15. IPU host embeddings
An embedding table is a table in a model or compute graph that supports a lookup operation. For more details see the TensorFlow documentation on tf.nn.embedding_lookup.
On the IPU, large embeddings can be stored in host memory with the CPU performing the lookup operations (and update operations during training) in conjunction with the IPU. This functionality supports both inference and training.
During execution the IPU will synchronize with the host and send indices (and possibly update values) to the host CPU. The CPU will then perform the lookup or update operation in a callback before returning the result to the IPU. The IPU will then carry on execution.
Applications access this functionality through the
tensorflow.python.ipu.embedding_ops.HostEmbedding class and the
tensorflow.python.ipu.embedding_ops.create_host_embedding() helper
function. Optimisation of the host embedding is described in the
tensorflow.python.ipu.embedding_ops.HostEmbeddingOptimizerSpec
class, which currently only supports SGD with a constant learning rate.
Note
IPU host embeddings are not recommended for use in pipelines and will likely decrease the pipeline’s parallel efficiency.
15.1. Usage
IPU host embeddings rely on instances of the HostEmbedding class to
coordinate the communication between the host and device. This object is created
with a call to
tensorflow.python.ipu.embedding_ops.create_host_embedding(). The
created object is then passed to the user model where the
tensorflow.python.ipu.embedding_ops.HostEmbedding.lookup() method can
be called with a similar API to tf.nn.embedding_lookup.
Once the IPU host embedding has been created and used within the model, the
object must be “registered” with the session using the context manager created
by (tensorflow.python.ipu.embedding_ops.HostEmbedding.register()).
If TensorFlow session is not called within this context, TensorFlow will not
configure the underlying Poplar engine correctly and the model execution will
fail.
15.2. Example
1import numpy as np
2import tensorflow as tf
3
4from tensorflow.python.ipu import embedding_ops
5from tensorflow.python.ipu import ipu_compiler
6from tensorflow.python.ipu import ipu_infeed_queue
7from tensorflow.python.ipu import loops
8from tensorflow.python.ipu import cross_replica_optimizer
9from tensorflow.python.ipu import scopes
10from tensorflow.python.ipu import rnn_ops
11from tensorflow.python import ipu
12from tensorflow.python import keras
13
14path_to_file = keras.utils.get_file(
15 'shakespeare.txt',
16 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt'
17)
18
19# Read, then decode for py2 compat.
20text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
21
22# The unique characters in the file
23vocab = sorted(set(text))
24
25# Creating a mapping from unique characters to indices
26char2idx = {u: i for i, u in enumerate(vocab)}
27idx2char = np.array(vocab)
28text_as_int = np.array([char2idx[c] for c in text]).astype(np.int32)
29
30sequence_length = 100
31batch_size = 16
32replication_factor = 2
33
34# Create training examples / targets
35ds = tf.data.Dataset.from_tensor_slices(text_as_int)
36ds = ds.batch(sequence_length, drop_remainder=True)
37ds = ds.shuffle(batch_size * batch_size)
38ds = ds.batch(batch_size, drop_remainder=True)
39ds = ds.repeat()
40
41# The host side queues
42infeed_queue = ipu_infeed_queue.IPUInfeedQueue(ds)
43
44# Set the learning rate
45lr = 0.0001
46
47# Create a momentum optimiser for replication
48optimizer = cross_replica_optimizer.CrossReplicaOptimizer(
49 tf.train.MomentumOptimizer(lr, 0.99))
50
51# Create a host embedding object
52embedding = embedding_ops.create_host_embedding(
53 "char_embedding",
54 shape=[256, 256],
55 dtype=tf.float32,
56 partition_strategy="TOKEN",
57 optimizer_spec=embedding_ops.HostEmbeddingOptimizerSpec(lr))
58
59
60# PopnnGRU is time-major
61def gru(partials):
62 gru_ = rnn_ops.PopnnGRU(256)
63 partial_t = tf.transpose(partials, [1, 0, 2])
64 gru_outputs_t, _ = gru_(partial_t)
65 return tf.transpose(gru_outputs_t, [1, 0, 2])
66
67
68# The main model
69def model(sequence):
70 # Perform a lookup on the embedding
71 partial = embedding.lookup(sequence)
72
73 partial = gru(partial)
74 partial = tf.reshape(partial, [partial.shape[0], -1])
75 partial = tf.layers.dense(partial, 256)
76 return tf.nn.softmax(partial)
77
78
79# Compute the loss for a given batch of examples
80def evaluation(sequence):
81 # Use the last element of the sequence as the label to predict
82 label = tf.slice(sequence, [0, sequence_length - 1], [-1, 1])
83 sequence = tf.slice(sequence, [0, 0], [-1, sequence_length - 1])
84 logits = model(sequence)
85 return keras.losses.sparse_categorical_crossentropy(label, logits)
86
87
88# Minimise the loss
89def training(loss, sequence):
90 loss = evaluation(sequence)
91 mean_loss = tf.math.reduce_mean(loss)
92 train = optimizer.minimize(loss)
93 return mean_loss, train
94
95
96num_iterations = 1000
97
98
99# Loop over our infeed queue, training the model
100def my_net():
101 loss = tf.constant(0.0, shape=[])
102 r = loops.repeat(num_iterations, training, [loss], infeed_queue)
103 return r
104
105
106# Compile the model
107with scopes.ipu_scope('/device:IPU:0'):
108 run_loop = ipu_compiler.compile(my_net, inputs=[])
109
110# Configure the hardware
111config = ipu.config.IPUConfig()
112config.auto_select_ipus = replication_factor
113config.configure_ipu_system()
114
115with tf.Session() as sess:
116 sess.run(tf.global_variables_initializer())
117 sess.run(infeed_queue.initializer)
118
119 # Train the model for some iterations
120 with embedding.register(sess):
121 for i in range(25):
122 l = sess.run(run_loop)
123 print("Step " + str(i) + ", loss = " + str(l))
Download host_embedding_example.py
15.3. Experimental functionality: IPU embeddings in remote buffers
As an alternative to host embeddings, there is experimental functionality to store embedding tables in remote buffers in Streaming Memory (that is, off-chip memory directly accessed by the IPU). In this case, the IPU performs the lookup/update operations directly on the remote buffers, and the host CPU is not involved.
Setting the experimental.enable_remote_buffer_embedding option on an
IPUConfig to True (defaults to
False) and then configuring the IPU system with that IPUConfig will
use IPU embeddings in remote buffers, globally.
Note
This option is experimental, and may be changed or removed in future releases.
15.3.1. Partitioning strategies
When using IPU embeddings in remote buffers together with data-parallel replication, the embedding table is not duplicated for each replica. Instead, a single copy of the table is shared between replicas to make the most of available memory. However, each replica only has access to a distinct memory space so the table is partitioned into chunks between the replicas (this holds even on hardware platforms where IPUs share physical external memory).
The way the table is split between the memory attached to each replica
is determined by the partitioning strategy. Two
partitioning strategies are available.
These are the token strategy and the encoding strategy.
Each has trade-offs and the
choice of strategy will depend on the application. The partition
strategy is set via the partition_strategy keyword argument of
create_host_embedding().
Token strategy
The token strategy partitions the embedding on the
token axis. There will be ceil(t/r) whole tokens on each replica,
where t is the token count and r is the replica count.
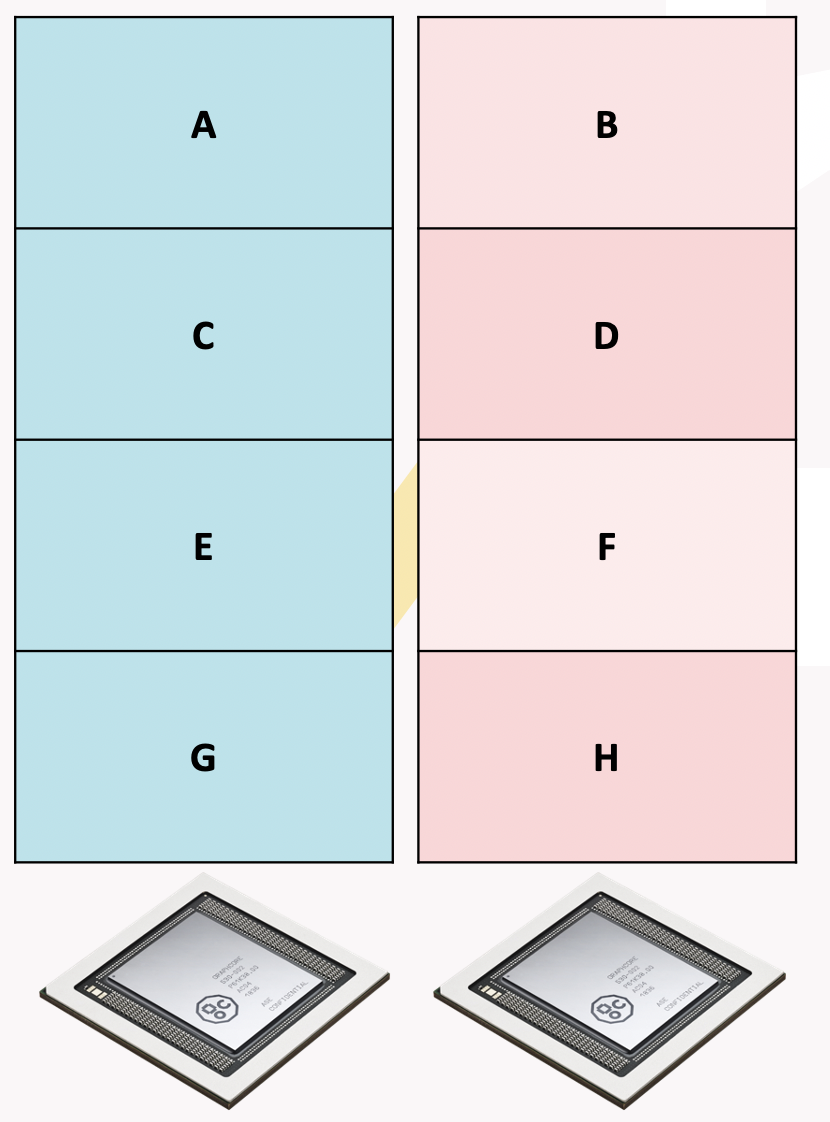
Fig. 15.1 Host embedding token strategy
When this strategy is used, cross-replica operations are required to allow each replica to perform a lookup or update across the whole table (each replica’s portion of the whole embedding table is private to that replica). Below is the pseudo-code, with explicit types and static shapes, for how this is implemented:
1// Pseudo-code assuming we have table size `t`, and replica count `r`.
2f16[14, 64] global_lookup(
3 local_table : f16[ceil(t/r), 64]
4 global_indices : i32[14]
5):
6 // The unique replica ID for "this" replica.
7 replica_id = i32[] get-replica-id
8
9 // Distribute the indices to all devices.
10 indices = all-gather(indices) : i32[r, 14]
11
12 // Scale the indices down by the replication factor. Indices not meant for
13 // this replica will map to a valid, but incorrect index.
14 local_indices = indices / r : i32[r, 14]
15
16 // Gather on the local embedding region.
17 result = lookup(embedding, indices) : f16[r, 14, 64]
18
19 // The mask of which indices are valid.
20 mask = (indices % r) == replica_id : bool[r, 14]
21
22 // Zero out the invalid regions of the result
23 result = select(result, 0, mask) : f16[r, 14, 64]
24
25 // Reduce scatter sum the masked result tensor. The zeroed regions of the
26 // result tensor ensure that invalid values are ignore and each replica has
27 // the correct result.
28 result = reduce-scatter-sum(result) : f16[1, 14, 64]
29
30 // Reshape to the expected shape
31 return reshape(result), shape=[14, 64] : f16[14, 64]
Encoding strategy
The encoding strategy will partition the embedding on the encoding
axis. There will be ceil(1/r) of every tokens on each replica,
where r is the replica count. This means
for a given token every replica will store ceil(e/r) elements, where e
is the element count for a single token.
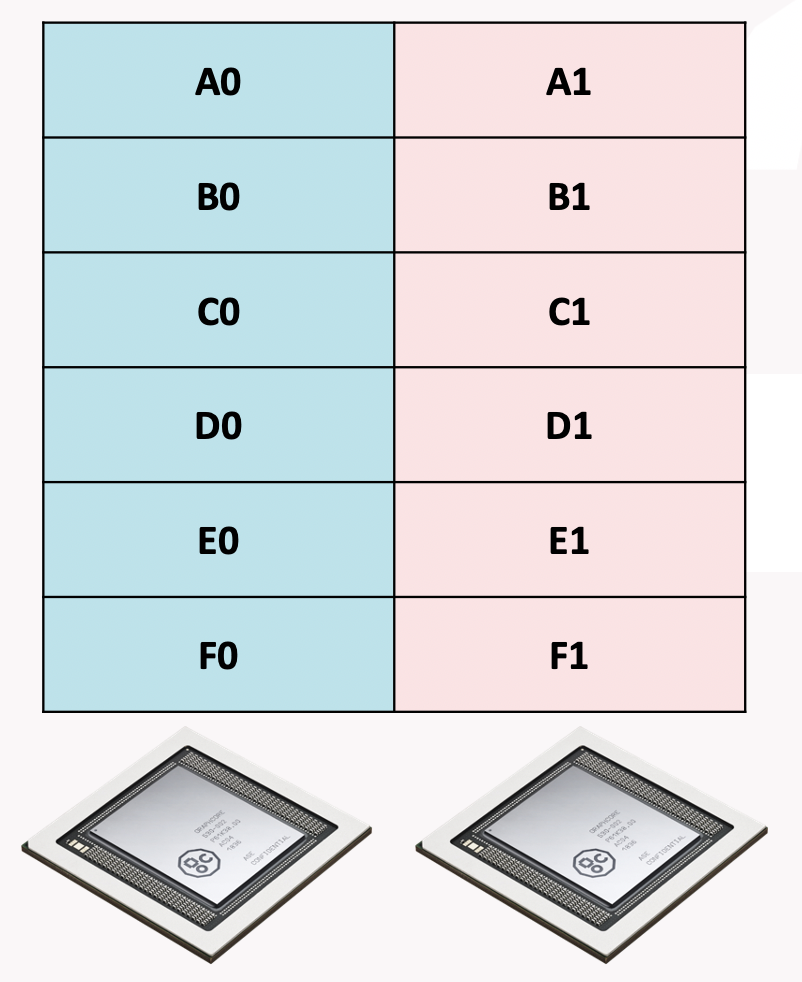
Fig. 15.2 Host embedding encoding strategy
When this strategy is used, cross-replica operations are required to allow each replica to perform a lookup or update across the whole table (each replica’s portion of the whole embedding table is private to that replica). Below is the pseudo-code, with explicit types and static shapes, for how this is implemented:
1// Pseudo-code assuming we have table size `t`, replica count `r`, and
2// encoding size `e`.
3f16[14, e] global_lookup(
4 local_table : f16[t, ceil(e/r)]
5 global_indices : i32[14]
6):
7 // Distribute the indices to all devices
8 indices = all-gather(global_indices) : i32[r, 14]
9
10 // Gather on the local embedding
11 result = lookup(local_embedding, indices) : f16[r, 14, ceil(e/r)]
12
13 // Communicate the relevant parts of the embedding to their respective
14 // replicas. This distributes the ith slice in the outermost dimension to
15 // ith replica.
16 result = all-to-all(result, slice_dim=2, concat_dim=3) : f16[r, 14, ceil(e/r)]
17
18 // Transpose the dimensions back into the correct order.
19 result = transpose(result), permutation=[1, 0, 2] : f16[14, r, ceil(e/r)]
20
21 // Flatten the innermost dimensions
22 result = flatten(result), begin=1, end=2 : f16[14, r*ceil(e/r)]
23
24 // Slice off the excess padding on the encoding
25 return slice(result), dim=1, begin=0, end=e : f16[14, e]
Choosing a strategy for your application
The choice of partitioning strategy is application dependent and the best way to determine the best strategy is to profile multiple strategies.
As a general rule, the token strategy is used when the encoding is much smaller than the token count. An example application for this would be language models where the vocabulary size is much larger than the encoding.
Conversely, the encoding strategy is used when the token count is small and the encoding is large enough to be split. This avoids a large amount of very small communication. An example application for this would be game playing models, where a small numbers of available actions are encoded in an embedding.