6. Integration with Slurm
6.1. Introduction
Slurm is a popular open-source cluster management and job scheduling system. For more information, refer to the Slurm Workload Manager Quick Start User Guide.
This section describes how to use V-IPU with Slurm for the different integration methods.
For information on configuring Slurm with V-IPU, refer to the Integration with Slurm section in the V-IPU Administrator Guide.
IPUs are not connected to a single host but instead they are connected to all hosts via the host fabric. In the resulting setup (Fig. 6.1), all hosts can use all IPUs and all IPUs are connected.
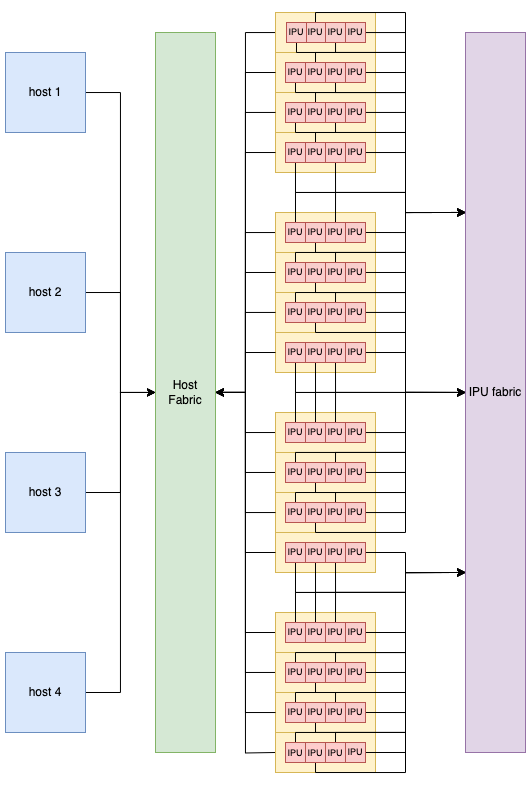
Fig. 6.1 Example topology for an IPU POD64.
This disaggregated representation poses a significant challenge for integration with Slurm and its node-centric view of cluster resources. This section describes three methods for integrating IPUs with Slurm.
6.1.1. Cluster setup
IPU-Machines are connected via the host through the host-fabric to a VM or to bare metal Poplar and Control hosts. The controller part can run on one of the Poplar hosts (for example Poplar host 1). Fig. 6.2 shows a separate control host for clarity; it is not mandatory.
For more information on cluster setup, refer to the V-IPU Administrator Guide.
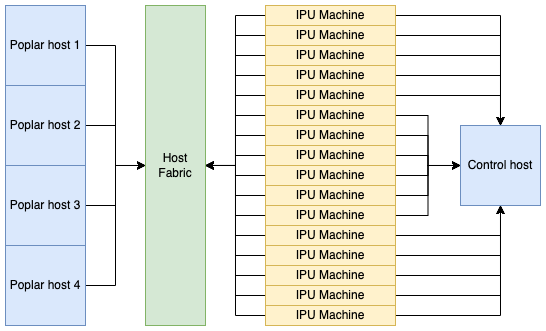
Fig. 6.2 Example logical topology of an IPU‑POD64.
6.2. Overview of integration options
There are four options for integrating V-IPU with Slurm:
The pros and cons of each option are summarised in Table 6.1.
Integration options |
Pros |
Cons |
|---|---|---|
Host-IPU mapping |
|
|
Preconfigured multiple static partitions |
|
|
Single preconfigured reconfigurable dynamic partition |
|
|
Graphcore-modified Slurm with IPU resource selection plugin |
|
|
6.3. Host-IPU mapping (recommended)
Jobs can be submitted using standard Slurm tools (salloc, srun, sbatch) and the number of hosts determines the IPU count. Partitions are configured to guarantee that a single job has exclusive node access. The exclusive node access is needed because when another job is allowed to use the same node, it will compete for IPUs and one or both the jobs will fail due to lack of resources.
See Host-IPU mapping (recommended) in the V-IPU Administrator Guide for more information about how to configure this method.
#!/bin/bash
# run job on pod16 pick any node, no need for constraint
# Number of processes is minimal, number of nodes is exact
srun -N1 -n1 -ppod16 "$@"
# run job on pod32
# constraint will pick 2 nodes having one of pod32-. features
# which will guarantee adjacent nodes to be picked
srun -N2 -ppod32 -n2 --constraint='[pod32-3|pod32-1|pod32-2|pod32-0]' "$@"
# run job on pod64 pick all nodes, no need for constraint
srun -N 4 -ppod64 -n4 "$@"
# salloc and sbatch should follow the same schema
6.4. Preconfigured partition: multiple static partitions
Using multiple static partitions adds user separation but having non-reconfigurable partitions will waste resources. Also, the user can only request allowed partitions.
See Preconfigured partition: multiple static partitions in the V-IPU Administrator Guide for more information about how to configure this method.
Use predefined GRES values for preconfigured partitions. Otherwise any standard Slurm options can be used.
srun --gres vipu:1 -p ipu job # it will wait for resource forever
# copy work to dir shared to compute nodes
sbatch --gres vipu:4 -p ipu --requeue job_script
6.5. Preconfigured partition: single reconfigurable dynamic partition
Using a single reconfigurable dynamic partition is the most straightforward solution for integration of IPUs with Slurm, but it sacrifices security for simplicity and has other severe limitations (Section 5, Partitions).
See Preconfigured partition: single reconfigurable dynamic partition in the V-IPU Administrator Guide for more information about how to configure this method.
To schedule a job to run on IPUs, the user needs to choose proper nodes or Slurm partitions.
srun -p ipu job
# copy work to dir shared to compute nodes
sbatch -p ipu --requeue job_script
6.6. Graphcore-modified Slurm with IPU resource selection plugin
A Slurm plugin is a dynamically linked code object providing customized implementation of well-defined Slurm APIs. Slurm plugins are loaded at runtime by the Slurm libraries and the customized API callbacks are called at appropriate stages.
Resource selection plugins are a type of Slurm plugin which implement the Slurm resource/node selection APIs. The resource selection APIs provide rich interfaces to allow for customized selection of nodes for jobs, as well as performing any tasks needed for preparing the job runs (such as partition creation in our case), and appropriate clean-up code at job termination (such as partition deletion in our case).
6.6.1. Job submission and parameters
The V-IPU resource selection plugin supports the following options:
--ipus: Number of IPUs requested for the job-n/--ntasks: Number of tasks for the job. This will correspond to the number of GCDs requested for the job partition.--num-replicas: Number of model replicas for the job.
These parameters can be configured in both sbatch and srun scripts as well as provided on the command line:
$ sbatch --ipus=2 --ntasks=1 --num-replicas=1 myjob.batch
Optional:
If V-IPU GRES has been configured, you can add the following option in the job definition to select a particular GRES model for the V-IPU.
--gres=vipu:<type name>
You can configure the GRES model parameter in both sbatch and srun scripts as well as on the command line.
Assuming the desired GRES model to be used is pod64, the command should look like:
$ sbatch --ipus=2 --ntasks=1 --num-replicas=1 --gres=vipu:pod64 myjob.batch
6.6.2. Job script examples
The following is an example of a single gcd job script:
#!/bin/bash
#SBATCH --job-name single-gcd-job
#SBATCH --ipus 2
#SBATCH -n 1
#SBATCH --time=00:30:00
srun <ipu_program>
wait
You can configure a multi-GCD job in the same way, except for indicating the number of GCDs requested by setting the number of tasks:
#!/bin/bash
#SBATCH --job-name multi-gcd-job
#SBATCH --ipus 2
#SBATCH -n 2
#SBATCH --time=00:30:00
srun <ipu_program>
wait