2. Model Runtime under the hood
This chapter briefly introduces the general concepts of running the model on the IPU, introducing the main Model Runtime components and their responsibilities in the whole process.
2.1. Finding hardware
The user can provide any possible computation model (with its full
definition is stored in the PopEF) and the first step is to figure out what hardware
resources need to be provided (namely the number of the IPU accelerators, their generation and supported features) and if such hardware is available in the
user’s system. The Model Runtime model_runtime::DeviceManager class lets the user pick a model_runtime::Device suitable for the model and to specify the exact characteristics the device must satisfy.
2.2. Data transfers
The user model compiled into the Poplar executable (stored as PopEF) needs to be transferred to the IPU. This is the first data transfer step. For regular model execution, the model inputs have to be sent from the host to the IPU and the model outputs have to be fetched back from the IPU to the host.
To gather up and control all the data streaming duties, Model Runtime provides a
set of tools dedicated for these tasks contained in the Session class. The Session
API includes several complex operations taking place under the hood; it
also provides verification of the model parameters by providing wrappers for
components functionalities.
2.3. Executable upload
To upload the model executable onto the device, Session uses the Model Runtime Executable object to deserialize the model from the PopEF and finally load it onto the IPU.
In most cases the user model consists of at least three types of programs:
Load: for uploading weights or other constants to the IPU memory. This is supposed to be executed once before the first
Mainprogram callMain: the model computational graph implementation
Save: used to transfer the selected tensors data back to the host. This program is unused in most inference use cases.
Executable provides an API for controlling the execution (run, stop) of these programs.
2.4. Tensor data
Every model operates on data, which can be provided in different ways:
In the case of model weights, or other model constants, values may be compiled into the executable. This means that all information is transferred to the IPU in one step.
Another option is to store the data in PopEF’s TensorData. In this case, Model Runtime needs to set up the transfer of data to the device before the first model execution (to be precise: a Poplar Engine stream gets connected to proper PopEF
TensorDatawhich creates a direct data transfer channel operated by Poplar).The last option is data provided explicitly by the user. This may be used for overriding
TensorDataand is the general way to provide regular model inputs.
Each logical model constant/variable/input/output data is organized in the form of a tensor and its transfer can be managed by the internal tensor manager object.
2.5. Managing the data sources/targets
To create data transfer channels between the user program and the IPU device,
Model Runtime utilizes Poplar’s mechanism of asynchronous data feed functions
- callback.
During model execution, when the data transfer step is to be triggered, the IPU
communicates with the Poplar runtime to initiate the transfer. It then calls the
proper callback and passes to it the pointer to the memory where the target Tensor
bytes are to be put (input Tensor) or where it can be fetched from (output
Tensor). This call is blocking so Poplar needs to receive the data to continue with execution.
There are generally two sources of data for a model Tensor: PopEF’s TensorData that stores their values and data provided directly by the user.
The Session internal Tensor manager prepares and connects all the callbacks
responsible for transferring the PopEF TensorData (if there
is any and if the user did not exclude any or all of them from this auto-binding
using the predicates mechanism).
When it comes to other data (both inputs and outputs) to be transferred
explicitly by the user and not coming directly from PopEF itself, Session
provides an interface to setup the connections. How the user data is queued to
provide the best possible performance (in the general case) is the responsibility of QueueManager. To simplify the creation and basic configuration of QueueManager, Session provides a factory method
(createQueueManager()) that constructs an object of the class QueueManager and
registers itself in that object.
2.6. Queues of data
A naive strategy of simple serialization of the model execution stages are: prepare input, send the input to the IPU, wait for the output, fetch it from the device, repeat if not sufficient enough to achieve good model execution performance in real life applications.
As the processes of preparing user data and model execution on the IPU may be
pipelined, QueueManager provides a mechanism of buffering user inputs and outputs. The tensors in the queue may be inputted and fetched
asynchronously, so that the user program can prepare inputs in parallel (if
possible) and add them to the queue. At the same time, but independently, the IPU keeps fetching the consecutive inputs, and fills the output queues with
computations results.
The QueueManager API provides access to the lists of input and output queues. In this
way, the user can enqueue data to/from the queues providing pointers to the user-managed memory where the data resides or is to be downloaded to. In this this way Model Runtime avoids extra copying. Data gets transferred to the device from the user memory (or the other way round) exactly when it’s needed by the IPU (or when ready for writing back to the user). In this process, the only blocking factor is the lack of data in the queue, which means that the user is not able to provide the data at a fast enough rate to keep the IPU busy all the time.
2.7. Buffers
QueueManager does not store the tensor data buffers, but instead stores pointers to them (plus some other metadata). Even though this is a sort of “light data”, operations on the queues are very frequent, so the extra cost of adding elements to them and removing elements from them should be as low as possible and preferably state-invariant.
Due to the identified requirements, QueueManager organizes tensor queues in the form of ring buffers. Each Tensor has a dedicated constant size buffer that gets filled with data up to its capacity and drained in the same order (FIFO). When
the last cell in the queue gets filled, the algorithm starts to use up the data from the very beginning of the queue. Since this is an asynchronous process, while user enqueues more tensors, the IPU keeps consuming them.
The RingBuffer class is a Single Producer - Single Consumer thread-safe structure. As there is only one user of the buffer (QueueManager) that can access it in asynchronous manner, this profile provides
the suitable level of safety, without too much impact on performance.
2.8. Conditional execution
When one compiled graph contains one model, you must provide data for all input and output
anchors for correct execution of the graph on the IPU. This is the default execution for a
ModelRunner object. Sometimes, a graph compiled by Poplar can
contain multiple models (Fig. 2.1). In this case, the IPU will
conditionally execute one of these models based on an input parameter (specified in an input
anchor) that manages the selection of the appropriate execution path. In order to execute
different models through one ModelRunner instance, you are
expected to provide only data for anchors that will be required by the IPU to perform the
request.
There are two steps you must perform:
The
validate_io_paramsoption should be disabled. This option checks if you have provided enough input parameters to complete the request. In other words, it checks whether each parameter corresponds to an existing internal queue. By disabling it, you will be able to only provide inputs for the model you want to execute and not all models.You must know which anchors are associated with each model in the graph. When you send a request, you need to provide the data only required by the model you want to execute. The PopEF file contains information about what anchors the graph contains, but it does not contain information about which anchors are associated with a model. You can use the popef_dump tool to check what anchors are in the graph.
Note
If you provide inputs for a different model than the one you want to execute, then a timeout will occur. This will be the only information you will receive in case of incorrect execution of the request.
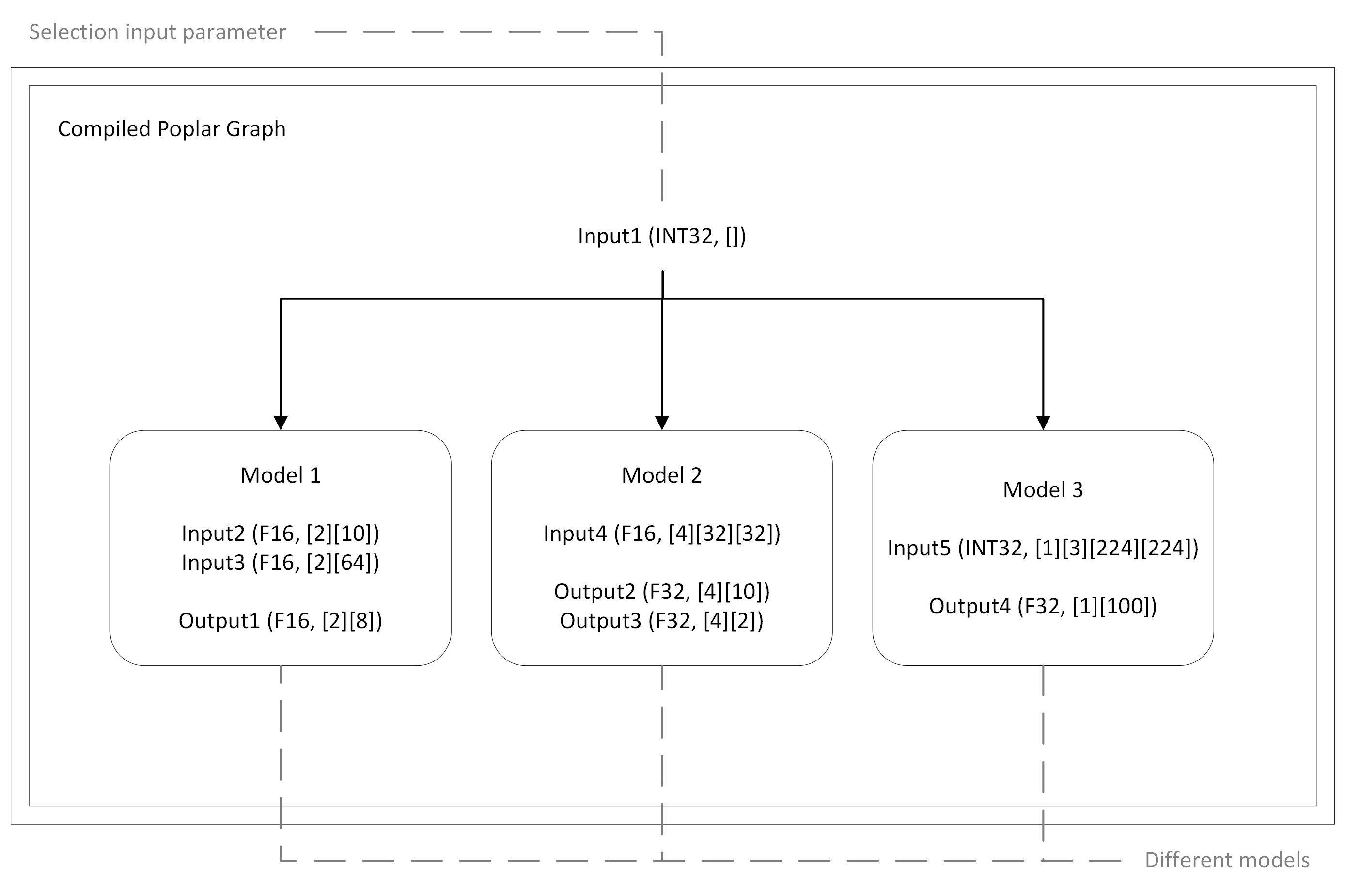
Fig. 2.1 An example graph construction with multiple models
2.9. Dynamic batch sizing
By default, ModelRunner only accepts model inputs and outputs with batch sizes that are an integer multiple of the batch size from the PopEF model. By setting the batching_dim configuration option, you can enable dynamic batch sizing which allows you to specify any batch size.
By default, dynamic batch sizing is disabled (batching_dim == 0xFFFFFFFF). In this case, the batch size must be an integer multiple of the batch size from the PopEF model. For example, without dynamic batch sizing enabled and for a PopEF model with an input shape of [3, 4, 2] where dimension 0 specifies the batch size, ModelRunner can only accept inputs with shapes defined by [ N * 3, 4, 2], (where N is any positive integer).
To enable dynamic batch sizing, we set batching_dim to the dimension that contains the value for the batch size. batching_dim can be [0, 1, 2, ... , max_dimension_model-1].
For example to enable dynamic batch sizing on dimension 1, you would set batching_dim == 1. Now dimension 1 can contain any batch size. Using the example from earlier, ModelRunner can service inference requests with input and output shapes [4, batch_size, 2] where batch_size is any positive integer.