3. Pipelining
3.1. Overview
The pipeline approach is similar to sharding. The entire model is partitioned into multiple computing stages, and the output of a stage is the input of the next stage. These stages are executed in parallel on multiple IPUs. Compared to using sharding technology alone, the pipeline approach can maximise the use of all IPUs involved in parallel model processing, which improves processor efficiency as well as throughput and latency performance.
The figure below shows how to use pipelining for derivation in model parallelism (the dotted-line box indicates the point in the pipeline body where all IPUs are used to the maximum extent). The model consists of four layers and these are divided into four stages. Each stage is assigned to an IPU which computes a layer. When the first IPU receives a batch of data B1 and the first stage is executed, the second IPU starts to execute the second stage and, at the same time, the first IPU receives the next batch of data B2 and starts to execute the first stage, and so on. When the fourth batch of data B4 is read, the parallelism of the four IPUs reaches 100%.
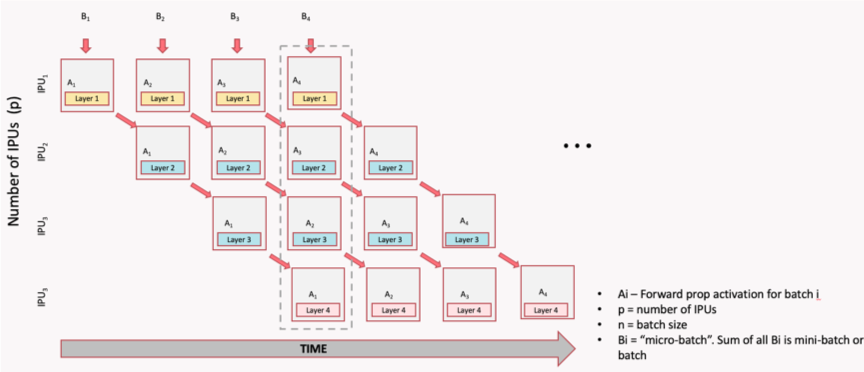
Fig. 3.1 Pipeline time sequence during model inference
The pipeline is relatively simple for inference, but more complicated for training based on back propagation. For training, pipelining needs to adapt to include forward pass, back propagation and weight update.
The figure below shows a single computational flow of forward pass and back propagation, and then shows a complete pipeline with parallel overlapping batches.
Each IPU performs not only the forward computation (Ai) of the corresponding layer, but also the gradient computation (AiGi). The dotted-line box shows the main body of the pipeline (it can be any depth, and larger depth can increase the size of the batch). Through the use of recomputation (see Optimising the pipeline), the relevant IPU is used to the maximum extent to process forward activations, the previous activations are recomputed from the stored activation inputs, and the gradient updates are computed to save valuable on-chip memory.
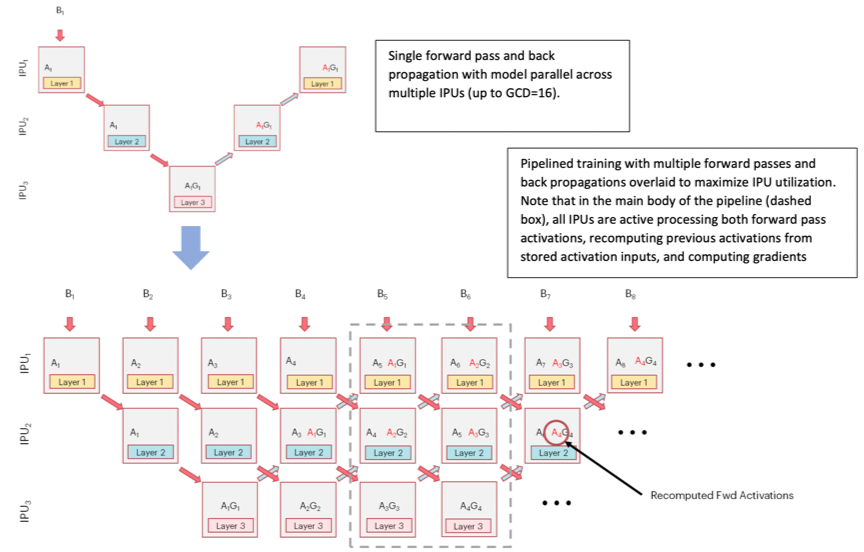
Fig. 3.2 Pipeline time sequence during model training
The GCD mentioned in the image stands for “graph compile domain”, and is a set of IPUs which the Poplar graph compiler will compile binaries for. With a GCD of size 16, for example, we can generate a model-parallel graph that executes on 16 IPUs.
3.2. Pipeline operation
There are three phases to the pipelined execution:
Ramp up: this is the period in which the pipeline is being filled until every pipeline stage (including forward and backward passes) is performing computation. The maximum utilisation is 50%.
Main execution: the time when all the pipeline stages are performing computation. This is the period when maximum use is being made of all the IPUs.
Ramp down: the time when the pipeline is being drained until each pipeline stage is no longer performing any computation. The maximum utilisation is again 50%.
After ramp down, the weight updates are performed.
Note
Pipelining must not be combined with sharding.
3.3. Pipelining API
The pipelining API allows the you to describe what the forward, backward and weight update operations are. You define the forward stages. The backward stages and the weight updates are automatically generated. Check the pipelining interface in the TensorFlow API documentation.
3.3.1. Inputs and outputs
All tensors which are used in the pipeline that are not TensorFlow variables need to be explicitly passed as inputs to the pipeline. If the input passed in does not change value – for example, hyper-parameters – add them to the inputs argument.
If the input does change value with every execution of a pipeline stage – for example, batches of data – then create an IPUInfeedQueue and pass it to the infeed_queue argument.
The inputs list and the infeed_queue are passed as inputs to the first pipeline stage.
After the initial pipeline stage, all the outputs of a pipeline stage N are passed as inputs to the pipeline stage N+1. If an output of a stage N is used by a stage N+M where M > 1, then that output will be passed through the stages in between.
If the last computational stage has any outputs – for example, loss or the prediction – then you will need to create an IPUOutfeedQueue and pass it to the outfeed_queue argument. All the outputs from the final computational stage are passed to the outfeed automatically.
3.3.2. Device mapping
By default, the pipeline stages will be assigned to IPU devices in an order which should maximise the utilisation of IPU-Links between consecutive pipeline stages.
If your model is not sequential you might want to change the assignment, depending on the communication pattern in your model.
Any TensorFlow variables can only be used by pipeline stages which are on the same IPU. You can use the device mapping API to assign pipeline stages which use the same variable to be on the same IPU.
3.3.3. Pipeline scheduling
You can choose the method used for scheduling the operations in the pipeline. The scheduling methods have different trade-offs in terms of memory use, balancing computation between pipeline stages (and therefore the IPUs), and optimisations that can be applied. They will also have different pipeline depths and therefore different ramp-up and ramp-down times. The differences are most significant when training and you may need to experiment to find which method works best for your model.
In the Grouped schedule the forward and backward stages are grouped together on each IPU. All IPUs alternate between executing a forward pass and then a backward pass.
In the Interleaved schedule each pipeline stage executes a combination of forward and backward passes.
Finally, there is a sequential schedule. This is the same as sharding a model: only one batch is ever “in-flight”. This may be useful when you cannot have a big batch size but want to make use of other pipeline features.
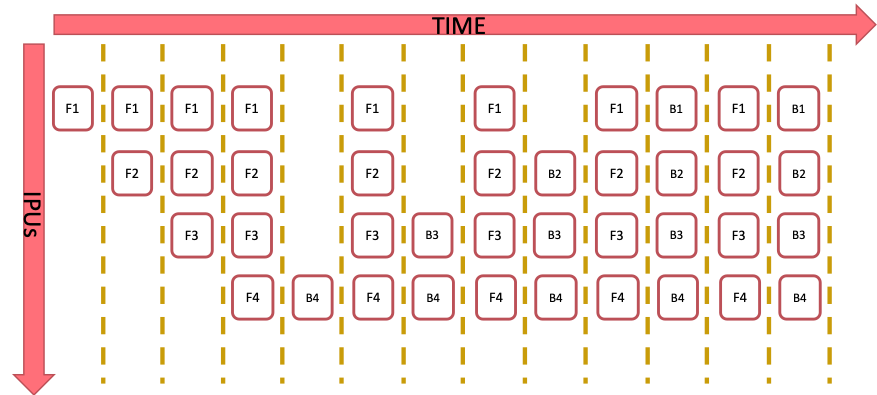
Fig. 3.3 Grouped schedule
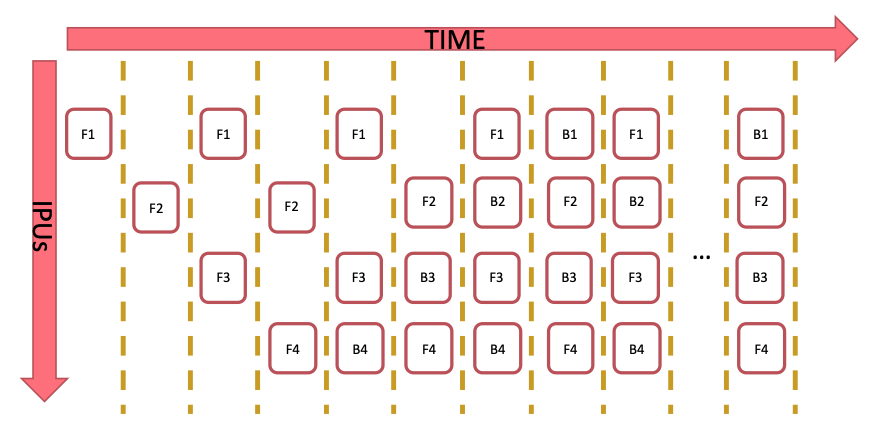
Fig. 3.4 Interleaved schedule
The grouped and interleaved schedules have different advantages and disadvantages:
Memory use:
The grouped schedule executes 2N batches at any given time.
The interleaved schedule executes N batches.
This means that the interleaved schedule requires less memory for the storing the data to be transferred between forward and backward passes.
Execution time:
The grouped schedule executes all the forward stages together and all the backward stages together.
The interleaved schedule executes the forward stages and backward stages interleaved.
Due to the synchronisation required between stages, and the fact that the forward stages tend to use fewer cycles than the backward stages, the grouped schedule is likely to be faster.
Ramp-up and ramp-down time:
The grouped schedule executes 2N batches in total to perform the ramp up and ramp down.
The interleaved schedule executes N batches in total to perform the ramp up and ramp down.
Other:
Some inter-IPU optimisations are not possible with the interleaved schedule. For example, an optimisation which converts variables which are passed through multiple pipeline stages into FIFOs.
3.3.4. Keras API in TensorFlow 2
TensorFlow 2 for the IPU includes a port of Keras which features IPU-optimized replacements for the Keras Model and Sequential classes. There are also versions of these classes that support pipelining: PipelineModel and PipelineSequential.
The API for these classes extends the API for the corresponding IPU-specific Keras classes with additional arguments that mostly match the arguments for the pipeline operator. For more details check the TensorFlow API documentation.
3.4. Code examples
3.4.1. Inference code examples
The following code shows an example usage of the pipeline API.
1from tensorflow.python import ipu
2from tensorflow.python.ipu import ipu_compiler
3from tensorflow.python.ipu import ipu_infeed_queue
4from tensorflow.python.ipu import ipu_outfeed_queue
5from tensorflow.python.ipu.ops import pipelining_ops
6from tensorflow.python.data.ops.dataset_ops import Dataset
7from tensorflow.python.ipu import scopes
8from tensorflow.python.ipu import utils
9from tensorflow.python.framework import ops
10from tensorflow.python.ops import variables
11from tensorflow.keras import layers
12import numpy as np
13import tensorflow.compat.v1 as tf
14
15tf.disable_v2_behavior()
16
17# default data_format is 'channels_last'
18dataset = Dataset.from_tensor_slices(np.random.uniform(size=(2, 128, 128, 3)).astype(np.float32))
19dataset = dataset.batch(batch_size=2, drop_remainder=True)
20dataset = dataset.cache()
21dataset = dataset.repeat()
22dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
23
24# Create the data queues from/to IPU.
25infeed_queue = ipu_infeed_queue.IPUInfeedQueue(dataset, "infeed")
26outfeed_queue = ipu_outfeed_queue.IPUOutfeedQueue("outfeed")
27
28# Create a pipelined model which is split accross two stages.
29def stage1(partial):
30 partial = layers.Conv2D(128, 1)(partial)
31 return partial
32
33def stage2(partial):
34 partial = layers.Conv2D(128, 1)(partial)
35 return partial
36
37def my_net():
38 pipeline_op = pipelining_ops.pipeline(
39 computational_stages=[stage1, stage2],
40 gradient_accumulation_count=16,
41 repeat_count=2,
42 inputs=[],
43 infeed_queue=infeed_queue,
44 outfeed_queue=outfeed_queue,
45 name="Pipeline")
46 return pipeline_op
47
48with ops.device("/device:IPU:0"):
49 r = ipu_compiler.compile(my_net, inputs=[])
50
51dequeue_op = outfeed_queue.dequeue()
52
53cfg = utils.create_ipu_config()
54cfg = utils.auto_select_ipus(cfg, 2)
55utils.configure_ipu_system(cfg)
56utils.move_variable_initialization_to_cpu()
57
58with tf.Session() as sess:
59 sess.run(variables.global_variables_initializer())
60 sess.run(infeed_queue.initializer)
61 sess.run(r)
62 output = sess.run(dequeue_op)
The code first creates a dataset with infeed_queue and outfeed_queue which are for data input and output. The functions stage1() and stage2() define two computation stages. The most important definitions are in my_net() which defines the entire behaviour of the pipeline. Among them, computational_stages indicates that the stage list contains stage1 and stage2; gradient_accumulation_count=16 means that each pipeline stage is executed 16 times, and repeat_count=2 means that the whole pipeline is executed twice. The program selects two IPUs to perform this task using auto_select_ipus(), and each stage is automatically assigned to a single IPU.
The following example uses the Keras API in TensorFlow 2 to define a model equivalent to the one in the example above.
1from tensorflow.python.data.ops.dataset_ops import Dataset
2from tensorflow.python.ipu import utils
3from tensorflow.keras import layers
4from tensorflow.python.ipu import keras
5from tensorflow.python.ipu import ipu_strategy
6import numpy as np
7import tensorflow as tf
8
9# default data_format is 'channels_last'
10dataset = Dataset.from_tensor_slices(np.random.uniform(size=(2, 128, 128, 3)).astype(np.float32))
11dataset = dataset.batch(batch_size=2, drop_remainder=True)
12dataset = dataset.cache()
13dataset = dataset.repeat()
14dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
15
16# Create a pipelined model which is split accross two stages.
17def my_model():
18 input_layer = layers.Input(shape=(128, 128, 3), dtype=tf.float32, batch_size=2)
19
20 with keras.PipelineStage(0):
21 partial = layers.Conv2D(128, 1)(input_layer)
22
23 with keras.PipelineStage(1):
24 partial = layers.Conv2D(128, 1)(partial)
25
26 return keras.PipelineModel(input_layer,
27 partial,
28 gradient_accumulation_count=16,
29 )
30
31cfg = utils.create_ipu_config()
32cfg = utils.auto_select_ipus(cfg, 2)
33utils.configure_ipu_system(cfg)
34utils.move_variable_initialization_to_cpu()
35
36# Define the model under an IPU strategy scope
37strategy = ipu_strategy.IPUStrategy()
38with strategy.scope():
39 model = my_model()
40
41 output = model.predict(dataset, steps=2, steps_per_run=2)
When defining a model for use with PipelineModel, the computational stages are defined by the layers under the PipelineStage scopes. In TensorFlow 2 to ensure that the model will be compiled for the IPUs we enclose it in an IPUstrategy scope.
The program calls the predict() method to run inference on the model. The argument steps_per_run is analogous to repeat_count in the previous example, where we specify how many times to execute the whole pipeline on the devices, before giving control back to the host.
Following is the same model defined using the PipelineSequential.
1from tensorflow.python.data.ops.dataset_ops import Dataset
2from tensorflow.python.ipu import utils
3from tensorflow.keras import layers
4from tensorflow.python.ipu import keras
5from tensorflow.python.ipu import ipu_strategy
6import numpy as np
7import tensorflow as tf
8
9# default data_format is 'channels_last'
10dataset = Dataset.from_tensor_slices(np.random.uniform(size=(2, 128, 128, 3)).astype(np.float32))
11dataset = dataset.batch(batch_size=2, drop_remainder=True)
12dataset = dataset.cache()
13dataset = dataset.repeat()
14dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
15
16# Create a pipelined model which is split accross two stages.
17def my_model():
18 return keras.PipelineSequential(
19 [[layers.Conv2D(128, 1)],
20 [layers.Conv2D(128, 1)]],
21 gradient_accumulation_count=16)
22
23cfg = utils.create_ipu_config()
24cfg = utils.auto_select_ipus(cfg, 2)
25utils.configure_ipu_system(cfg)
26utils.move_variable_initialization_to_cpu()
27
28# Define the model under an IPU strategy scope
29strategy = ipu_strategy.IPUStrategy()
30with strategy.scope():
31 model = my_model()
32
33 output = model.predict(dataset, steps=2, steps_per_run=2)
The only difference from PipelineModel is how the model is defined: the PipelineSequential takes a list of list of layers, where each list of layers correspond to a computational stage.
3.4.2. Training code examples
This example creates a pipeline of four stages with gradient accumulation count of 8 and a repeat count of 2. Four IPUs are selected for computation.
The selection order is ZIGZAG, and recomputation is enabled. The loss function is cross-entropy, and the optimiser is tf.train.GradientDescentOptimizer().
The source code is shown below:
1from tensorflow.python import ipu
2from tensorflow.python.ipu import ipu_compiler
3from tensorflow.python.ipu import ipu_infeed_queue
4from tensorflow.python.ipu import ipu_outfeed_queue
5from tensorflow.python.ipu.ops import pipelining_ops
6from tensorflow.python.ops import variable_scope
7from tensorflow.python.data.ops.dataset_ops import Dataset
8from tensorflow.python.ipu import utils
9from tensorflow.python.framework import ops
10from tensorflow.python.ops import variables
11from tensorflow.keras import layers
12import numpy as np
13import tensorflow.compat.v1 as tf
14
15tf.disable_v2_behavior()
16
17# default data_format is 'channels_last'
18dataset = Dataset.from_tensor_slices(
19 (tf.random.uniform([2, 128, 128, 3], dtype=tf.float32),
20 tf.random.uniform([2], maxval=10, dtype=tf.int32))
21 )
22dataset = dataset.batch(batch_size=2, drop_remainder=True)
23dataset = dataset.shuffle(1000)
24dataset = dataset.cache()
25dataset = dataset.repeat()
26dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
27
28# Create the data queues from/to IPU.
29infeed_queue = ipu_infeed_queue.IPUInfeedQueue(dataset, "infeed")
30outfeed_queue = ipu_outfeed_queue.IPUOutfeedQueue("outfeed")
31
32# Create a pipelined model which is split accross four stages.
33def stage1(partial, labels):
34 with variable_scope.variable_scope("stage1", use_resource=True):
35 with variable_scope.variable_scope("conv", use_resource=True):
36 partial = layers.Conv2D(3, 1)(partial)
37 return partial, labels
38
39def stage2(partial, labels):
40 with variable_scope.variable_scope("stage2", use_resource=True):
41 with variable_scope.variable_scope("conv", use_resource=True):
42 partial = layers.Conv2D(3, 1)(partial)
43 return partial, labels
44
45def stage3(partial, labels):
46 with variable_scope.variable_scope("stage3", use_resource=True):
47 with variable_scope.variable_scope("conv", use_resource=True):
48 partial = layers.Conv2D(3, 1)(partial)
49 return partial, labels
50
51def stage4(partial, labels):
52 with variable_scope.variable_scope("stage3", use_resource=True):
53 with variable_scope.variable_scope("flatten", use_resource=True):
54 partial = layers.Flatten()(partial)
55 with variable_scope.variable_scope("dense", use_resource=True):
56 logits = layers.Dense(10)(partial)
57 with variable_scope.variable_scope("entropy", use_resource=True):
58 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
59 labels=labels, logits=logits)
60 with variable_scope.variable_scope("loss", use_resource=True):
61 loss = tf.reduce_mean(cross_entropy)
62 return loss
63
64def optimizer_function(loss):
65 optimizer = tf.train.GradientDescentOptimizer(0.01)
66 return pipelining_ops.OptimizerFunctionOutput(optimizer, loss)
67
68def my_net():
69 pipeline_op = pipelining_ops.pipeline(
70 computational_stages=[stage1, stage2, stage3, stage4],
71 gradient_accumulation_count=8,
72 repeat_count=2,
73 inputs=[],
74 infeed_queue=infeed_queue,
75 outfeed_queue=outfeed_queue,
76 optimizer_function=optimizer_function,
77 name="Pipeline")
78 return pipeline_op
79
80with ops.device("/device:IPU:0"):
81 r = ipu_compiler.compile(my_net, inputs=[])
82
83dequeue_op = outfeed_queue.dequeue()
84
85cfg = utils.create_ipu_config(selection_order=utils.SelectionOrder.ZIGZAG)
86cfg = utils.auto_select_ipus(cfg, 4)
87cfg = utils.set_recomputation_options(cfg)
88utils.configure_ipu_system(cfg)
89utils.move_variable_initialization_to_cpu()
90
91with tf.Session() as sess:
92 sess.run(variables.global_variables_initializer())
93 sess.run(infeed_queue.initializer)
94 sess.run(r)
95 losses = sess.run(dequeue_op)
Here, tf.train.GradientDescentOptimizer() automatically adds a stage to the pipeline for gradient computation, and a stage (gradientDescent) for weight update. Note that gradient_accumulation_count=8 means that gradientDescent is computed once every eight batches of data. And repeat_count=2 means that the pipeline computes twice the gradientDescent; that is, the weight parameter is updated twice.
You can profile the program by running it with the following environment variable POPLAR_ENGINE_OPTIONS='{"autoReport.all":"true", "autoReport.directory":"/destination/path/"}', and then open the generated report with PopVision Graph Analyser to get the execution information as shown in the Training pipeline profile figure below. Check also the PopVision™ Graph Analyser tool section for further information.

Fig. 3.5 Training pipeline profile
We can see from this figure that:
The pipeline is repeated twice.
A single pipeline repeat computes eight batches of data.
Each batch of data goes through the phases of forward, gradient, and recomputation (optional).
Four stages are executed in parallel on four IPUs.
After eight gradient computations, a gradient descent will be executed, that is, the weight will be updated once.
As for inference, we show equivalent programs that use pipelining for training, using TensorFlow 2 and the PipelineModel and PipelineSequential classes.
1from tensorflow.python.data.ops.dataset_ops import Dataset
2from tensorflow.python.ipu import utils
3from tensorflow.keras import layers
4from tensorflow.keras import optimizers
5from tensorflow.python.ipu import keras
6from tensorflow.python.ipu import ipu_strategy
7import numpy as np
8import tensorflow as tf
9
10# default data_format is 'channels_last'
11dataset = Dataset.from_tensor_slices(
12 (tf.random.uniform([2, 128, 128, 3], dtype=tf.float32),
13 tf.random.uniform([2], maxval=10, dtype=tf.int32))
14 )
15dataset = dataset.batch(batch_size=2, drop_remainder=True)
16dataset = dataset.shuffle(1000)
17dataset = dataset.cache()
18dataset = dataset.repeat()
19dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
20
21# Create a pipelined model which is split accross four stages.
22def my_model():
23 input_layer = layers.Input(shape=(128, 128, 3), dtype=tf.float32, batch_size=2)
24
25 with keras.PipelineStage(0):
26 partial = layers.Conv2D(3, 1)(input_layer)
27
28 with keras.PipelineStage(1):
29 partial = layers.Conv2D(3, 1)(partial)
30
31 with keras.PipelineStage(2):
32 partial = layers.Conv2D(3, 1)(partial)
33
34 with keras.PipelineStage(3):
35 partial = layers.Flatten()(partial)
36 logits = layers.Dense(10)(partial)
37
38 return keras.PipelineModel(input_layer,
39 logits,
40 gradient_accumulation_count=8,
41 )
42
43cfg = utils.create_ipu_config(selection_order=utils.SelectionOrder.ZIGZAG)
44cfg = utils.auto_select_ipus(cfg, 4)
45cfg = utils.set_recomputation_options(cfg)
46utils.configure_ipu_system(cfg)
47utils.move_variable_initialization_to_cpu()
48
49# Define the model under an IPU strategy scope
50strategy = ipu_strategy.IPUStrategy()
51with strategy.scope():
52 model = my_model()
53 model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizers.SGD(0.01))
54
55 model.fit(dataset, steps_per_epoch=2, steps_per_run=2)
And finally the PipelineSequential version, which differs from the above only in the definition of the model, as in the inference code examples.
1from tensorflow.python.data.ops.dataset_ops import Dataset
2from tensorflow.python.ipu import utils
3from tensorflow.keras import layers
4from tensorflow.keras import optimizers
5from tensorflow.python.ipu import keras
6from tensorflow.python.ipu import ipu_strategy
7import numpy as np
8import tensorflow as tf
9
10# default data_format is 'channels_last'
11dataset = Dataset.from_tensor_slices(
12 (tf.random.uniform([2, 128, 128, 3], dtype=tf.float32),
13 tf.random.uniform([2], maxval=10, dtype=tf.int32))
14 )
15dataset = dataset.batch(batch_size=2, drop_remainder=True)
16dataset = dataset.shuffle(1000)
17dataset = dataset.cache()
18dataset = dataset.repeat()
19dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
20
21# Create a pipelined model which is split accross four stages.
22def my_model():
23 return keras.PipelineSequential(
24 [[layers.Conv2D(3, 1)],
25 [layers.Conv2D(3, 1)],
26 [layers.Conv2D(3, 1)],
27 [layers.Flatten(), layers.Dense(10)]],
28 gradient_accumulation_count=8)
29
30cfg = utils.create_ipu_config(selection_order=utils.SelectionOrder.ZIGZAG)
31cfg = utils.auto_select_ipus(cfg, 4)
32cfg = utils.set_recomputation_options(cfg)
33utils.configure_ipu_system(cfg)
34utils.move_variable_initialization_to_cpu()
35
36# Define the model under an IPU strategy scope
37strategy = ipu_strategy.IPUStrategy()
38with strategy.scope():
39 model = my_model()
40 model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizers.SGD(0.01))
41
42 model.fit(dataset, steps_per_epoch=2, steps_per_run=2)
3.5. Optimising the pipeline
3.5.1. Recomputation
The Poplar SDK makes more efficient use of the valuable In-Processor-Memory by saving selected activation inputs, optimising on memory savings vs TFLOP expenditure with recomputation. The two figures below demonstrate this, showing how the subset of activation inputs that are saved can be used to recompute all the necessary activation history for the backward pass calculation of the weight updates, thus saving on memory usage.
To enable recomputation, use the tensorflow.python.ipu.utils.set_recomputation_options() function when configuring the device.
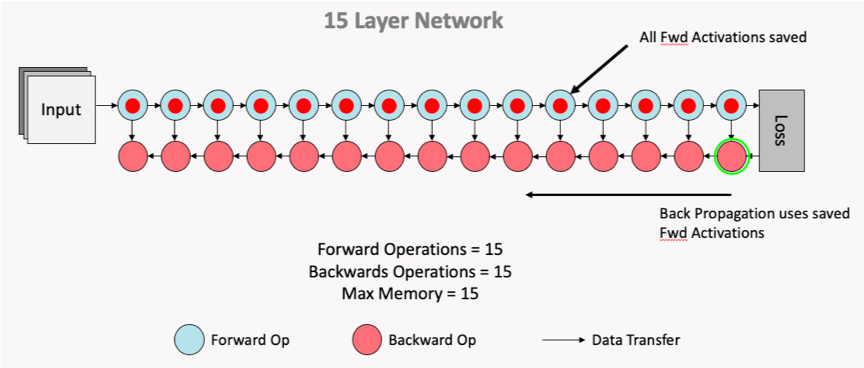
Fig. 3.6 Normal computation flow
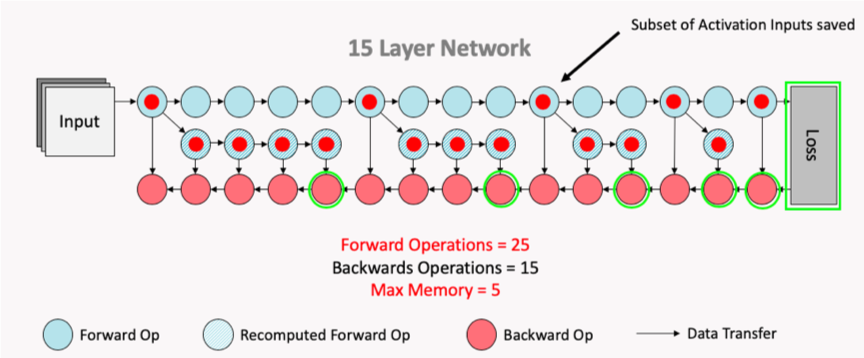
Fig. 3.7 Computation flow after recomputation enabled
3.5.2. Variable offloading
When using pipelining to train a model, it is possible to offload certain variables into Streaming Memory. This feature can allow savings of In-Processor-Memory memory, at the cost of time spent communicating with the host when the offloaded variables are needed on the device. The API supports offloading of the weight update variables and activations.
The weight update variables are any tf.Variable only accessed and modified during the weight update of the pipeline. An example is the accumulator variable of the tf.MomentumOptimizer. This means that these variables do not need to be stored in the device memory during the forward and backward propagation of the model, so when offload_weight_update_variables is enabled they are streamed onto the device during the weight update and then streamed back to Streaming Memory after they have been updated.
When offload_activations is enabled, all the activations for the batches which are not being executed by the pipeline stages at any given time are stored in the Streaming Memory. So in an analogous way as described above, when an activation is needed for computation it is streamed onto the device, and then streamed back to the Streaming Memory after it has been used.
3.5.3. Device selection order
Use the API to make sure the pipeline stage mapping to devices utilises the IPU-Links as much as possible.
3.5.4. Data parallelism
Pipelining supports replicated graphs. When using the pipeline operator, use the tensorflow.python.ipu.optimizers.CrossReplicaOptimizer in the optimiser function. When using the IPU Keras PipelineModel and PipelineSequential from within an IPUStrategy, replication is handled automatically whenever the model is placed on a multi-IPU device and the CrossReplicaOptimizer must not be used.
If the model you are working on is defined as using a batch size B and the gradient accumulation count is G and the replication factor is R, this results in an effective batch size of B x G x R.
Note that the all-reduce collectives for the gradients are only performed during the weight update.
3.5.5. Increase the gradient accumulation count
The bigger the gradient accumulation count:
The smaller proportion of time is spent during ramp up and ramp down.
The smaller proportion of time is spent during a weight update.
3.5.6. Profiling
When your model is executing correctly, you can try moving layers around, or if the model doesn’t fit in one or more IPUs you can try changing the available memory proportion.
Move layers towards the final computation stage to reduce the amount of recomputation
Adjust
availableMemoryProportion. For example:# Set "availableMemoryProportion" flag to "0.5" opts = create_ipu_config() opts = set_matmul_options(opts, matmul_options={"availableMemoryProportion": "0.5"}) ipu.utils.configure_ipu_system(opts)
More fine-grained control of the available memory proportion with the following options:
forward_propagation_stages_poplar_options: If provided, a list of length equal to the number of computational stages. Each element is aPipelineStageOptionsobject which allows for fine grain control of the Poplar options for a given forward propagation computational stage.
backward_propagation_stages_poplar_options: If provided, a list of length equal to the number of computational stages. Each element is aPipelineStageOptionsobject which allows for fine grained control of the Poplar options for a given backward propagation computational stage.
weight_update_poplar_options: If provided, aPipelineStageOptionsobject which allows for fine grained control of the Poplar options for the weight update stage.These can be useful in certain situations, for example if one stage is almost out of memory then the available memory proportion can be lowered there but not for the rest of the model.
Make sure that the
tf.Datasetpassed to the pipeline is not the bottleneck. See the Dataset benchmarking section in Targeting the IPU from TensorFlow for more information.Experiment with Poplar engine options. For example:
POPLAR_ENGINE_OPTIONS='{"opt.enableSwSyncs": ”true"}'