4. Programming tools
The Poplar software stack is shown in Fig. 4.1. This supports programming the IPU at multiple levels from high-level machine-learning frameworks to writing applications directly for the IPU in C++ and assembly language.
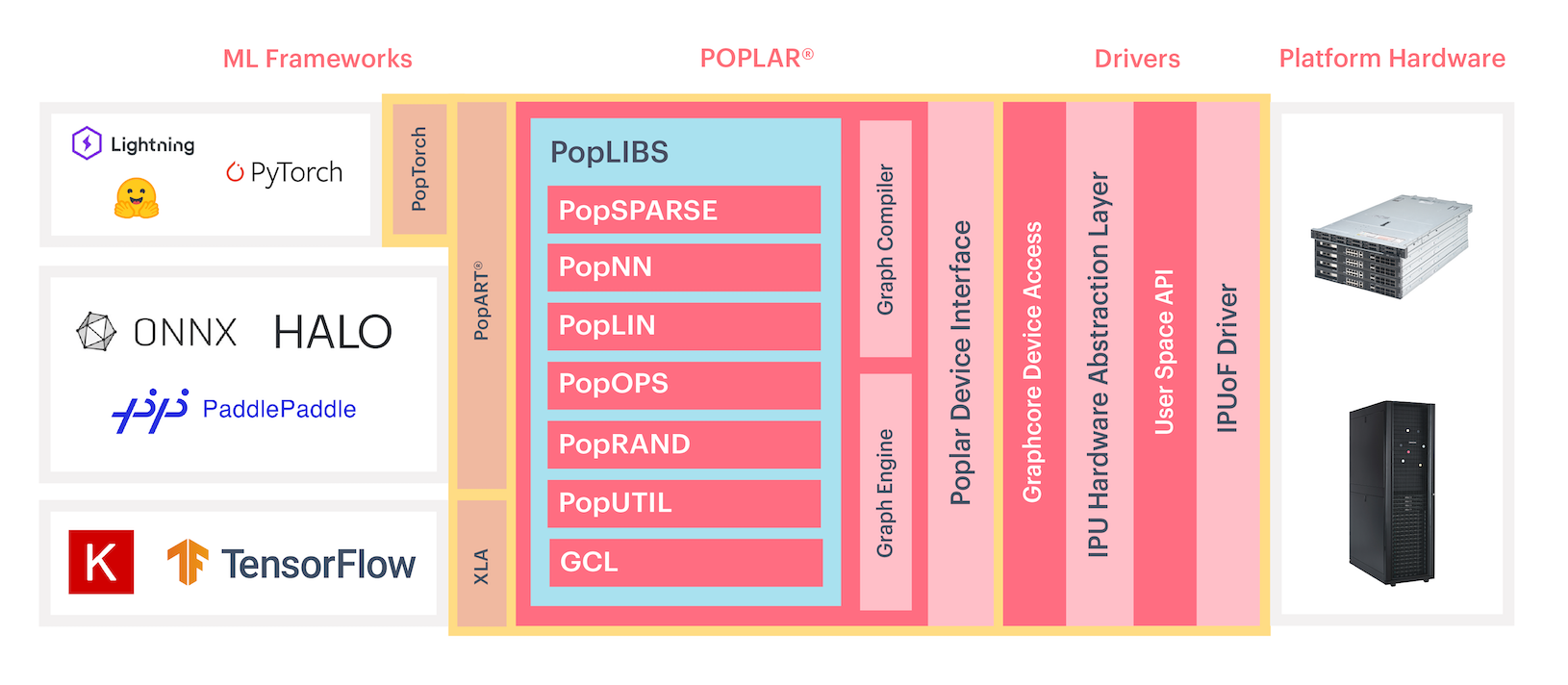
Fig. 4.1 Poplar software stack
4.1. Using a machine learning framework
At the highest level of abstraction, you can use standard ML frameworks such as TensorFlow, PyTorch and Keras to generate code to run on the IPU. This allows existing code to be run largely unchanged. You can then optimise the code to take advantage of the parallel execution and other features of the IPU.
As an example, the code snippet in Listing 4.1 shows sample TensorFlow code running on IPUs. The IPU-specific parts of the code are solely for selecting and configuring the IPU.
def model_fn():
# Input layer - "entry point" / "source vertex".
input_layer = keras.Input(shape=input_shape)
# Add layers to the graph.
x = keras.layers.Conv2D(32, kernel_size=(3, 3), activation="relu")(input_layer)
x = keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu")(x)
x = keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dropout(0.5)(x)
x = keras.layers.Dense(num_classes, activation="softmax")(x)
return input_layer, x
ipu_config = ipu.config.IPUConfig()
ipu_config.auto_select_ipus = 1
ipu_config.configure_ipu_system()
strategy = ipu.ipu_strategy.IPUStrategy()
with strategy.scope():
model = keras.Model(*model_fn())
# Compile our model with Stochastic Gradient Descent as an optimiser
# and Categorical Cross Entropy as a loss.
model.compile('sgd', 'categorical_crossentropy', metrics=["accuracy"])
model.summary()
print('\nTraining')
model.fit(x_train, y_train, epochs=3, batch_size=batch_size)
model.compile('sgd', 'categorical_crossentropy', metrics=["accuracy"])
print('\nEvaluation')
model.evaluate(x_test, y_test, batch_size=batch_size)
print("Program ran successfully")
Graphcore provides TensorFlow and PyTorch implementations that allows you to write code in those frameworks.
In addition to TensorFlow and PyTorch, the PopART Python libraries provide a framework to import ONNX models or to write custom IPU-optimised model code to run on IPUs.
For more information, refer to the TensorFlow 1, TensorFlow 2, PyTorch and PopART user guides.
4.2. Writing IPU programs directly
In addition to using an ML framework to run code, you can write applications that directly create programs to run on the IPU.
Programs are written using the Poplar graph libary (libpoplar) which allows
C++ applications to build programs for the IPU, compile and run them.
Code written using Poplar consists of two parts. The first part is the main application that will build programs to run on the IPU:
...
Tensor v1 = graph.addVariable(FLOAT, {4}, "v1");
Tensor v2 = graph.addVariable(FLOAT, {4}, "v2");
...
Sequence prog;
prog.add(Copy(c1, v1));
...
// Create a compute set and add its execution to the program
ComputeSet computeSet = graph.addComputeSet("computeSet");
for (unsigned i = 0; i < numTiles; ++i) {
VertexRef vtx = graph.addVertex(computeSet, "SumVertex");
graph.connect(vtx["in"], v1.slice(i, 4));
graph.connect(vtx["out"], v2[i]);
graph.setTileMapping(vtx, i);
graph.setPerfEstimate(vtx, 20);
}
prog.add(Execute(computeSet));
The second part is the vertex code that contains the code that runs on vertices within compute sets:
#include <poplar/Vertex.hpp>
using namespace poplar;
class AdderVertex : public Vertex {
public:
Input<float> x;
Input<float> y;
Output<float> sum;
bool compute() {
*sum = x + y;
return true;
}
};
The PopLibs library (included in the Poplar SDK and also available on GitHub) contains many predefined functions such as linear algebra operations, element-wise tensor operations, non-linearities and reductions written in C++ using the Poplar libraries.
For more information on both writing programs that run on the IPU and writing vertex code, refer to the Poplar and PopLibs User Guide.
4.3. Adding custom operations to ML frameworks
When running on the IPU, ML frameworks such as TensorFlow and PyTorch allow you to add operators to the high-level framework computational graph that are implemented specifically for the IPU using the Poplar graph library described in the previous section. The technical note Creating Custom Operations for the IPU contains more information.
4.4. Compilation
Whether you use ML frameworks or you write direct Poplar programs, the whole program is always fully compiled. In TensorFlow, PyTorch and Poplar, the compilation step will happen after the computational graph is created and before execution.
Since the whole program is compiled, there will be a delay in the host program when compilation occurs which for large programs may be several minutes. This allows many program optimisations but needs to be factored into the workflow of the host application.
All the frameworks and Poplar provide methods to store a compiled program to disk and reload at a later time to avoid the repeated cost of compilation. For example, this technical note describes some strategies that can help you avoid recompilation in TensorFlow.
4.5. Executing programs
Programs are run on the IPU by either running the Python script in the ML framework or by running the host application that uses the Poplar graph library. These applications on the host will compile and run the IPU programs in conjunction with the host.
If the program uses replication (Section 5.1, Replication), then the
poprun utility supplied with the Poplar SDK may be used to launch multiple
instances of a host program which share multiple IPUs between them. Refer to the
PopDist and PopRun User Guide for more details.
4.6. Profiling and analysing programs
When a program is run, you can enable collection of profiling information during compilation and execution. PopVision™ is a suite of graphical application-analysis tools. You can download these from the PopVision tools web page. There are two tools which can show information about the breakdown of time and memory on the IPU.
The PopVision Graph Analyser shows the memory information and execution information of the program that has run on the IPUs. Refer to the PopVision Graph Analyser User Guide for more details.
The PopVision System Analyser shows the event trace of execution and communication events involving the host and the IPUs (execution start, data stream transfer and so on). Refer to the PopVision System Analyser User Guide for more details.
4.7. Further Reading
Switching from GPUs to IPUs for Machine Learning Models provides a high-level overview of the programming changes required when switching from GPUs to IPUs.
The Graphcore GitHub Examples repository includes tutorials, examples and complete sample applications for the IPU.
There is also source code for the IPU port of TensorFlow, PopTorch, PopART and the PopLibs libraries.