1. IPU-POD DA overview
The IPU-POD™ is designed to make both training and inference of very large and demanding machine-learning models faster, more efficient, and more scalable.
A single IPU-M2000 contains four IPUs connected via IPU-Links. Multiple IPU-M2000s can be connected together, using IPU-Links, as an IPU-POD to provide a highly scalable platform.
The IPU-POD Direct Attach (DA) system uses a small number of IPU-M2000s which are directly connected to the host server via the IPU-Fabric™. The name of an IPU‑POD indicates the number of IPUs it contains. Two versions are available: a single IPU-M2000 with four IPUs and a host server form the IPU‑POD4 DA, and four IPU-M2000s with 16 IPUs and a host server form the IPU‑POD16 DA.
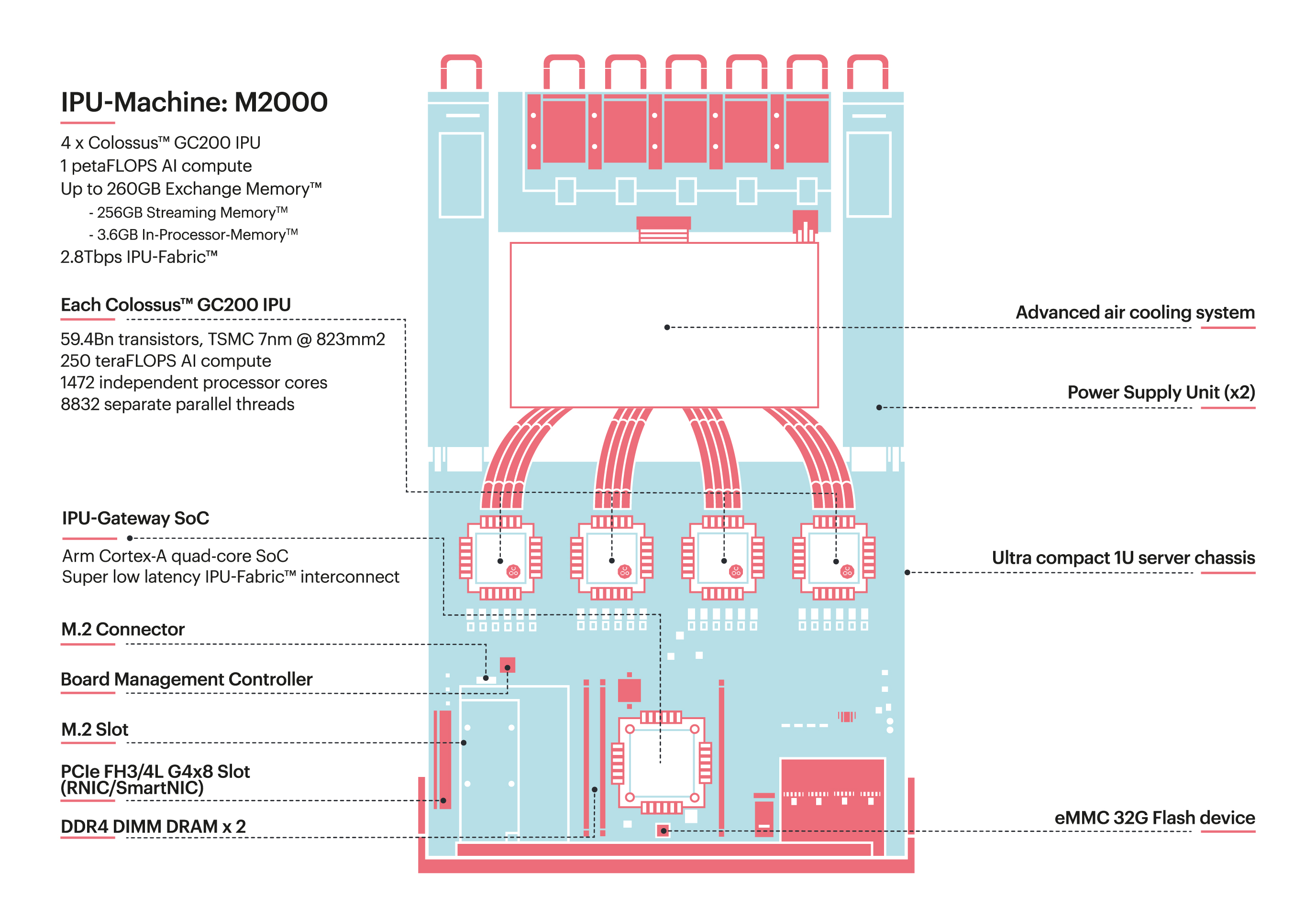
Fig. 1.1 IPU-M2000 architecture
This document describes the process of installing the necessary software and running a program on an IPU-POD DA system. See Getting Started with IPU-POD Systems for the same information for switched IPU‑PODs, which can support much larger numbers of IPUs.
See the IPU-POD Direct Attach Build and Test Guide for information on how to install and configure the IPU-M2000s in an IPU-POD DA system.
1.1. Poplar SDK
The IPU-POD DA is fully supported by Graphcore’s Poplar SDK to provide a complete, scalable platform for accelerated machine intelligence development.
The Poplar SDK contains tools for creating and running programs on IPU hardware using standard machine-learning frameworks such as PyTorch and TensorFlow. The SDK contains PopTorch, a set of extensions for PyTorch to enable PyTorch models to run directly on Graphcore IPU hardware. It also contains a Graphcore distribution of TensorFlow 1 and TensorFlow 2.
The SDK also includes command line tools for managing IPU hardware.