15. IPU embedded application runtime
The embedded application runtime allows you to run a compiled TensorFlow executable as part of a TensorFlow graph. This enables embedding the executable in a larger and more complex system, while also utilising IPUs. This runtime appears in the TensorFlow graph as a custom CPU operation.
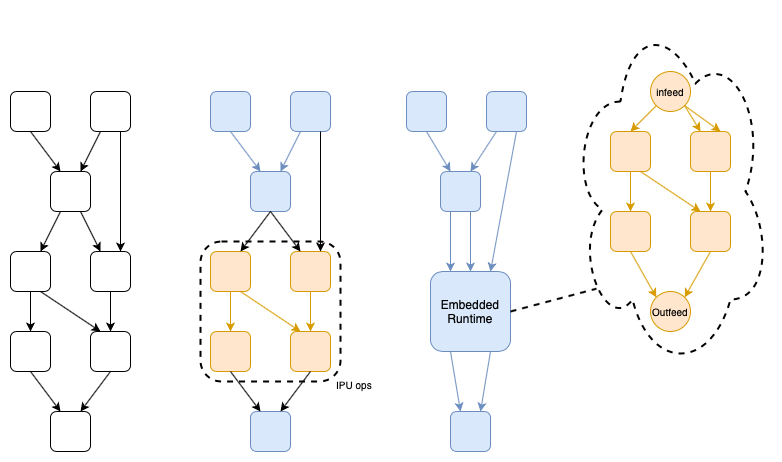
Fig. 15.1 An arbitrary compute graph (left) with a possible IPU subgraph identified (middle), and a possible embedding of an executable (right)
The executable can be built with infeeds and outfeeds that maximise the performance of the compiled application on the IPU. The feeds are presented to the TensorFlow graph as standard inputs and outputs on the call operation. These can be connected to other TensorFlow operations as part of a larger graph.
Any mutable variables used inside the application are passed once in the call to start. This minimises redundant communication with the IPUs.
Applications access this functionality through the
tensorflow.python.ipu.embedded_runtime.embedded_runtime_start() and
tensorflow.python.ipu.embedded_runtime.embedded_runtime_call() helper
functions.
15.1. Usage
The IPU embedded application runtime relies on instances of the
RuntimeContext class to coordinate the startup and calls to the Poplar
engine. This object is created with a call to
tensorflow.python.ipu.embedded_runtime.embedded_runtime_start().
from tensorflow.python.ipu import embedded_runtime
...
context = embedded_runtime.embedded_runtime_start(
poplar_exec_filepath, startup_inputs, engine_name)
The startup_inputs can be a list of tensors or a name-value dictionary of
tensors, where the names correspond to the name of the XLA inputs.
The created object is then passed to the call site where the
tensorflow.python.ipu.embedded_runtime.embedded_runtime_call()
function can be called. The context object ensures all appropriate metadata is
passed, and control dependencies are created.
...
results = embedded_runtime.embedded_runtime_call(
call_inputs, context)
session.run(results, feed_dict={...})
Once the IPU embedded application runtime has been created and used within the session, the Poplar engine will be running in a background thread. This thread can outlive the TensorFlow session.
15.2. Pipelining and I/O tiles
When running a pipelined application, or an application with I/O tiles, we must handle the additional layer of pipelining. This is a result of there being multiple batches of data resident in the device at the same time.
There are two ways to manage this. The first is by submitting multiple requests in parallel. The second is to provide a maximum timeout that the application should wait for additional data.
15.2.1. Parallel requests
To ensure the application isn’t starved of data you can submit multiple batches of data in parallel in multiple threads. These will be enqueued and processed as early as possible by the device.
When an application is pipelined, these parallel batches of data will overlap in time as they are processed by the devices. This improves the overall utilisation of the devices and minimises the batch latency.
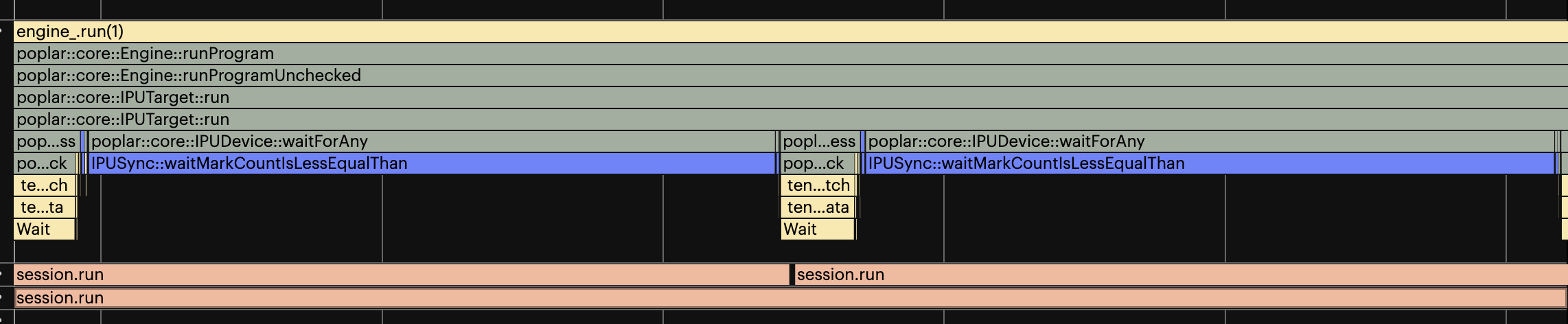
Fig. 15.2 Embedded runtime with two threads and some waiting

Fig. 15.3 The same application with four threads and no waiting
15.2.2. Timeout
When the application is pipelined or using I/O tiles, and data starvation might occur, the timeout option allows you to set an upperbound on the time the IPU will wait for data.
When TensorFlow receives a Poplar callback a timer is started. When the timer reaches the defined timeout, a “dummy” batch of data is passed to the device. This unblocks any pending batches that are in the device.
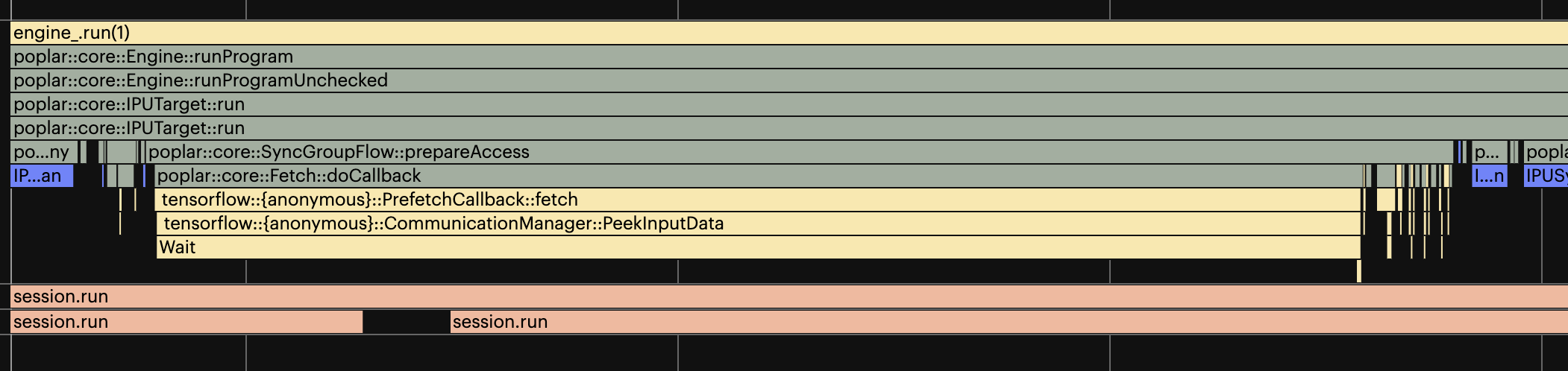
Fig. 15.4 An embedded runtime application triggering a 500us timeout
15.2.3. Engine restarts
The number of batches to process in an application is a compile-time decision. However, you might later deliver more batches at runtime than compiled for. If this happens, the Poplar engine will be restarted. A restart blocks enqueued items from being processed, temporarily increasing latency.
To mitigate this, we recommend compiling the application to process as many batches as required before it terminates. If the number of batches is unknown, choose a value large enough to minimise this.
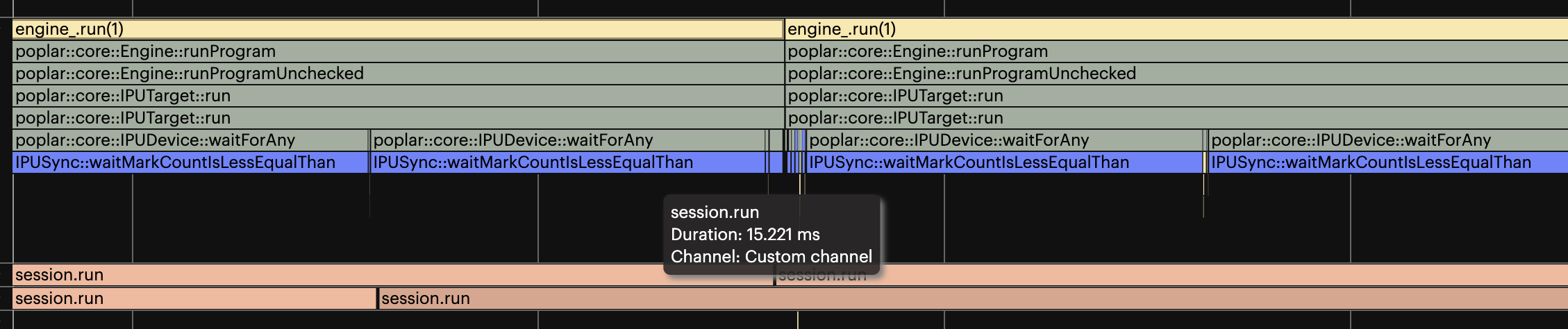
Fig. 15.5 An embedded runtime application triggering an engine restart causing increased latency
15.3. Example
This example creates a very simple IPU program that doubles the input tensor.
1import tempfile
2import os
3import numpy as np
4
5from tensorflow.python.ipu import ipu_infeed_queue
6from tensorflow.python.ipu import ipu_outfeed_queue
7from tensorflow.python.ipu import loops
8from tensorflow.python.ipu import application_compile_op
9from tensorflow.python.ipu import embedded_runtime
10from tensorflow.python.ipu.config import IPUConfig
11import tensorflow.compat.v1 as tf
12
13tf.disable_v2_behavior()
14
15element_count = 4
16loop_count = 16
17
18# The dataset for feeding the graphs.
19ds = tf.data.Dataset.from_tensors(tf.constant(1.0, shape=[element_count]))
20ds = ds.repeat()
21
22# The host side queues.
23infeed_queue = ipu_infeed_queue.IPUInfeedQueue(ds)
24outfeed_queue = ipu_outfeed_queue.IPUOutfeedQueue()
25
26
27# The device side main.
28def body(x):
29 # double the input - replace this with application body.
30 result = x * 2
31 outfeed = outfeed_queue.enqueue({'result': result})
32 return outfeed
33
34
35# Wrap in a loop.
36def my_net():
37 r = loops.repeat(loop_count, body, [], infeed_queue)
38 return r
39
40
41# Configure the IPU for compilation.
42cfg = IPUConfig()
43cfg.auto_select_ipus = 1
44cfg.configure_ipu_system()
45
46# Setup a temporary directory to store the executable.
47tmp_dir_obj = tempfile.TemporaryDirectory()
48tmp_dir = tmp_dir_obj.name
49poplar_exec_filepath = os.path.join(tmp_dir, "application.poplar_exec")
50
51# Compile the application.
52compile_op = application_compile_op.experimental_application_compile_op(
53 my_net, output_path=poplar_exec_filepath)
54
55with tf.Session() as sess:
56 path = sess.run(compile_op)
57 print(f"Poplar executable: {path}")
58
59# Create the start op.
60# This creates the poplar engine in a background thread.
61inputs = []
62engine_name = "my_engine"
63ctx = embedded_runtime.embedded_runtime_start(poplar_exec_filepath, inputs,
64 engine_name)
65# Create the call op and the input placeholder.
66input_placeholder = tf.placeholder(tf.float32, shape=[element_count])
67call_result = embedded_runtime.embedded_runtime_call([input_placeholder], ctx)
68
69# Call the application.
70# This should print the even numbers 0 to 30.
71for i in range(loop_count):
72 with tf.Session() as sess:
73 input_data = np.ones(element_count, dtype=np.float32) * i
74 print(sess.run(call_result, feed_dict={input_placeholder: input_data}))
15.4. Error Handling
Note
This section only applies to the execution using the IPU embedded application runtime. If you are using the XLA/Poplar runtime see Error Handling.
15.4.1. Runtime errors
These errors and exceptions occur when running a Poplar program. The full list of all the exceptions and their meanings can be found in the Poplar documentation in the Exceptions section of the Poplar API reference manual.
These runtime errors are handled in the following manner:
application_runtime_error- atensorflow.errors.InternalErrorerror is raised. The error message contains the reason why the error occurred. An IPU reset will be performed before the next execution. All requests which have already been enqueued before the exception occurred will return the error. Any new requests will be processed after the IPU reset is complete.recoverable_runtime_errorwith a recovery actionpoplar::RecoveryAction::IPU_RESET- atensorflow.errors.InternalErrorerror is raised. The error message contains the reason why the error occurred. An IPU reset will be performed before the next execution. All requests which have already been enqueued before the exception occurred will return the error. Any new requests will be processed after the IPU reset is complete.Unknown runtime errors - a
tensorflow.errors.Unknownerror is raised. The error message might contain the reason why the error occurred. When these errors occur manual intervention is required before the system is operational again. The IPU will not be reset and all requests will return the error.All other runtime errors - a
tensorflow.errors.InternalErrorerror is raised. The error message might contain the reason why the error occurred. When these errors occur manual intervention might be required before the system is operational again. The error message might contain a required recovery action. The IPU will not be reset and all requests will return the error.