2. PopEF file format
Serialized AI models to be run on an IPU can be broken down into several components. Each of these elements is called a blob and can be read and written. The supported blob types are:
Each of these blobs are separate and independent components that together form a complete model. Since these blobs are independent, it means that it is possible to bind multiple blobs together into the model. Furthermore, the structure of blobs allows several files to be used to create a single model, or for many models to be stored in a single file. This chapter describes each blob type in detail. Fig. 2.1 shows an overview of PopEF.
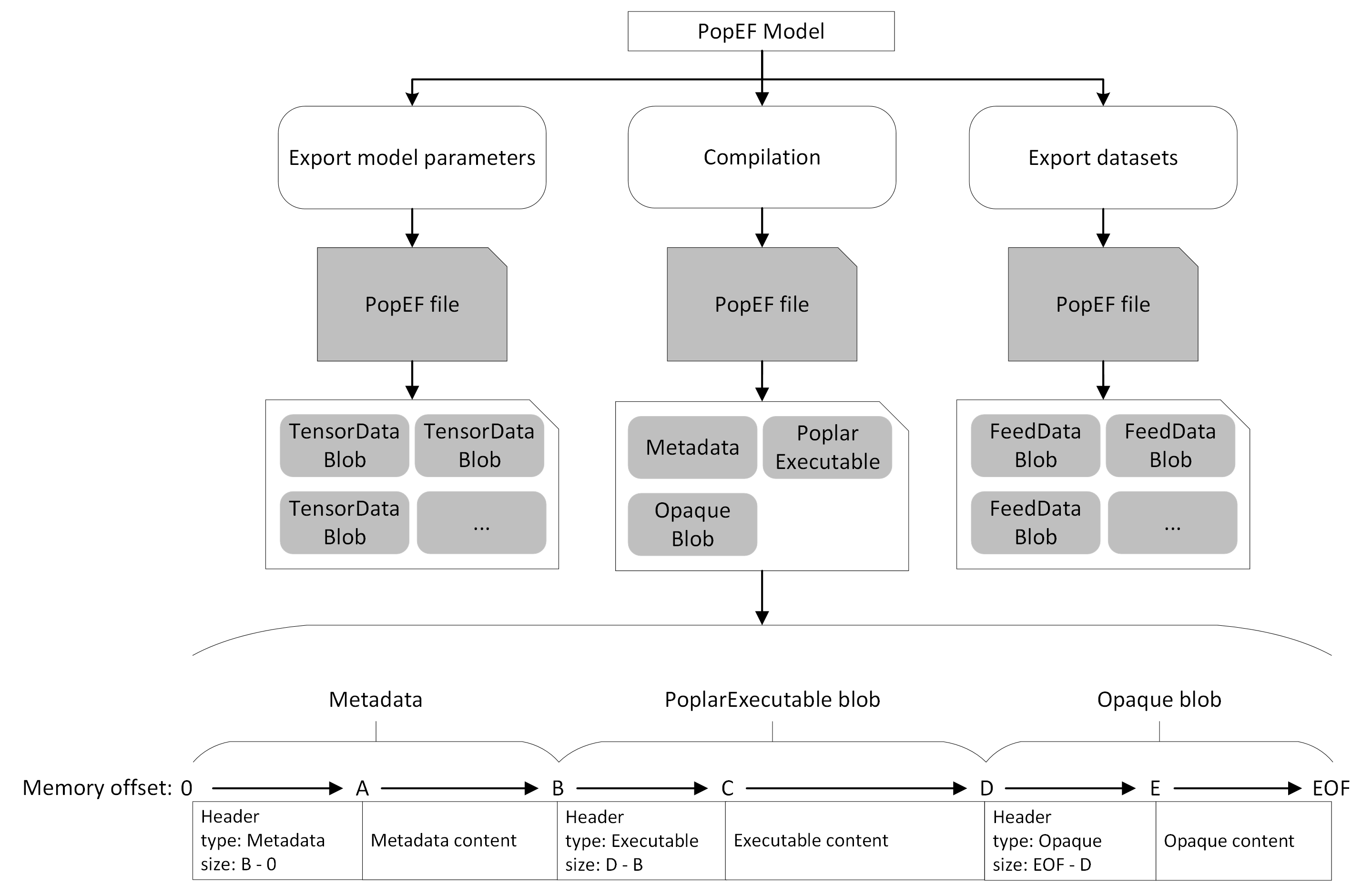
Fig. 2.1 PopEF overview
2.1. Blob header
At a high-level, a PopEF file is simply a list of blobs, each of which starts with a blob header.
Each header contains:
A version string used by the consumer to assess how to handle the blob.
The blob type defined by the
BlobTypeenum:The total blob size as an integer value. This is the size of the header together with the size of blob content.
A very basic PopEF consumer can list the contents of a file by parsing the first
blob header, then jumping to the next header using the size field from the
first header and repeating this until it reaches the end of the file. An example of a PopEF file structure is shown in Fig. 2.2.

Fig. 2.2 PopEF file structure
2.2. Poplar executable
The Poplar executable blob contains a serialised poplar::Executable.
Poplar executable blobs are identified by a name which is used to link them to other
blobs (Metadata or Opaque blobs), and therefore the name field cannot be
empty and must be unique among all the blobs of type POPLAR_EXECUTABLE.
Warning
The Poplar library does not guarantee compatibility in a situation where the executable has been exported from a Poplar version different to the target runtime (there is no backward compatibility). In other words, you must use the same version of the Poplar library when exporting, importing and running the model to make sure your program works correctly.
Note
The Poplar executable blob can take up a relatively large amount of disk space.
You can use createExecutable() to compress this blob when creating it.
2.3. Metadata
Metadata blobs contain the information necessary to load and run a Poplar executable. Metadata contains the following:
Name of the executable which is stored in the
executablefield.The target runtime.
The program flow.
Anchors.
2.3.1. Target runtime
The metadata contains information about the model execution target. This includes the number and version of IPUs used by the model. In addition, the data includes options for the Poplar library and devices.
2.3.2. Program flow
Poplar executables are organised as a vector of runnable programs that can be grouped into “program flows”.
The number of programs present in an executable and what they do depend on the framework which created them. It can also depend on if you wrote the model yourself, using for example the Poplar API.
Typically, for an inference model there will be at least one program to upload the weights from the host to the target (which should be called once at the beginning), and the main program that uploads some inputs to the target, runs the model and downloads the outputs back to the host.
The following pseudocode illustrates the data use in the program flows.
model = loadFromFile(filename)
# Transfer the weights to the IPU
model.runLoad()
for input in inputs:
# Run the model and transfer the output back to the host.
output = model.runMain(input)
Information about the specific programs which need to be called as part of load and main is captured in the ProgramFlow class.
2.3.3. Anchors
A Poplar program doesn’t accept inputs and doesn’t return outputs, instead it exposes a list of string handles which the runtime needs to
connect callbacks to. These string handles are stored in “anchors”. The Anchor class allows you to manage model inputs
and outputs and contains all necessary information needed about the input or output tensor, for example:
The name of the tensor. This is stored in the
namefield and is a human-readable string. Typically, this name comes from the original high-level model (for example,model.layer.weightsormodel.layer.bias).The handle name, which refers to the callback that you must define to send data to and receive data from the program. At runtime, when Poplar encounters one of these handles as part of a program, it will call the callback function with a pointer.
The set of programs in which the tensor is used.
The tensor shape and its data type.
Information whether this is an input tensor or an output tensor. In other words, should we copy from or to the pointer we receive in the callback.
Information whether the tensor contains different data in different replicas.
Information whether the tensor should be copied to the remote buffer (memory outside the IPU that can be read and written to by the IPU) as well as how many repeat blocks should be transferred (the remote buffer can store multiple blocks of the same size).
Anchors can be associated with Tensor data blobs or Feed data blobs based on the anchor name. In this
case, the data can be delivered to the model based on the data contained in the blob.
Otherwise, you must remember to provide your data for the program when executing
the model, because the anchor only contains information about the tensor
and does not contain any of its data.
Note
Using replication and remote buffers can affect the shape inside the
TensorInfo object of a given Anchor tensor. All unique replicas and repeat
blocks must be placed in one memory block. A single tensor shape may be
implicitly extended by two outer dimensions replication_factor and
repeats, as follows:
If
use_remote_buffersis set toTrueandrepeatsis greater than 1, arepeatsdimension is added.If
is_per_replicais set toTrueandreplication_factoris greater than 1, areplication_factordimension is added.The
replication_factordimension always precedes therepeatsdimension.
Examples:
Configuration: tensor_shape={8, 3, 1},
use_remote_buffers= True,repeats= 3,replication_factor= 2,is_per_replica= TrueResult:
TensorInfo{shape={2, 3, 8, 3, 1}}Configuration: tensor_shape={8, 3, 1},
use_remote_buffers= True,repeats= 3,replication_factor= 1,is_per_replica= TrueResult:
TensorInfo{shape={3, 8, 3, 1}}Configuration: tensor_shape={8, 3, 1},
use_remote_buffers= True,repeats= 3,replication_factor= 2,is_per_replica= FalseResult:
TensorInfo{shape={3, 8, 3, 1}}Configuration: tensor_shape={8, 3, 1},
use_remote_buffers= False,repeats= 1,replication_factor= 1,is_per_replica= FalseResult:
TensorInfo{shape={8, 3, 1}}Configuration: tensor_shape={8, 3, 1},
use_remote_buffers= False,repeats= 3,replication_factor= 2,is_per_replica= TrueResult:
TensorInfo{shape={2, 8, 3, 1}}Configuration: tensor_shape={8, 3, 1},
use_remote_buffers= True,repeats= 1,replication_factor= 2,is_per_replica= TrueResult:
TensorInfo{shape={2, 8, 3, 1}}
The number of input elements obtained each time you call the model will be:
For training:
device_iterations * replication_factor * batch_size * gradient_accumulationFor inference:
device_iterations * replication_factor * batch_sizewhere
batch_size(the micro-batch size) is the outermost dimension in the unextended tensor_shape.For example, if TensorInfo{shape=[2, 8, 3, 1]},
replication_factor= 2,is_per_replica= True anddevice_iterations= 10 then the number of input elements for inference will be10 * 2 * 8.
2.4. Tensor and feed data
The data needed to run a model can be stored in two different structures:
TensorDataInfo: A single data item for a single tensor, usually used for model parameters (for example model weights).FeedDataInfo: Multiple data items for a single tensor, usually used for model inputs (for example an image set).
FeedDataInfo contains information of how many tensors are in the block.
In other words, how many inputs for a model can be provided.
For each each tensor, FeedDataInfo contains a unique name, so that the data can be associated
with the anchor in the metadata. In addition, FeedDataInfo contains the tensor shape, and data type.
The available data types are shown in Table 2.1.
|
boolean |
|
16-bit floating point |
|
32-bit floating point |
|
64-bit floating point |
|
8-bit signed integer |
|
8-bit unsigned integer |
|
16-bit signed integer |
|
16-bit unsigned integer |
|
32-bit signed integer |
|
32-bit unsigned integer |
|
64-bit signed integer |
|
64-bit unsigned integer |
Both these structures (TensorDataInfo and FeedDataInfo) are immediately followed by the actual data.
The size of this data must match exactly the size of the shape described
by TensorInfo (no padding) multiplied by the number of tensors for
the feeds (no gap between tensors).
Fig. 2.3 shows the arrangement of the data described above in the blob.
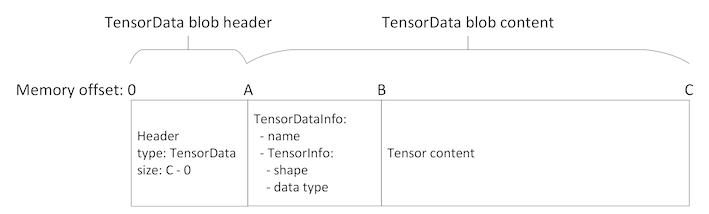
Fig. 2.3 Tensor data structure format
2.5. Opaque
Opaque blobs can be considered to be a “black box”. They can contain any information. Usually, they are used to store binary framework-specific information. They can usually only be interpreted by the framework that created them. An exception to this rule is the inference use case. Triton Server which is supported by the Poplar Triton Backend and Model Runtime are framework agnostic, which means that it doesn’t matter which framework exported the model, it can be used anyway. This assumes that all the functionality of the model is enclosed in a Poplar executable blob and there are no pre- or post- Poplar executable execution steps defined in, for example, a TensorFlow model.
Opaque blobs are used to help frameworks transition from fully opaque formats to a shared framework-agnostic format. Frameworks can use opaque blobs to store data which is not supported by PopEF.
Opaque blobs are identified by the name field (usually the name of the
framework which generated them) and are linked to the given Poplar executable.
2.6. PopEF file analysis
The Poplar SDK includes the popef_dump tool. This allows you to analyze a PopEF
file without using the C++ or Python API. It shows the file structure and
indicates which blobs are included, with basic information about each blob
(it displays all the information in the case of a Metadata blob). However,
it does not allow you to view the binary content of the blobs.
The popef_dump tool allows you to read several files at the same time.
popef_dump has the following syntax:
popef_dump [options] <popef file path> [<popef file path>]...
The available popef_dump options are
--allDisplay all the PopEF information listed below.
-m [ --metadata ]Display the content of
Metadatablobs. Metadata blobs contain the information necessary to load and run a Poplar executable.-a [ --anchors ]Display information for anchors. This includes string handles that the runtime needs to connect callbacks to. Anchors contain all the necessary information to allow you to manage model inputs and outputs.
-u [ --user-anchors ]Display user-provided inputs and outputs. That is, a list of the anchors that are not associated with either Tensor data or Feed data blobs. In these cases, you must provide that data for the program when executing the model, because the anchor only contains information about the tensor and not any of its data.
-e [ --execs ]Display information for Poplar executable blobs. These blobs contain a serialised Poplar executable.
-t [ --tensors ]Display information for Tensor data blobs. A Tensor data blob contains data for one tensor, usually used for model parameters (for example model weights). The Tensor data blob size in bytes is equal to the number of tensor elements multiplied by the data type size.
-f [ --feeds ]Display information for Feed data blobs. A Feed data blob contains multiple tensors for one input anchor, usually used for model inputs (for example an image set). The Feed data blob size in bytes is equal to the number of tensors in the blob multiplied by the number of tensor elements and the data type size. If the number of tensors in a Feed data blob is larger than the corresponding anchors’s batch_size, the executable will have to be run multiple times to consume all the data from the Feed data blob.
-o [ --opaques ]Display Opaque blob information. An Opaque blob can contain any data. Usually, they are used to store binary framework-specific information. They can usually only be interpreted by the framework that created them.
-c [ --color ]Use colour formatting.
-v [ --verbose ]Set the logging level to “DEBUG” for the PopEF library.
-h [ --help ]Print help message.
In Listing 2.1 and Listing 2.2 the popef_dump output, the
PopART framework
was used to generate the PopEF file. The model contained in the PopEF file
implements the following computation:
Add:0 = user_input + input_parameter
Each of the above tensors is a float32 two-element vector. input_parameter
is a model parameter supplied by the Tensor data blob.
user_input is the input you provided and tensor Add:0 is the
model output.
$ popef_dump -a -t -e -o executable.popef
PopEF file: executable.popef
Anchors:
Inputs (User provided):
Name: "user_input":
TensorInfo: { dtype: F32, sizeInBytes: 8, shape [2] }
Programs: [5]
Handle: h2d_user_input
IsPerReplica: True
Inputs (Popef provided):
Name: "input_parameter":
TensorInfo: { dtype: F32, sizeInBytes: 8, shape [2] }
Programs: [0]
Handle: h2d_input_parameter
IsPerReplica: False
Outputs (User provided):
Name: "Add:0":
TensorInfo: { dtype: F32, sizeInBytes: 8, shape [2] }
Programs: [5]
Handle: anchor_d2h_Add:0
IsPerReplica: True
Outputs (Popef provided):
Name: "input_parameter":
TensorInfo: { dtype: F32, sizeInBytes: 8, shape [2] }
Programs: [7]
Handle: weight_d2h_input_parameter
IsPerReplica: False
Executables:
Name: "3284579348837926701":
Is compressed: False
Version:
Available read size: 63682
Tensors:
Name: "input_parameter":
Version:
Available read size: 16
TensorInfo: { dtype: F32, sizeInBytes: 8, shape [2] }
Opaques:
Name: "popart":
Executable: 3284579348837926701
Version:
Available read size: 1536
$ popef_dump -m executable.popef
PopEF file: executable.popef
Metadata:
Version:
IpuVersion: 2
Executable: 3284579348837926701
Replication Factor: 1
NumIpus: 1
SeedHandle:
IsInference: True
IsPOD: False
NumProcesses: 1
DeviceIterations: 1
Engine Options:
debug.retainDebugInformation: true
exchange.enablePrefetch: true
exchange.streamBufferOverlap: hostRearrangeOnly
target.deterministicWorkers: false
Program Flow:
load: [0, 1]
main: [5]
save: [7]
Programs Map:
0: WeightsFromHost
1: OptimizerFromHost
2: RandomSeedFromHost
3: RandomSeedToHost
4: RngStateFromHost
5: Program
6: RngStateToHost
7: WeightsToHost
8: CycleCountTensorToHost
9: CustomProgramsStart
Device Options: <empty>