然后单击 “导入” 按钮。


6.8. 结论
综合而言, Graphcore公司的解决方案包括模型转换工具、不同框架的推理服务以及监控系统,形成了一整套完整的解决方案,旨在在NLP在线搜索场景中提供高效的推理性能。