5. Vertex vector types
The fields of a Vertex can include Vector<T> or VectorList<T>
types, or a combination of those such as Vector<Input<Vector<T>>>, in its
state fields. These are similar to std::vector but can have different
layouts in memory, optimised for the tile architecture.
These types are documented in the runtime API section of the Poplar and PopLibs API Reference.
5.1. Parameters
As well as the data type, the Vector and VectorList templates also have
parameters to specify minimum alignment of elements, and whether or not they
need to be stored in interleaved memory, for example:
template <typename T, VectorLayout L, unsigned MinAlign, bool Interleaved>
class Input<Vector<T, L, MinAlign, Interleaved>>
...
5.1.1. Types
The vector data type (T) can be any of the supported Poplar types defined in Types.hpp.
5.1.2. Layout
The template parameter L defines the type of memory layout to use. The
valid layouts for a Vector are shown in Table 5.1.
Some of these layouts use compressed pointer formats. These are not supported
on all platforms.
In C++ vertex code, the use of these different layouts is completely transparent: elements can be accessed using the usual square bracket syntax and the compiler will insert the appropriate instructions to access them. The details of the layouts are useful to understand how their memory usage differs, and how to write vertex code (in Assembly) that uses them.
See Section 5.2.1, Pointer compression for more information.
Name |
Description |
Platform support |
|
A pointer to the start of the vector, and a count of the number of
elements (not bytes) the vector contains. This means that the |
All |
|
A pointer to the start of the vector, and a count of the number of
elements (not bytes) the vector contains. The count is limited to 11 bits.
This means that the |
Mk2 |
|
The same as |
All |
|
The same as |
Mk2 |
These layouts are described in more detail in Section 5.2, Memory layout for vectors.
Only SPAN and SHORT_SPAN provide a .size() method.
5.1.3. Minimum alignment
The MinAlign template parameter
specifies the required alignment, in bytes, of the data in the Vector
or VectorList.
The default value for this is 1 byte for
SPAN,SHORT_SPANorONE_PTRlayouts.For
SCALED_PTR128, the default alignment is 16.
However, the alignment is never less than the size of the data type. Values are always naturally aligned.
5.1.4. Interleaved memory
The final template parameter, Interleaved, tells the compiler that the data
must be placed in interleaved memory (see Section 10.2, Memory architecture).
5.2. Memory layout for vectors
This section describes the ways in which Vector
types can be arranged in memory.
5.2.1. Pointer compression
In order to reduce memory usage, the size of pointers to the vector data can be compressed, based on the tile memory size.
Note
Future implementations of the IPU may have memory with different sizes and base addresses. You should not hard-code any assumptions about the memory system. The Poplar library includes functions that provide information about the memory system that the code is running on (see Section 10.2, Memory architecture for more information).
Not all of these compressed pointer formats are available on all platforms.
The header file AvailableVTypes.h provides macros that define which formats
are supported. For example:
#include "poplar/AvailableVTypes.h"
#if defined(VECTOR_AVAIL_SCALED_PTR128)
Input<Vector<char, VectorLayout::SCALED_PTR128, 4>> desc;
#else
Input<Vector<char, VectorLayout::ONE_PTR, 4>> desc;
#endif
SCALED_PTR128
A 32-bit pointer can be compressed to 16 bits by enforcing 128-bit data alignment. In this case, bits [3:0] are always 0 and the compressed pointer contains bits [19:4] of the address.
5.2.2. Vector<T> layout
Vector is the simplest array type. It always stores a pointer to the start
of the data array, and can optionally store the number of elements. If the
number of elements is present, a .size() method is available.
The supported memory layouts are shown in Table 5.1.
Fig. 5.1 shows the memory layout for ONE_PTR and SPAN.
SCALED_PTR_128 is similar to ONE_PTR
but their begin pointers are 16 bits instead of 32.
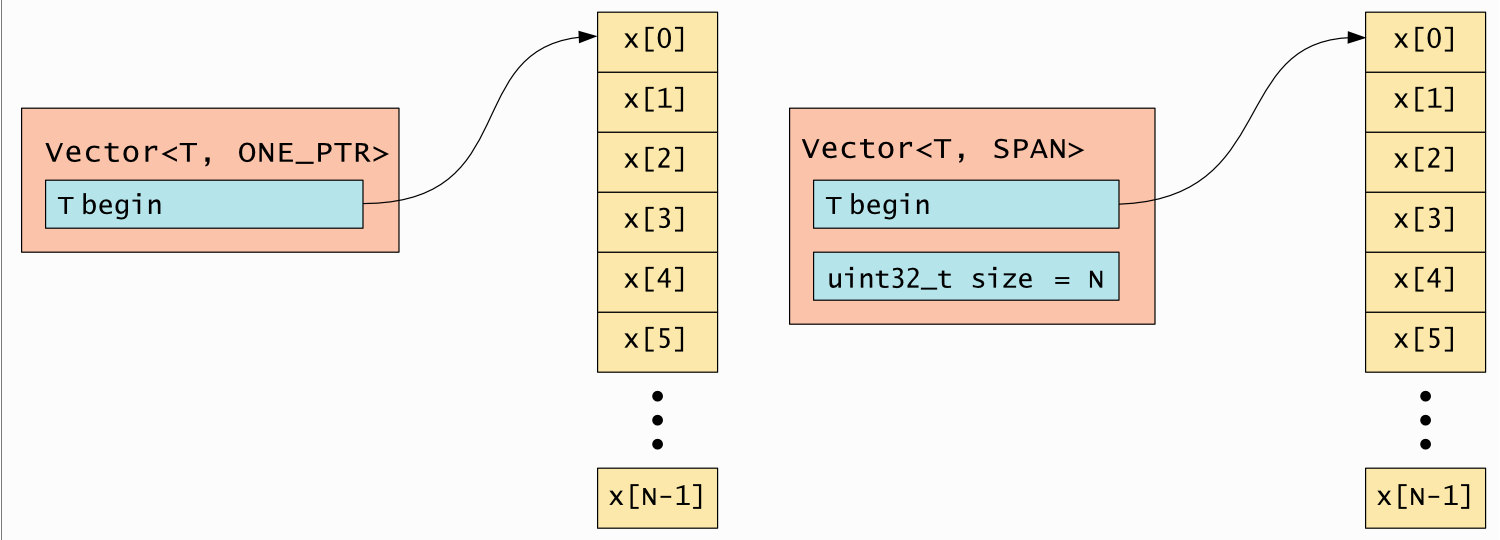
Fig. 5.1 Vector<T> memory layout
The SPAN layout can be represented as:
T* begin; // 32-bit pointer
uint32_t size;
Whereas SHORT_SPAN has a layout like this:
T* begin; // Truncated 20-bit pointer
// 1 bit reserved for the future
uint11_t size;
Which means it can only store up to 2,047 elements.
5.2.3. Vector<Input<Vector<T>>> layout
It is possible to nest Vectors, and at each level the memory layout can be
different. We use Vector<Input<Vector<T>>> to illustrate how these are
implemented, but Input could also be Output or InOut.
For example, if both levels use ONE_PTR you would have the layout shown in
Fig. 5.2.
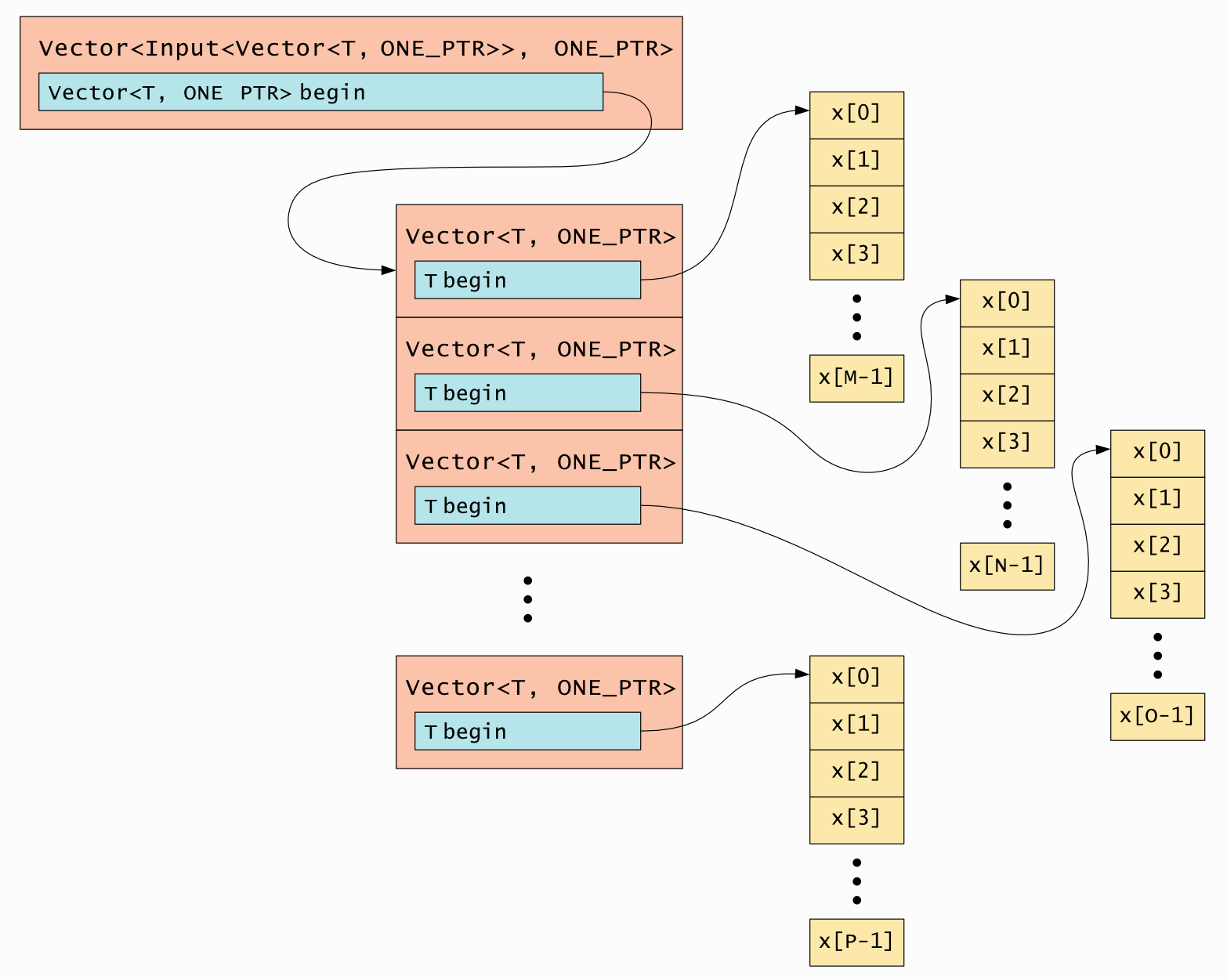
Fig. 5.2 Vector<Input<Vector<T>>> memory layout using ONEPTR
Or if both levels used SPAN the layout would be as shown in
Fig. 5.3.
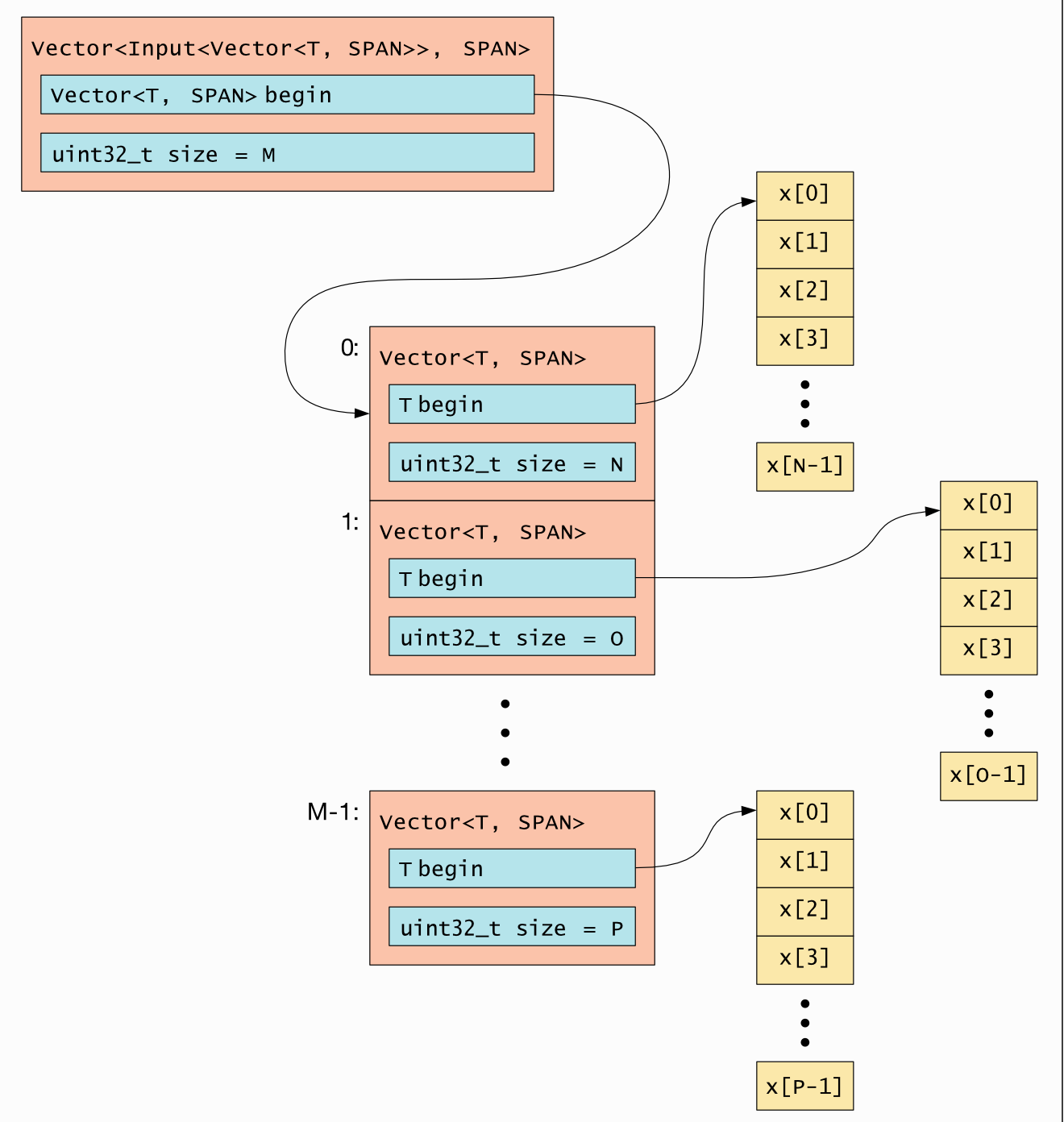
Fig. 5.3 Vector<Input<Vector<T>>> memory layout with SPAN
Note that this produces a “jagged” 2D vector. In other words, the length of each sub-vector is not guaranteed to be identical (although it might be).
You can use different layouts for each level, for example:
Vector<Input<Vector<T, ONE_PTR>>, SPAN>.
5.2.4. VectorList layout
As shown in Fig. 5.2 and
Fig. 5.3, nested vectors such as
Vector<Input<Vector<T>>> require the use of more memory,
beyond the data itself, to store the pointers and sizes of the sub-vectors. This
additional memory can become significant, especially if the data consists of
many short sub-vectors.
To reduce the additional memory usage, Poplar provides a more memory-efficient
2D vector type called VectorList.
This reduced memory usage comes at the cost of a slightly slower access to the
start of each sub-vector because of the added complexity of the data structures.
There is also a limit on the total number of sub-vectors (65,535) and
more stringent limits on the sizes of each sub-vector which depend on the
specific data type stored in VectorList (see
Table 5.2).
For Mk2 and newer IPU architectures, there is one available layout for
VectorList, named DELTANELEMENTS.
Note
- Using PopVision Graph Analyser to analyse memory usage
PopVision Graph Analyser lists the amount of additional memory used by
VectorandVectorListunder Vertex Data, using different Variable Types:
Type of nested vector |
Graph Analyser Variable Type |
|---|---|
|
Vector Field Data |
|
Vector List Descriptor |
In C++ vertex code, the use of VectorList is completely transparent:
sub-vector elements can be accessed using the same square bracket syntax used
for nested Vector data. The compiler will insert the appropriate code to
extract pointers and sizes.
For instance, the code below will compile and work as expected:
Output<VectorList<float, VectorListLayout::DELTANELEMENTS>> out;
. . .
out[3][7] = 3.141592;
When a Vertex object containing a VectorList field is instantiated
in C++ host code, the connection from graph variables to that field is also
done in the same way as for a nested Vector.
The detailed memory layout described below will only be needed to understand the details of the memory usage, and how to access the data from vertex code written in Assembly.
DELTANELEMENTS layout
This has a base structure which contains the base address of the data, the size of the vector (that is, the number of sub-vectors) and a pointer to an array of structures describing the sub-vectors.
Each of the sub-vector structures contain a pointer to its data (as an offset from the base address specified in the base structure) and the number of data elements. Each sub-vector can be a different size. The base address points to the start of the vector data and so one of the offsets is always zero.
Fig. 5.4 shows this implementation, using C-like types to represent the pointer and count sizes.
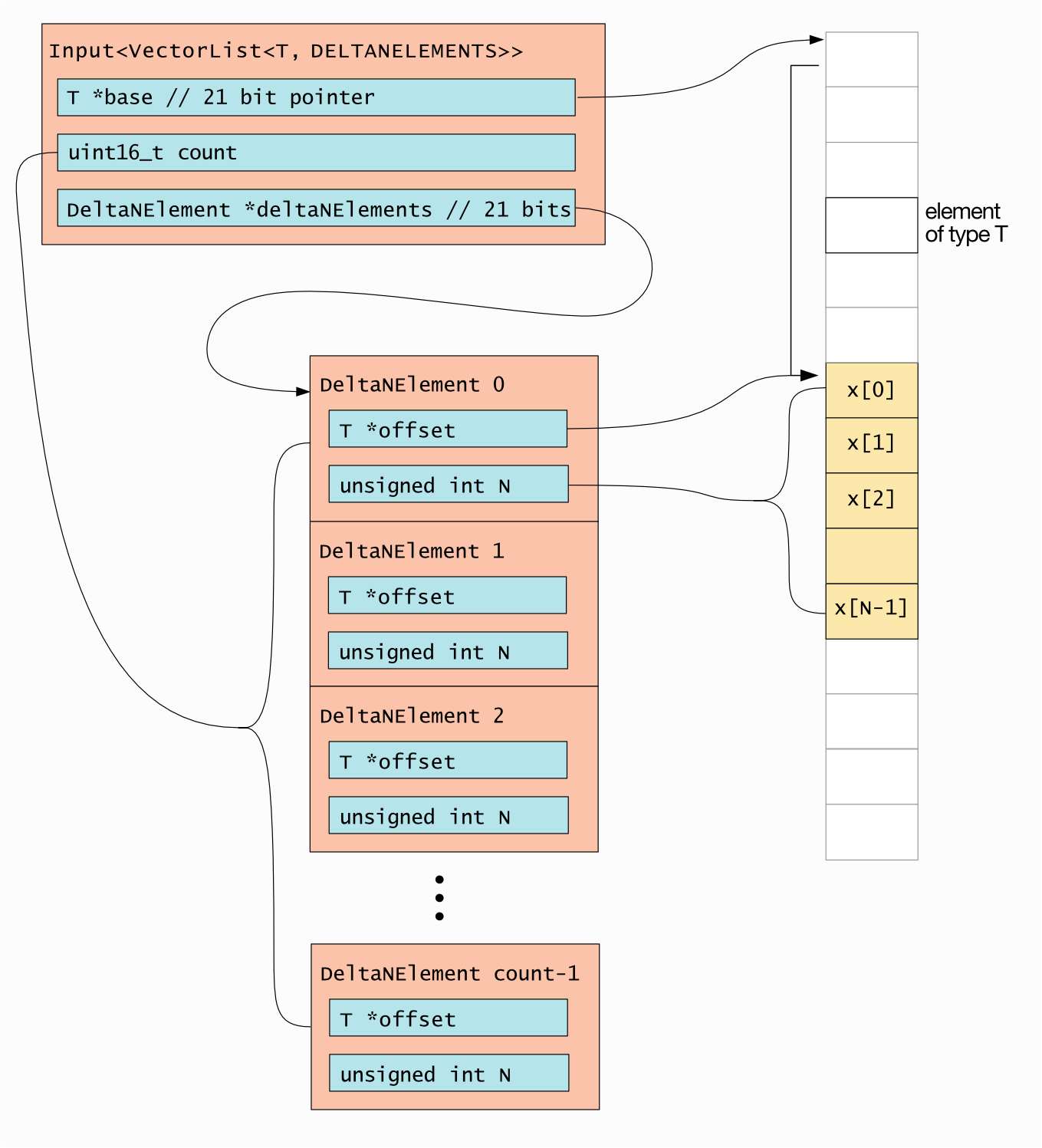
Fig. 5.4 DELTANELEMENTS memory layout
The top-level structure contains a pointer to the base of the vector data, a
count of the number of sub-vectors and a pointer to an array of DeltaNElement
structures for the sub-vectors. Both pointers are 21 bits so that the full
architectural memory space of the tile can be addressed.
These values are packed into two 32-bit words, as shown in Fig. 5.5. The reserved bits should not be assumed to be zero and should be masked off when extracting the address fields.
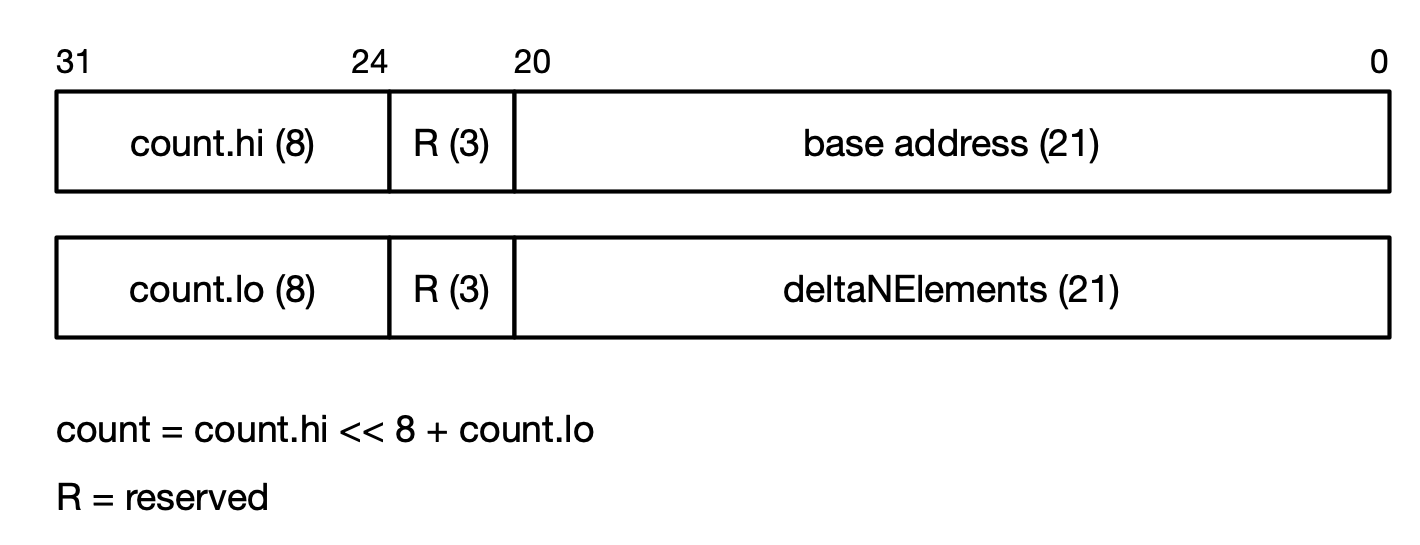
Fig. 5.5 DELTANELEMENTS base structure bit packing
Each DeltaNElement structure represents a sub-vector. It has a pointer to
the data, which is an element-sized offset from the base address (so, for
example, for naturally-aligned float data, this will be an offset in 32-bit
words). It also has a count of the number of data elements in this sub-vector.
The offset and count are packed into a 32-bit word. The number of bits for each depends on the data alignment. For byte-aligned data, the offset is 21 bits and the count is 11 bits. For larger alignments, fewer bits are required for the offset and more bits are available for the count. For example, for 32-bit aligned data, only 19 bits are required for the offset, so 13 bits are available for the sub-vector size.
The number of bits available for the offset and the count for various data types are summarised in Table 5.2 and illustrated in Fig. 5.6.
Data Type Size |
Offset Field Size |
Count Field Size |
Maximum Count Value |
Offset Unpacking |
|---|---|---|---|---|
1 byte |
|
|
2,047 |
<< 0 |
2 bytes (e.g. |
|
|
4,095 |
<< 1 |
4 bytes (e.g. |
|
|
8,191 |
<< 2 |
8 bytes |
|
|
16,383 |
<< 3 |
16 bytes |
|
|
32,767 |
<< 4 |
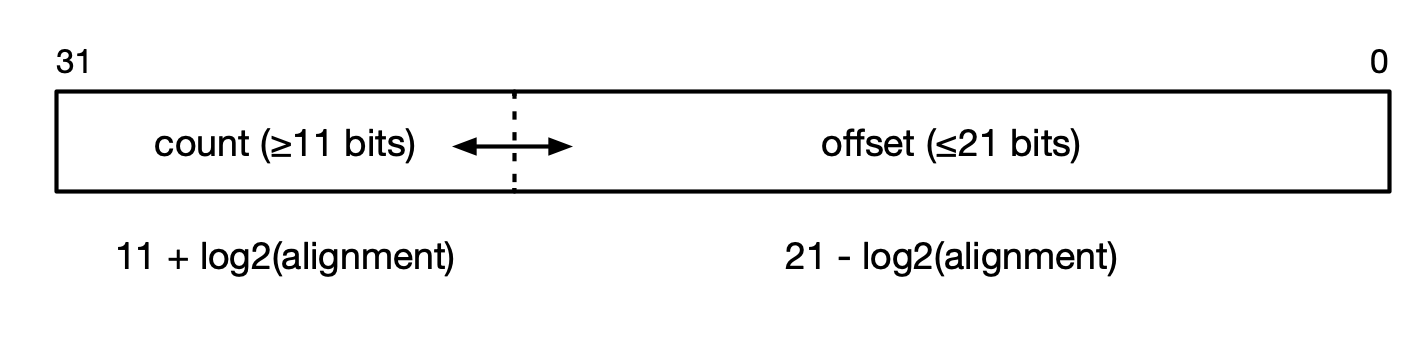
Fig. 5.6 DELTANELEMENTS sub-vector structure bit packing
Note that the alignment must be a multiple of the data type size.