2. IPU推理方案架构
本章将介绍Graphcore软件栈,以及IPU推理方案架构中的编译时和运行时。
2.1. 模型服务
通常一个训练好的模型需要通过模型服务的方式进行部署,从而被前端的客户程序消费,让模型能够真正的服务客户。
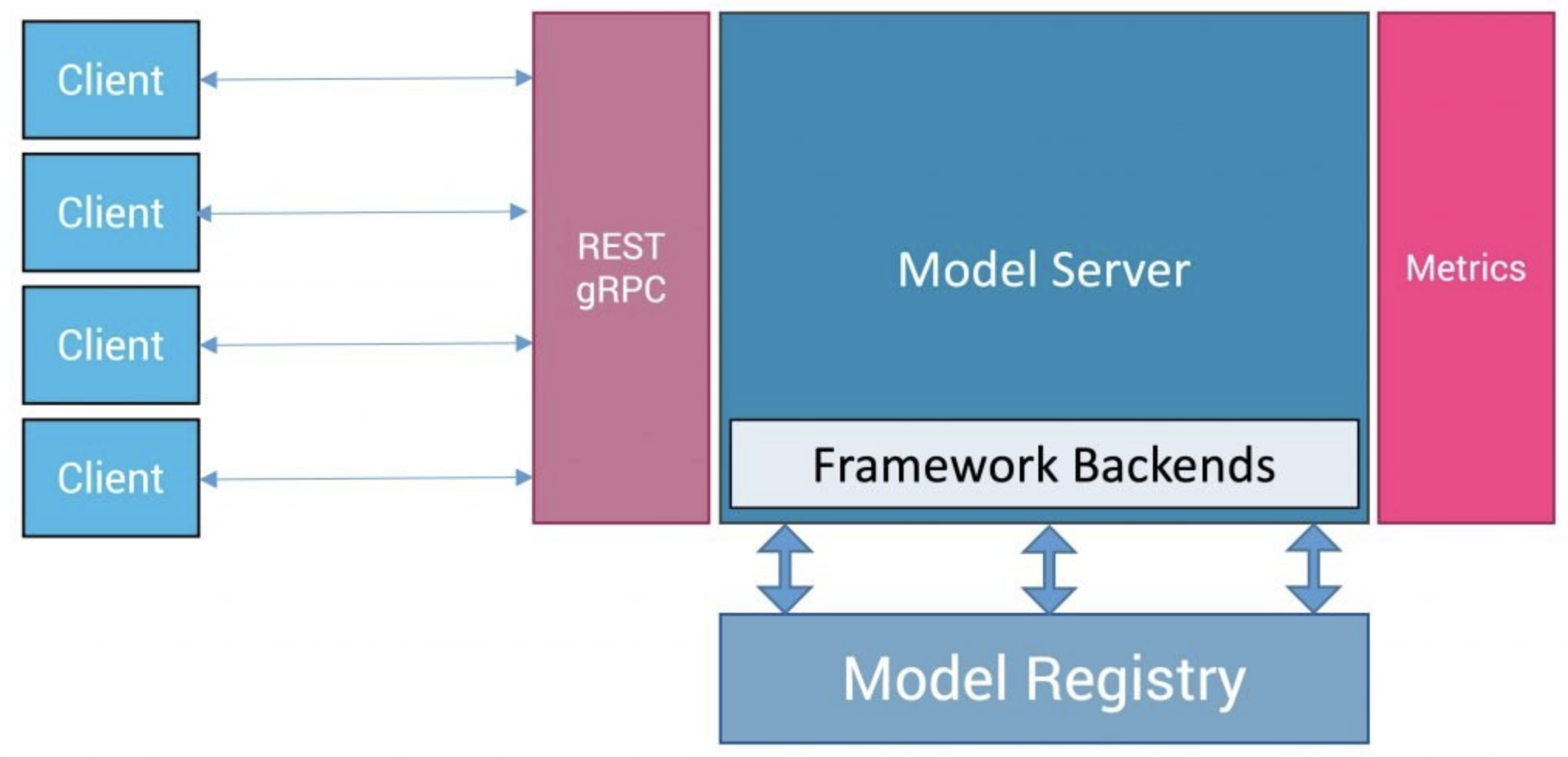
Fig. 2.1 模型服务
模型服务通常提供HTTP REST或者gRPC的接口供前端的应用程序调用,在模型服务器框架中一般会有模型管理、请求管理、数据监控和数据跟踪等功能,并通过框架后端将请求分发到相应的机器学习框架和硬件进行推理。在当前的开源市场上,有各种各样的模型服务器。
在IPU推理方案中,支持了 Triton Inference Server 和 TensorFlow Serving 模型服务器,并通过 Poplar Exchange Format (PopEF) 和 PopRT Runtime 可以方便的和各种模型服务器或者机器学习框架进行集成。
2.2. Graphcore Poplar软件栈
Graphcore Poplar软件栈 (Fig. 2.2), 提供了多个层次的编程接口,用户可以通过熟悉的机器学习框架的API来开发或者运行模型,也可以通过Poplar的API接口来开发在IPU上更加高效的算子。模型会通过Poplar的图编译器编译,通过Poplar的图引擎在IPU上运行。如果要深入了解IPU的编程,请参考 IPU Programmer’s Guide 。
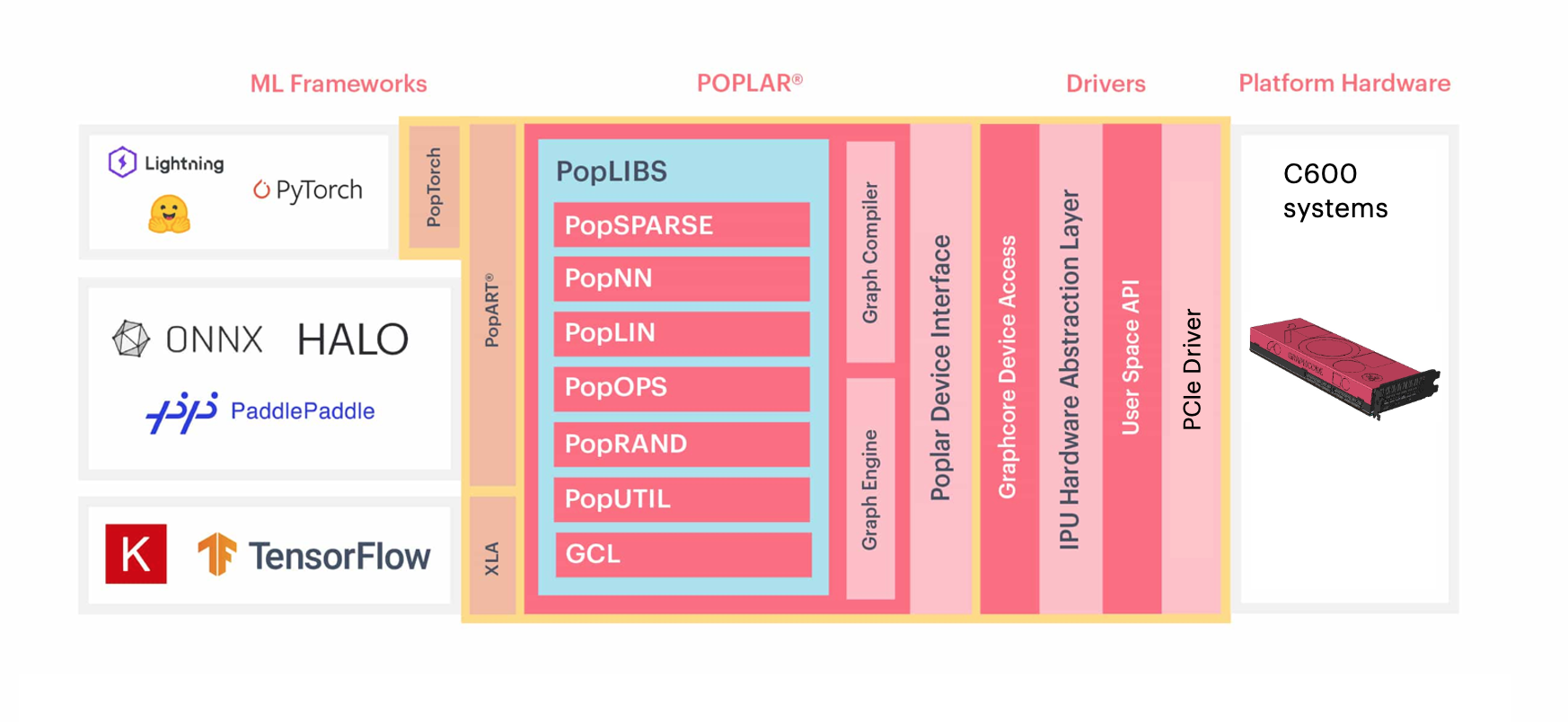
Fig. 2.2 Poplar软件栈
2.2.1. PopART
The Poplar Advanced Run Time (PopART) 是Poplar SDK提供的基于ONNX的机器学习框架。通过PopART可以构建和训练模型,也可以加载和运行由机器学习框架导出的ONNX模型。更多关于PopART的信息,请参考 PopART User Guide 。
2.2.2. PopEF and PopRT Runtime
Poplar Exchange Format (PopEF) 是Poplar SDK提供的用于导入和导出模型的一种统一的文件格式。PopEF中包含了经过Poplar编译器编译、可以在IPU上运行的二进制代码,模型的输入输出,以及模型运行所需的硬件信息。更多关于POPEF的内容,请参考 PopEF: User Guide 。
PopRT Runtime是用于加载和运行PopEF的运行时环境,可以快速的加载、运行PopEF,以及方便灵活的同模型服务框架或者机器学习框架集成。
2.3. IPU推理方案架构
如图 Fig. 2.3 所示,IPU推理方案分为编译和运行时两个部分。
编译阶段将用户需要部署的模型编译为PopEF文件,而运行时负责加载和运行编译阶段产生的PopEF。
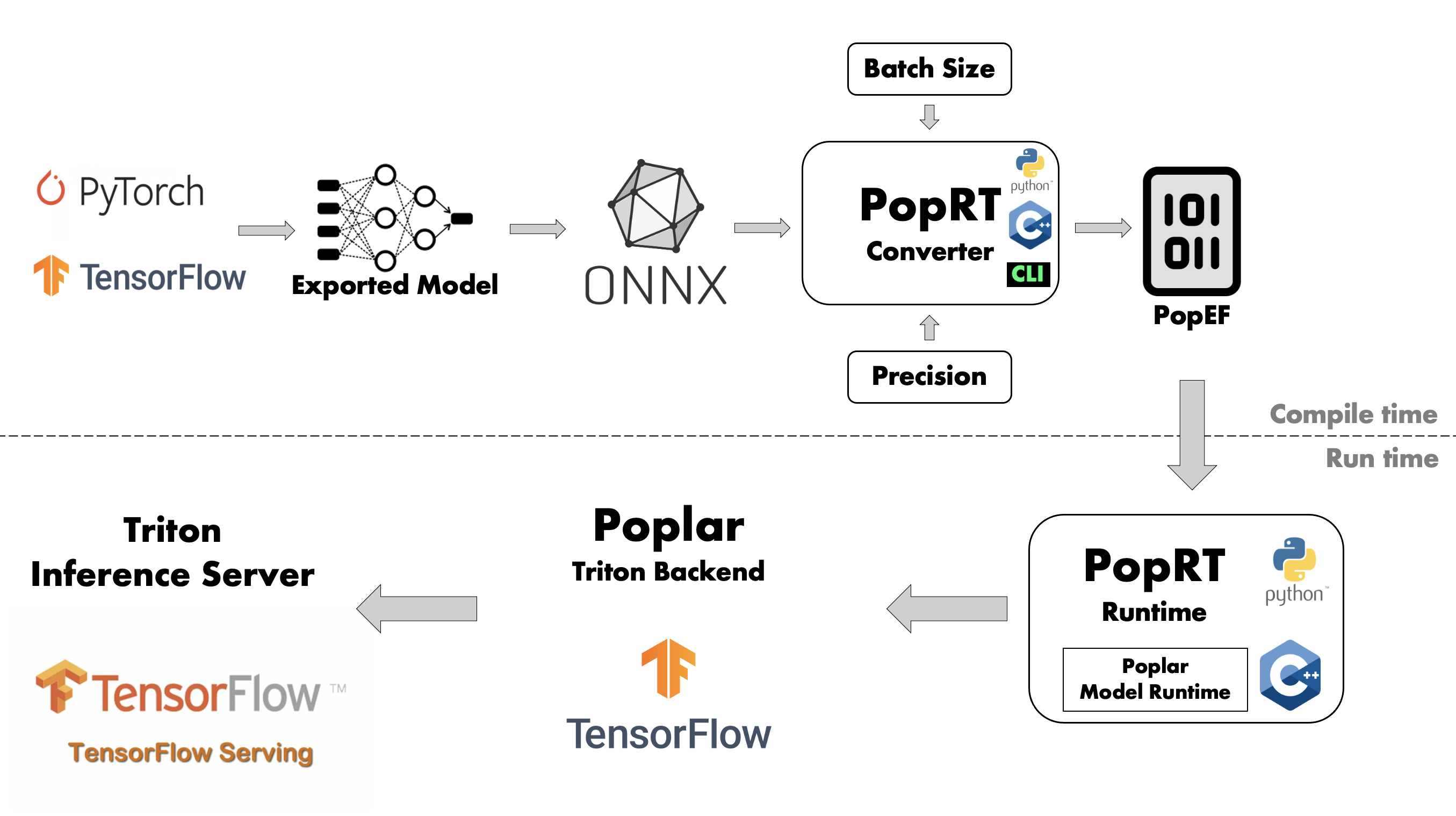
Fig. 2.3 IPU推理方案架构
2.3.1. 模型编译
模型编译是将用户要部署的模型编译为可以在IPU上运行的PopEF的过程,如图 Fig. 2.4 所示,包含了模型导出、选择Batch size、选择精度、模型转换和编译。
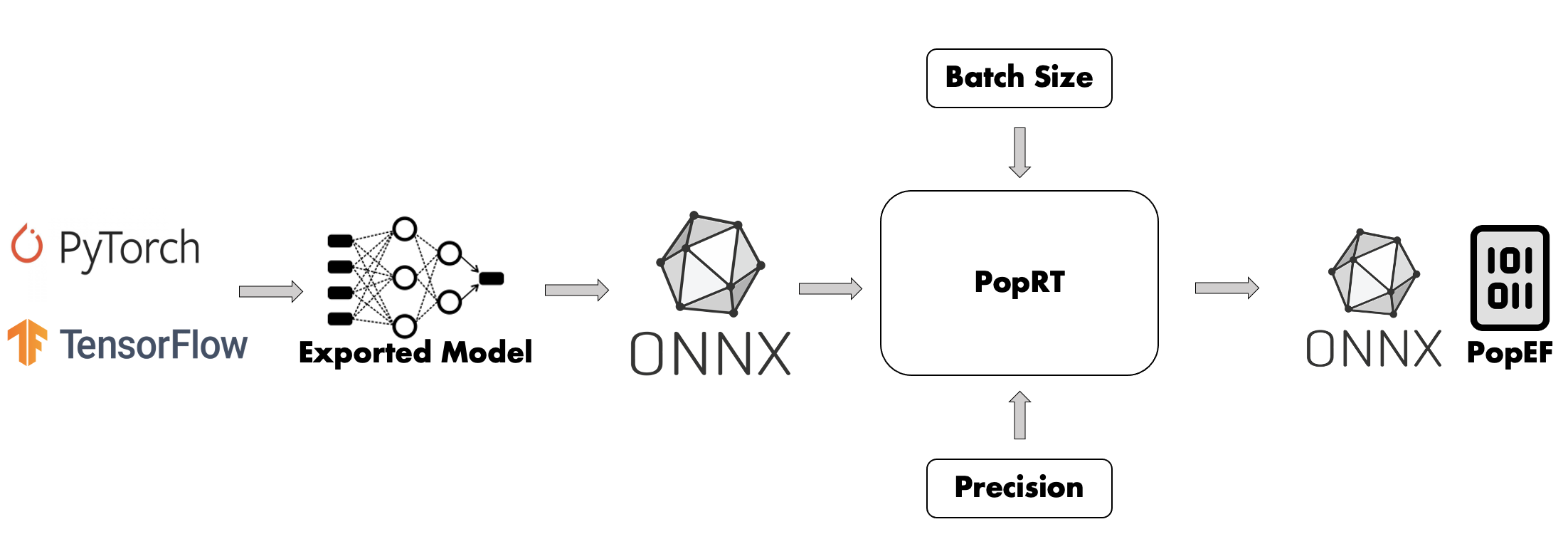
Fig. 2.4 模型编译流程
关于不同框架的模型如何进行编译将在 Section 4, 模型编译 中介绍。
模型导出
机器学习框架种类繁多,如 PyTorch 、TensorFlow 和 PaddlePaddle,等,各个框架之间的导出模型格式也不尽相同,如PyTorch pt,TensorFlow SavedModel和PaddlePaddle pdmodel等。 ONNX 提供了框架间模型转换的桥梁,大部分的框架由自身或者ONNX社区提供了框架导出模型到ONNX模型之间的转换方法。例如,tf2onnx 提供了由SavedModel到ONNX的转换方法。Section 4, 模型编译 中将会介绍从不同框架的模型转换成ONNX的步骤。
IPU推理方案中的模型转换工具 PopRT 将采用ONNX模型作为输入,经过一系列的转换和优化,输出可以在PopART上编译和运行的ONNX模型,并编译为PopEF文件。
选择Batch size
用户需要在编译阶段指定batch size的值。通常情况下,小的batch size意味着更低的时延,大的batch size意味着更高的吞吐,用户需要根据应用的需求确定batch size。
由于IPU只支持静态图,如果模型的输入在batch size之外还存在其他动态的维度,也需要在编译阶段确定维度的大小。
选择精度
用户需要在编译阶段指定模型将要采用的精度。IPU能够在FP16上保持与FP32相同的精度的情况下,获得更高的性能。所以尽量采用FP16作为模型的精度,在FP16不满足精度要求时才使用FP32。
模型转换
模型转换是将用户导出的ONNX模型转换为可以在PopART上运行的ONNX模型,并且在转换的过程中对模型进行一系列的优化。优化包括通用的优化,和针对IPU特性的优化,并且提供了用户自定义优化的接口。更多关于模型转换和优化的内容,请参考 PopRT 。
模型编译
模型编译是将通过 模型转换 得到的ONNX模型,经过POPART框架和Poplar编译器的编译,导出为PopEF的过程。
2.3.2. 模型运行
模型编译 生成的PopEF,可以通过三种方式来运行:
- Poplar Model Runtime API
PopRT Runtime提供了Python和C++的API,可以快速的运行模型,或者与深度学习框架以及模型服务器集成。更多信息请参考 PopRT 。
- Triton Inference Server
Graphcore通过 Poplar Model Runtime API实现了Poplar Triton Backend插件,可以将PopEF部署到Triton Inference Server。更多内容请参考 Poplar Triton Backend: User Guide 。
- TensorFlow Serving
通过 Poplar Model Runtime API 将加载和运行PopEF的功能包装成一个TensorFlow的custom op,使得编译后的模型可以通过TensorFlow Serving进行部署。
更多关于运行和部署模型的内容将在 Section 5, 模型运行 中介绍。