3. Using ModelRunner
The ModelRunner class is a lightweight wrapper
around all the functionality provided by Model Runtime (Section 2, Model Runtime overview) to make it easy for you to deploy models from PopEF files.
There are two steps for running a PopEF model using ModelRunner:
Create a
ModelRunnerobject by providing either a list of PopEF files or an instance of thepopef::Modelclass.In this step, an IPU is acquired and the model is loaded onto it. All necessary threads and classes are created and stored in the
ModelRunnerinternal state.You can set several configuration options, for example
replication factor, when you create theModelRunnerobject usingModelRunnerConfig.Use one of the execution modes (Section 3.1, Execution modes) to send an inference request to the IPU.
Note
The ModelRunner instance must be preserved until
the last inference request returns a result. Destruction of the instance
causes the model to be stopped and unloaded from the IPU. The state of the
requests that were being processed when the object was destroyed is
undefined.
3.1. Execution modes
ModelRunner provides two execution modes:
synchronous (execute()) and asynchronous
(executeAsync()).
In the synchronous mode, the request blocks until the result is available.
In the asynchronous mode, the request is queued and a std::future object is returned. The result can be accessed as soon as the IPU finishes computation.
For both modes, you are responsible for the memory allocation of the input tensors.
All
execute() and
executeAsync() functions take an
InputMemoryView parameter that contains pointers
to all input data. You must ensure that the input data exists and the
pointers are valid until the result is returned.
Each of these execution functions come in two flavours, which differ in how the memory for the output tensors is allocated:
ModelRunnerallocates memory for the output and returns aTensorMemoryinstance for each output tensor.The corresponding functions are:
You allocate the output tensor memory and pass an
OutputMemoryViewobject to the execute function.ModelRunnerwill place the result in the memory you have provided.The corresponding functions are:
You can find out about the tensors that the model accepts as inputs and returns as outputs by calling
one of the following ModelRunner methods:
These methods return a collection of DataDesc
objects which contain basic information about the tensor:
name
shape
data type
size in bytes
The Python and C++ examples below send inference requests to the IPU using all available execution modes.
Note
Files used by the examples in this chapter are listed in the examples appendix. They contain helper functions, for example to process command line arguments.
Download model_runner_execution_modes.py
1#!/usr/bin/env python3
2# Copyright (c) 2022 Graphcore Ltd. All rights reserved.
3
4import argparse
5from datetime import timedelta
6from re import L
7import numpy as np
8import model_runtime
9import popef
10"""
11The example shows loading a model from PopEF files and sending
12inference requests using all available ModelRunner execution modes.
13"""
14
15
16def main():
17 parser = argparse.ArgumentParser("Model runner simple example.")
18 parser.add_argument(
19 "-p",
20 "--popef",
21 type=str,
22 metavar='popef_file_path',
23 help="A collection of PopEF files containing the model.",
24 nargs='+',
25 required=True)
26 args = parser.parse_args()
27
28 # Create model runner
29 config = model_runtime.ModelRunnerConfig()
30 config.device_wait_config = model_runtime.DeviceWaitConfig(
31 model_runtime.DeviceWaitStrategy.WAIT_WITH_TIMEOUT,
32 timeout=timedelta(seconds=600),
33 sleepTime=timedelta(seconds=1))
34
35 print("Creating ModelRunner with", config)
36 model_runner = model_runtime.ModelRunner(model_runtime.PopefPaths(
37 args.popef),
38 config=config)
39
40 print("Preparing input tensors:")
41 input_descriptions = model_runner.getExecuteInputs()
42 input_tensors = [
43 np.random.randn(*input_desc.shape).astype(input_desc.numpy_data_type())
44 for input_desc in input_descriptions
45 ]
46 input_view = model_runtime.InputMemoryView()
47
48 for input_desc, input_tensor in zip(input_descriptions, input_tensors):
49 print("\tname:", input_desc.name, "shape:", input_tensor.shape,
50 "dtype:", input_tensor.dtype)
51 input_view[input_desc.name] = input_tensor
52
53 print("Running synchronous execution mode. The memory of the output "
54 "tensors is allocated by the ModelRunner object.")
55 synchronousExecutionModeLibraryAllocatedOutput(model_runner, input_view)
56
57 print("Running synchronous execution mode. The memory of the output "
58 "tensors is allocated by the user.")
59 synchronousExecutionModeUserAllocatedOutput(model_runner, input_view)
60
61 print("Running asynchronous execution mode. The memory of the output "
62 "tensors is allocated by the ModelRunner object.")
63 asynchronousExecutionModeLibraryAllocatedOutput(model_runner, input_view)
64
65 print("Running asynchronous execution mode. The memory of the output "
66 "tensors is allocated by the user.")
67 asynchronousExecutionModeUserAllocatedOutput(model_runner, input_view)
68
69 input_numpy = dict()
70 for input_desc, input_tensor in zip(input_descriptions, input_tensors):
71 input_numpy[input_desc.name] = input_tensor
72
73 print("Running synchronous execution mode. The input is a numpy array. "
74 "The memory of the output tensors is allocated by the ModelRunner "
75 "object.")
76 synchronousExecutionModeLibraryAllocatedNumpyInputOutput(
77 model_runner, input_numpy)
78
79 print("Running synchronous execution mode. The input and the output are "
80 "numpy arrays. The memory of the output tensors is allocated by the "
81 "user. ")
82 synchronousExecutionModeUserAllocatedNumpyInputOutput(
83 model_runner, input_numpy)
84
85 print(
86 "Running asynchronous execution mode. The input and the output are "
87 "numpy arrays . The memory of the output tensors is allocated by the "
88 "ModelRunner object.")
89 asynchronousExecutionModeLibraryAllocatedNumpyOutput(
90 model_runner, input_numpy)
91
92 print(
93 "Running asynchronous execution mode. The input and the output are "
94 "numpy arrays . The memory of the output tensors is allocated by the "
95 "user.")
96 asynchronousExecutionModeUserAllocatedNumpyOutput(model_runner,
97 input_numpy)
98
99 print("Success: exiting")
100 return 0
101
102
103def synchronousExecutionModeLibraryAllocatedOutput(model_runner, input_view):
104 print("Sending single synchronous request with random data. Output "
105 "allocated by ModelRunner.")
106 result = model_runner.execute(input_view)
107
108 output_descriptions = model_runner.getExecuteOutputs()
109 print("Processing output tensors:")
110 for output_desc in output_descriptions:
111 output_tensor = np.frombuffer(
112 result[output_desc.name],
113 dtype=output_desc.numpy_data_type()).reshape(output_desc.shape)
114 print("\tname:", output_desc.name, "shape:", output_tensor.shape,
115 "dtype:", output_tensor.dtype, "\n", output_tensor)
116
117
118def synchronousExecutionModeUserAllocatedOutput(model_runner, input_view):
119
120 output_descriptions = model_runner.getExecuteOutputs()
121 print("Preparing memory for output tensors")
122 output_tensors = [
123 np.zeros(output_desc.shape, dtype=output_desc.numpy_data_type())
124 for output_desc in output_descriptions
125 ]
126
127 print("Creating model_runtime.OutputMemoryView()")
128 output_view = model_runtime.OutputMemoryView()
129 for desc, tensor in zip(output_descriptions, output_tensors):
130 print("\tname:", desc.name, "shape:", tensor.shape, "dtype:",
131 tensor.dtype)
132 output_view[desc.name] = tensor
133
134 print("Sending single synchronous request with random data")
135 model_runner.execute(input_view, output_view)
136 print("Processing output tensors:")
137 for desc, tensor in zip(output_descriptions, output_tensors):
138 print("\tname:", desc.name, "shape", tensor.shape, "dtype",
139 tensor.dtype, "\n", tensor)
140
141
142def synchronousExecutionModeLibraryAllocatedNumpyInputOutput(
143 model_runner, numpy_input):
144
145 output_descriptions = model_runner.getExecuteOutputs()
146
147 print("Sending single synchronous request random data (numpy array)")
148 output_tensors = model_runner.execute(numpy_input)
149 print("Processing output tensors (numpy dict):")
150 for desc in output_descriptions:
151 tensor = output_tensors[desc.name]
152 print("\tname:", desc.name, "shape", tensor.shape, "dtype",
153 tensor.dtype, "\n", tensor)
154
155
156def synchronousExecutionModeUserAllocatedNumpyInputOutput(
157 model_runner, numpy_input):
158
159 output_descriptions = model_runner.getExecuteOutputs()
160 print("Preparing memory for output tensors")
161 numpy_output = {}
162 for output_desc in output_descriptions:
163 numpy_output[output_desc.name] = np.zeros(
164 output_desc.shape, dtype=output_desc.numpy_data_type())
165
166 print("Sending single synchronous request with random data")
167 model_runner.execute(numpy_input, numpy_output)
168 print("Processing output tensors (numpy dict):")
169 for desc in output_descriptions:
170 tensor = numpy_output[desc.name]
171 print("\tname:", desc.name, "shape", tensor.shape, "dtype",
172 tensor.dtype, "\n", tensor)
173
174
175def asynchronousExecutionModeLibraryAllocatedOutput(model_runner, input_view):
176
177 print("Sending single asynchronous request with random data. Output "
178 "allocated by ModelRunner.")
179 result = model_runner.executeAsync(input_view)
180
181 print("Waiting for output allocated by ModelRunner:")
182 result.wait()
183 print("Results available")
184
185 output_descriptions = model_runner.getExecuteOutputs()
186 print("Processing output tensors:")
187 for output_desc in output_descriptions:
188 output_tensor = np.frombuffer(
189 result[output_desc.name],
190 dtype=output_desc.numpy_data_type()).reshape(output_desc.shape)
191 print("\tname:", output_desc.name, "shape:", output_tensor.shape,
192 "dtype:", output_tensor.dtype, "\n", output_tensor)
193
194
195def asynchronousExecutionModeUserAllocatedOutput(model_runner, input_view):
196 output_descriptions = model_runner.getExecuteOutputs()
197 print("Preparing memory for output tensors")
198 output_tensors = [
199 np.zeros(output_desc.shape, dtype=output_desc.numpy_data_type())
200 for output_desc in output_descriptions
201 ]
202
203 print("Creating model_runtime.OutputMemoryView()")
204 output_view = model_runtime.OutputMemoryView()
205 for desc, tensor in zip(output_descriptions, output_tensors):
206 print("\tname:", desc.name, "shape:", tensor.shape, "dtype:",
207 tensor.dtype)
208 output_view[desc.name] = tensor
209
210 print("Sending single asynchronous request with random data")
211 future = model_runner.executeAsync(input_view, output_view)
212
213 print("Waiting for the output.")
214 future.wait()
215 print("Results available.")
216 print("Processing output tensors:")
217 for desc, tensor in zip(output_descriptions, output_tensors):
218 print("\tname:", desc.name, "shape", tensor.shape, "dtype",
219 tensor.dtype, "\n", tensor)
220
221
222def asynchronousExecutionModeLibraryAllocatedNumpyOutput(
223 model_runner, numpy_input):
224 print("Sending single asynchronous request with random data")
225 future = model_runner.executeAsync(numpy_input)
226
227 print("Waiting for the output.")
228 future.wait()
229 for desc in model_runner.getExecuteOutputs():
230 future_py_array = future[desc.name]
231
232 # Create a np.array copy from the future_py_array buffer
233 # using numpy() method.
234 tensor = future_py_array.numpy()
235 print("\tname:", desc.name, "shape", tensor.shape, "dtype",
236 tensor.dtype, "tensor id", id(tensor), "\n", tensor)
237
238 # Create a np.array copy from the future_py_array buffer
239 # (allocated by ModelRunner instance).
240 tensor_copy = np.array(future_py_array, copy=True)
241 print("Tensor copy", tensor_copy, "tensor id", id(tensor_copy))
242
243 # Avoid copying. Create a np.array view from the future_py_array buffer
244 # (allocated by ModelRunner instance).
245 tensor_view = np.array(future_py_array, copy=False)
246 print("Tensor view", tensor_view, "tensor id", id(tensor_view))
247
248 assert not np.shares_memory(tensor_view, tensor_copy)
249 assert not np.shares_memory(tensor, tensor_copy)
250 assert not np.shares_memory(tensor, tensor_view)
251
252
253def asynchronousExecutionModeUserAllocatedNumpyOutput(model_runner,
254 numpy_input):
255
256 output_descriptions = model_runner.getExecuteOutputs()
257 print("Preparing memory for output tensors")
258 numpy_output = {}
259 for output_desc in output_descriptions:
260 numpy_output[output_desc.name] = np.zeros(
261 output_desc.shape, dtype=output_desc.numpy_data_type())
262
263 print("Sending single asynchronous request with random data")
264 future = model_runner.executeAsync(numpy_input, numpy_output)
265
266 print("Waiting for the output.")
267 future.wait()
268 print("Results available.")
269 print("Processing output tensors:")
270 for desc in output_descriptions:
271 output_tensor = numpy_output[desc.name]
272 future_py_array_view = future[desc.name]
273
274 # Create a np.array view from the future_py_array_view using numpy()
275 # method, view points to np.array present in numpy_output dict
276 tensor_from_future_object = future_py_array_view.numpy()
277 print("\tname:", desc.name, "shape", tensor_from_future_object.shape,
278 "dtype", tensor_from_future_object.dtype, "\n",
279 tensor_from_future_object)
280 assert np.shares_memory(output_tensor, tensor_from_future_object)
281
282 # Create a np.array view from the future_py_array_view buffer, view
283 # points to np.array present in numpy_output dict
284 tensor_view = np.array(future_py_array_view, copy=False)
285 assert np.shares_memory(output_tensor, tensor_view)
286 assert np.shares_memory(tensor_from_future_object, tensor_view)
287
288 # Create a np.array copy from the future_py_array_view buffer
289 tensor_copy = np.array(future_py_array_view, copy=True)
290 assert not np.shares_memory(tensor_from_future_object, tensor_copy)
291 assert not np.shares_memory(output_tensor, tensor_copy)
292
293
294if __name__ == "__main__":
295 main()
Download model_runner_execution_modes.cpp
1// Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2#include <string>
3#include <vector>
4
5#include <boost/program_options.hpp>
6
7#include "model_runtime/ModelRunner.hpp"
8#include "model_runtime/Tensor.hpp"
9#include "utils.hpp"
10
11namespace examples {
12
13void synchronousExecutionModeLibraryAllocatedOutput(
14 model_runtime::ModelRunner &model_runner);
15void synchronousExecutionModeUserAllocatedOutput(
16 model_runtime::ModelRunner &model_runner);
17void asynchronousExecutionModeLibraryAllocatedOutput(
18 model_runtime::ModelRunner &model_runner);
19void asynchronousExecutionModeUserAllocatedOutput(
20 model_runtime::ModelRunner &model_runner);
21
22} // namespace examples
23
24/* This example loads a model from a PopEF file and sends
25 * inference requests using all available ModelRunner execution modes.
26 */
27int main(int argc, char *argv[]) {
28 using namespace std::chrono_literals;
29 static const char *example_desc = "Model runner execution modes example.";
30 const boost::program_options::variables_map vm =
31 examples::parsePopefProgramOptions(example_desc, argc, argv);
32 const auto popef_paths = vm["popef"].as<std::vector<std::string>>();
33
34 model_runtime::ModelRunnerConfig config;
35 config.device_wait_config =
36 model_runtime::DeviceWaitConfig{600s /*timeout*/, 1s /*sleep_time*/};
37 model_runtime::ModelRunner model_runner(popef_paths, config);
38
39 examples::print("Running synchronous execution mode. The memory of the "
40 "output tensors is allocated by the ModelRunner object.");
41 examples::synchronousExecutionModeLibraryAllocatedOutput(model_runner);
42
43 examples::print("Running synchronous execution mode. The memory of the "
44 "output tensors is allocated by the user.");
45 examples::synchronousExecutionModeUserAllocatedOutput(model_runner);
46
47 examples::print("Running asynchronous execution mode. The memory of the "
48 "output tensors is allocated by the ModelRunner object.");
49 examples::asynchronousExecutionModeLibraryAllocatedOutput(model_runner);
50
51 examples::print("Running asynchronous execution mode. The memory of the "
52 "output tensors is allocated by the user.");
53 examples::asynchronousExecutionModeUserAllocatedOutput(model_runner);
54
55 examples::print("Success: exiting");
56 return EXIT_SUCCESS;
57}
58
59namespace examples {
60
61void synchronousExecutionModeLibraryAllocatedOutput(
62 model_runtime::ModelRunner &model_runner) {
63 examples::print("Allocating input tensors");
64 const model_runtime::InputMemory input_memory =
65 examples::allocateHostInputData(model_runner.getExecuteInputs());
66
67 examples::printInputMemory(input_memory);
68
69 examples::print("Sending single synchronous request with empty data. Output "
70 "allocated by ModelRunner.");
71
72 const model_runtime::OutputMemory output_memory =
73 model_runner.execute(examples::toInputMemoryView(input_memory));
74
75 examples::print("Received output allocated by ModelRunner:");
76 using ValueType = std::pair<const std::string, model_runtime::TensorMemory>;
77
78 for (const ValueType &name_with_memory : output_memory) {
79 auto &&[name, memory] = name_with_memory;
80 examples::print(fmt::format("Output tensor {}, {} bytes", name,
81 memory.data_size_bytes));
82 }
83}
84
85void synchronousExecutionModeUserAllocatedOutput(
86 model_runtime::ModelRunner &model_runner) {
87 examples::print("Allocating input tensors");
88 const model_runtime::InputMemory input_memory =
89 examples::allocateHostInputData(model_runner.getExecuteInputs());
90
91 examples::printInputMemory(input_memory);
92
93 examples::print("Allocating output tensors");
94 model_runtime::OutputMemory output_memory =
95 examples::allocateHostOutputData(model_runner.getExecuteOutputs());
96
97 examples::print("Sending single synchronous request with empty data.");
98
99 model_runner.execute(examples::toInputMemoryView(input_memory),
100 examples::toOutputMemoryView(output_memory));
101
102 examples::print("Received output allocated by ModelRunner:");
103
104 using ValueType = std::pair<const std::string, model_runtime::TensorMemory>;
105
106 for (const ValueType &name_with_memory : output_memory) {
107 auto &&[name, memory] = name_with_memory;
108 examples::print(fmt::format("Output tensor {}, {} bytes", name,
109 memory.data_size_bytes));
110 }
111}
112
113void asynchronousExecutionModeLibraryAllocatedOutput(
114 model_runtime::ModelRunner &model_runner) {
115 examples::print("Allocating input tensors");
116 const model_runtime::InputMemory input_memory =
117 examples::allocateHostInputData(model_runner.getExecuteInputs());
118
119 examples::printInputMemory(input_memory);
120
121 examples::print("Sending single synchronous request with empty data. Output "
122 "allocated by ModelRunner.");
123
124 const model_runtime::OutputFutureMemory output_future_memory =
125 model_runner.executeAsync(examples::toInputMemoryView(input_memory));
126
127 examples::print("Waiting for output allocated by ModelRunner:");
128
129 using ValueType = std::pair<const std::string,
130 std::shared_future<model_runtime::TensorMemory>>;
131
132 for (const ValueType &name_with_future_memory : output_future_memory) {
133 auto &&[name, future_memory] = name_with_future_memory;
134 examples::print(fmt::format("Waiting for the result: tensor {}", name));
135 future_memory.wait();
136 const model_runtime::TensorMemory &memory = future_memory.get();
137 examples::print(fmt::format("Output tensor {} available, received {} bytes",
138 name, memory.data_size_bytes));
139 }
140}
141
142void asynchronousExecutionModeUserAllocatedOutput(
143 model_runtime::ModelRunner &model_runner) {
144 examples::print("Allocating input tensors");
145 const model_runtime::InputMemory input_memory =
146 examples::allocateHostInputData(model_runner.getExecuteInputs());
147
148 examples::printInputMemory(input_memory);
149
150 examples::print("Allocating output tensors");
151 model_runtime::OutputMemory output_memory =
152 examples::allocateHostOutputData(model_runner.getExecuteOutputs());
153
154 examples::print("Sending single synchronous request with empty data.");
155
156 const model_runtime::OutputFutureMemoryView output_future_memory_view =
157 model_runner.executeAsync(examples::toInputMemoryView(input_memory),
158 examples::toOutputMemoryView(output_memory));
159
160 examples::print("Waiting for the output");
161
162 using ValueType =
163 std::pair<const std::string,
164 std::shared_future<model_runtime::TensorMemoryView>>;
165
166 for (const ValueType &name_with_future_memory_view :
167 output_future_memory_view) {
168 auto &&[name, future_memory_view] = name_with_future_memory_view;
169 examples::print(fmt::format("Waiting for the result: tensor {}", name));
170 future_memory_view.wait();
171 const model_runtime::TensorMemoryView &memory_view =
172 future_memory_view.get();
173 examples::print(fmt::format("Output tensor {} available, received {} bytes",
174 name, memory_view.data_size_bytes));
175 }
176}
177
178} // namespace examples
3.2. Replication
You can specify the replication factor inside the ModelRunnerConfig object passed to the ModelRunner constructor. When the replication factor is set, the
ModelRunner object will create the number of IPU model replicas specified, up to the number of available IPUs. The last parameter to each execution function is the ID of the replica to which the inference request will be sent.
The Python and C++ examples below create two replicas and send inference requests to each of them.
Download model_runner_replication.py
1#!/usr/bin/env python3
2# Copyright (c) 2022 Graphcore Ltd. All rights reserved.
3
4import argparse
5from datetime import timedelta
6import numpy as np
7import model_runtime
8import popef
9"""
10The example shows loading a model from PopEF files, creating 2 model replicas
11and sending inference requests to each of them.
12"""
13
14
15def main():
16 parser = argparse.ArgumentParser("Model runner simple example.")
17 parser.add_argument(
18 "-p",
19 "--popef",
20 type=str,
21 metavar='popef_file_path',
22 help="A collection of PopEF files containing the model.",
23 nargs='+',
24 required=True)
25 args = parser.parse_args()
26
27 num_replicas = 2
28 # Create model runner
29 config = model_runtime.ModelRunnerConfig()
30 config.replication_factor = num_replicas
31 config.device_wait_config = model_runtime.DeviceWaitConfig(
32 model_runtime.DeviceWaitStrategy.WAIT_WITH_TIMEOUT,
33 timeout=timedelta(seconds=600),
34 sleepTime=timedelta(seconds=1))
35
36 print("Creating ModelRunner with", config)
37 runner = model_runtime.ModelRunner(model_runtime.PopefPaths(args.popef),
38 config=config)
39
40 input_descriptions = runner.getExecuteInputs()
41
42 input = model_runtime.InputMemoryView()
43
44 print("Preparing input tensors:")
45 input_descriptions = runner.getExecuteInputs()
46 input_tensors = [
47 np.random.randn(*input_desc.shape).astype(input_desc.numpy_data_type())
48 for input_desc in input_descriptions
49 ]
50 input_view = model_runtime.InputMemoryView()
51
52 for input_desc, input_tensor in zip(input_descriptions, input_tensors):
53 print("\tname:", input_desc.name, "shape:", input_tensor.shape,
54 "dtype:", input_tensor.dtype)
55 input_view[input_desc.name] = input_tensor
56
57 for replica_id in range(num_replicas):
58 print("Sending single synchronous request with empty data - replica",
59 replica_id, ".")
60 result = runner.execute(input_view, replica_id=replica_id)
61 output_descriptions = runner.getExecuteOutputs()
62
63 print("Processing output tensors - replica", replica_id, ":")
64 for output_desc in output_descriptions:
65 output_tensor = np.frombuffer(
66 result[output_desc.name],
67 dtype=output_desc.numpy_data_type()).reshape(output_desc.shape)
68 print("\tname:", output_desc.name, "shape:", output_tensor.shape,
69 "dtype:", output_tensor.dtype, "\n", output_tensor)
70
71 print("Success: exiting")
72 return 0
73
74
75if __name__ == "__main__":
76 main()
Download model_runner_replication.cpp
1// Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2#include <string>
3#include <unordered_map>
4#include <vector>
5
6#include <boost/program_options.hpp>
7
8#include "model_runtime/ModelRunner.hpp"
9#include "model_runtime/Tensor.hpp"
10#include "utils.hpp"
11
12/* The example shows loading a model from PopEF files, creating 2 model replicas
13 * and sending inference requests to each of them.
14 */
15int main(int argc, char *argv[]) {
16 static constexpr unsigned num_replicas = 2;
17
18 using namespace std::chrono_literals;
19 static const char *example_desc = "Model runner simple example.";
20 const boost::program_options::variables_map vm =
21 examples::parsePopefProgramOptions(example_desc, argc, argv);
22 const auto popef_paths = vm["popef"].as<std::vector<std::string>>();
23
24 model_runtime::ModelRunnerConfig config;
25 config.device_wait_config =
26 model_runtime::DeviceWaitConfig{600s /*timeout*/, 1s /*sleep_time*/};
27 examples::print(fmt::format(
28 "Setting model_runtime::ModelRunnerConfig replication_factor=",
29 num_replicas));
30
31 config.replication_factor = num_replicas;
32 model_runtime::ModelRunner model_runner(popef_paths, config);
33
34 for (unsigned replica_id = 0; replica_id < num_replicas; ++replica_id) {
35 examples::print("Allocating input tensors");
36 const model_runtime::InputMemory input_memory =
37 examples::allocateHostInputData(model_runner.getExecuteInputs());
38 examples::printInputMemory(input_memory);
39
40 examples::print(fmt::format(
41 "Sending single synchronous request with empty data - replica {}",
42 replica_id));
43
44 const model_runtime::OutputMemory output_memory = model_runner.execute(
45 examples::toInputMemoryView(input_memory), replica_id);
46
47 examples::print(fmt::format("Received output - replica {}", replica_id));
48
49 using OutputValueType =
50 std::pair<const std::string, model_runtime::TensorMemory>;
51
52 for (const OutputValueType &name_with_memory : output_memory) {
53 auto &&[name, memory] = name_with_memory;
54 examples::print(fmt::format("Output tensor {}, {} bytes", name,
55 memory.data_size_bytes));
56 }
57 }
58 examples::print("Success: exiting");
59 return EXIT_SUCCESS;
60}
3.3. Multithreading
By default, ModelRunner is not thread-safe.
When many threads call execute() or
executeAsync(), it can lead to race
conditions and undefined behaviour. To avoid this when using
ModelRunner in a multithreaded environment, you
must ensure that appropriate synchronization mechanisms are used between
threads.
The alternative is to set
thread_safe in
ModelRunnerConfig to true. Every subsequent call
of execute() or
executeAsync() will cause the
internal std::mutex
instance to lock.
The examples below first create several threads and then each thread sends inference requests to the IPU.
Download model_runner_multithreading.py
1#!/usr/bin/env python3
2# Copyright (c) 2022 Graphcore Ltd. All rights reserved.
3
4import argparse
5import threading
6from datetime import timedelta
7import numpy as np
8import model_runtime
9import popef
10"""
11The example shows loading a model from PopEF files and sending inference
12requests to the same model by multiple threads.
13"""
14
15
16def main():
17 parser = argparse.ArgumentParser("Model runner simple example.")
18 parser.add_argument(
19 "-p",
20 "--popef",
21 type=str,
22 metavar='popef_file_path',
23 help="A collection of PopEF files containing the model.",
24 nargs='+',
25 required=True)
26 args = parser.parse_args()
27
28 config = model_runtime.ModelRunnerConfig()
29 config.thread_safe = True
30 config.device_wait_config = model_runtime.DeviceWaitConfig(
31 model_runtime.DeviceWaitStrategy.WAIT_WITH_TIMEOUT,
32 timeout=timedelta(seconds=600),
33 sleepTime=timedelta(seconds=1))
34
35 print("Creating ModelRunner with", config)
36 model_runner = model_runtime.ModelRunner(model_runtime.PopefPaths(
37 args.popef),
38 config=config)
39 num_workers = 4
40 print("Starting", num_workers, "worker threads.")
41 threads = [
42 threading.Thread(target=workerMain, args=(model_runner, worker_id))
43 for worker_id in range(num_workers)
44 ]
45
46 for thread in threads:
47 thread.start()
48
49 for thread in threads:
50 thread.join()
51
52 print("Success: exiting")
53 return 0
54
55
56def workerMain(model_runner, worker_id):
57 print("Worker", worker_id, "Starting workerMain()")
58 num_requests = 5
59
60 input_descriptions = model_runner.getExecuteInputs()
61 input_requests = []
62
63 print("Worker", worker_id, "Allocating input tensors for", num_requests,
64 "requests", input_descriptions)
65 for _ in range(num_requests):
66 input_requests.append([
67 np.random.randn(*input_desc.shape).astype(
68 input_desc.numpy_data_type())
69 for input_desc in input_descriptions
70 ])
71
72 futures = []
73
74 for req_id in range(num_requests):
75 print("Worker", worker_id, "Sending asynchronous request. Request id",
76 req_id)
77 input_view = model_runtime.InputMemoryView()
78 for input_desc, input_tensor in zip(input_descriptions,
79 input_requests[req_id]):
80 input_view[input_desc.name] = input_tensor
81 futures.append(model_runner.executeAsync(input_view))
82
83 print("Worker", worker_id, "Processing outputs.")
84 for req_id, future in enumerate(futures):
85 print("Worker", worker_id, "Waiting for the result - request", req_id)
86 future.wait()
87 print("Worker", worker_id, "Result available - request", req_id)
88
89
90if __name__ == "__main__":
91 main()
Download model_runner_multithreading.cpp
1// Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2#include <array>
3#include <string>
4#include <vector>
5
6#include <boost/program_options.hpp>
7
8#include "model_runtime/ModelRunner.hpp"
9#include "model_runtime/Tensor.hpp"
10#include "utils.hpp"
11
12namespace examples {
13
14void workerMain(model_runtime::ModelRunner &model_runner);
15
16} // namespace examples
17
18/* The example shows loading a model from PopEF files and sending inference
19 * requests to the same model by multiple threads.
20 */
21int main(int argc, char *argv[]) {
22 using namespace std::chrono_literals;
23 static const char *example_desc =
24 "Model runner multithreading client example.";
25 const boost::program_options::variables_map vm =
26 examples::parsePopefProgramOptions(example_desc, argc, argv);
27 const auto popef_paths = vm["popef"].as<std::vector<std::string>>();
28
29 model_runtime::ModelRunnerConfig config;
30 config.device_wait_config =
31 model_runtime::DeviceWaitConfig{600s /*timeout*/, 1s /*sleep_time*/};
32 examples::print(
33 "Setting model_runtime::ModelRunnerConfig: thread safe = true");
34 config.thread_safe = true;
35 model_runtime::ModelRunner model_runner(popef_paths, config);
36
37 static constexpr unsigned num_workers = 4;
38 std::vector<std::thread> threads;
39 threads.reserve(num_workers);
40
41 examples::print(fmt::format("Starting {} worker threads", num_workers));
42 for (unsigned i = 0; i < num_workers; i++) {
43 threads.emplace_back(examples::workerMain, std::ref(model_runner));
44 }
45
46 for (auto &worker : threads) {
47 worker.join();
48 };
49
50 examples::print("Success: exiting");
51 return EXIT_SUCCESS;
52}
53
54namespace examples {
55
56void workerMain(model_runtime::ModelRunner &model_runner) {
57 examples::print("Starting workerMain()");
58
59 static constexpr unsigned num_requests = 5;
60 std::array<model_runtime::InputMemory, num_requests> requests_input_data;
61
62 for (unsigned req_id = 0; req_id < num_requests; req_id++) {
63 examples::print(
64 fmt::format("Allocating input tensors - request id {}", req_id));
65 requests_input_data[req_id] =
66 examples::allocateHostInputData(model_runner.getExecuteInputs());
67 }
68
69 std::vector<model_runtime::OutputFutureMemory> results;
70
71 for (unsigned req_id = 0; req_id < num_requests; req_id++) {
72 examples::print(
73 fmt::format("Sending asynchronous request. Request id {}", req_id));
74 results.emplace_back(model_runner.executeAsync(
75 examples::toInputMemoryView(requests_input_data[req_id])));
76 }
77
78 examples::print("Waiting for output:");
79 for (unsigned req_id = 0; req_id < num_requests; req_id++) {
80 auto &output_future_memory = results[req_id];
81
82 using OutputValueType =
83 std::pair<const std::string,
84 std::shared_future<model_runtime::TensorMemory>>;
85 for (const OutputValueType &name_with_future_memory :
86 output_future_memory) {
87 auto &&[name, future_memory] = name_with_future_memory;
88 examples::print(fmt::format(
89 "Waiting for the result: tensor {}, request_id {}", name, req_id));
90 future_memory.wait();
91 const model_runtime::TensorMemory &memory = future_memory.get();
92 examples::print(fmt::format(
93 "Output tensor {} available, request_id {} received {} bytes", name,
94 req_id, memory.data_size_bytes));
95 }
96 }
97}
98
99} // namespace examples
3.4. Frozen inputs
The ModelRunner class allows you to bind constant
tensor data to input tensors by setting frozen_inputs
in ModelRunnerConfig.
frozen_inputs is an instance of InputMemoryView and contains a mapping from the
input tensor names to the constant tensor data you have allocated. You allocate and pass the pointer to the constant data for the input tensors you want to freeze.
If the tensor to be frozen was required as an input during the execution call, this tensor will no longer be required and the constant tensor from frozen_inputs will instead be added to the request. If the tensor to be frozen was saved as PopEF tensor data or feed data, it will be overridden by the constant tensor from frozen_inputs.
The examples below bind a constant value to one of the inputs and sends inference requests to the IPU.
Note
These examples use a PopEF file generated by the code in Section A.3, Generating an example PopEF file.
Download model_runner_frozen_inputs.py
1#!/usr/bin/env python3
2# Copyright (c) 2022 Graphcore Ltd. All rights reserved.
3
4import os
5import argparse
6from datetime import timedelta
7import numpy as np
8import model_runtime
9import popef
10"""
11The example shows loading a model from PopEF file and binding constant tensor
12value to one of the inputs. The example is based on the PopEF file generated
13by `model_runtime_example_generate_simple_popef` example. Generated PopEF
14file consists simple model:
15
16output = (A * weights) + B
17
18where A and B are stream inputs, weights is a tensor saved as popef::TensorData
19and output is result stream output tensor.
20"""
21
22
23def main():
24 parser = argparse.ArgumentParser("Model runner simple example.")
25 parser.add_argument(
26 "-p",
27 "--popef",
28 type=str,
29 metavar='popef_file_path',
30 help="A collection of PopEF files containing the model.",
31 nargs='+',
32 required=True)
33 args = parser.parse_args()
34 model = load_model(args.popef)
35
36 frozen_input_name = "tensor_B"
37 print("Looking for tensor", frozen_input_name, "inside PopEF model.")
38 tensor_b_anchor = popef.Anchor()
39
40 for anchor in model.metadata.anchors():
41 if anchor.name() == frozen_input_name:
42 tensor_b_anchor = anchor
43 break
44 else:
45 raise Exception(f'Anchor {frozen_input_name} not found inside givem '
46 'model. Please make sure that PopEF was generated by '
47 '`model_runtime_example_generate_simple_popef`')
48
49 print("Generating", frozen_input_name, "random values")
50 tensor_b_info = tensor_b_anchor.tensorInfo()
51 tensor_b = np.random.randn(*tensor_b_info.shape()).astype(
52 tensor_b_info.numpyDType())
53
54 config = model_runtime.ModelRunnerConfig()
55
56 frozen_inputs = model_runtime.InputMemoryView()
57 frozen_inputs[frozen_input_name] = tensor_b
58 config.frozen_inputs = frozen_inputs
59
60 print(
61 "Tensor", frozen_input_name, "is frozen - will be treated as "
62 "constant in each execution request.")
63 config.device_wait_config = model_runtime.DeviceWaitConfig(
64 model_runtime.DeviceWaitStrategy.WAIT_WITH_TIMEOUT,
65 timeout=timedelta(seconds=600),
66 sleepTime=timedelta(seconds=1))
67
68 model_runner = model_runtime.ModelRunner(model, config=config)
69
70 print("Preparing input tensors:")
71 input_descriptions = model_runner.getExecuteInputs()
72 input_tensors = [
73 np.random.randn(*input_desc.shape).astype(input_desc.numpy_data_type())
74 for input_desc in input_descriptions
75 ]
76 input_view = model_runtime.InputMemoryView()
77
78 for input_desc, input_tensor in zip(input_descriptions, input_tensors):
79 print("\tname:", input_desc.name, "shape:", input_tensor.shape,
80 "dtype:", input_tensor.dtype)
81 input_view[input_desc.name] = input_tensor
82
83 print("Sending single synchronous request with empty data.")
84 result = model_runner.execute(input_view)
85 output_descriptions = model_runner.getExecuteOutputs()
86
87 print("Processing output tensors:")
88 for output_desc in output_descriptions:
89 output_tensor = np.frombuffer(
90 result[output_desc.name],
91 dtype=output_desc.numpy_data_type()).reshape(output_desc.shape)
92 print("\tname:", output_desc.name, "shape:", output_tensor.shape,
93 "dtype:", output_tensor.dtype, "\n", output_tensor)
94
95 print("Success: exiting")
96
97 return 0
98
99
100def load_model(popef_paths):
101 for model_file in popef_paths:
102 assert os.path.isfile(model_file) is True
103 reader = popef.Reader()
104 reader.parseFile(model_file)
105
106 meta = reader.metadata()
107 exec = reader.executables()
108 return popef.ModelBuilder(reader).createModel()
109
110
111if __name__ == "__main__":
112 main()
Download model_runner_frozen_inputs.cpp
1// Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2#include <algorithm>
3#include <string>
4#include <vector>
5
6#include <boost/program_options.hpp>
7
8#include <popef/Model.hpp>
9#include <popef/Reader.hpp>
10#include <popef/Types.hpp>
11
12#include "model_runtime/ModelRunner.hpp"
13#include "model_runtime/Tensor.hpp"
14#include "utils.hpp"
15
16namespace examples {
17
18std::shared_ptr<popef::Model>
19createPopefModel(const std::vector<std::string> &popef_paths);
20const popef::Anchor *findAnchor(const std::string &name, popef::Model *model);
21std::vector<float> createFrozenTensorData(const popef::Anchor *anchor);
22
23} // namespace examples
24
25/* This example loads a model from a PopEF file and binds a constant tensor
26 * value to one of the inputs. This example is based on the PopEF file generated
27 * by `model_runtime_example_generate_simple_popef`. The generated PopEF file
28 * contains a simple model:
29 *
30 * output = (A * weights) + B
31 *
32 * where A and B are stream inputs, the weights tensor is saved as
33 * popef::TensorData and the output is a stream output tensor.
34 */
35int main(int argc, char *argv[]) {
36 using namespace std::chrono_literals;
37 static const char *example_desc = "Model runner frozen inputs example.";
38 const boost::program_options::variables_map vm =
39 examples::parsePopefProgramOptions(example_desc, argc, argv);
40 const auto popef_paths = vm["popef"].as<std::vector<std::string>>();
41
42 std::shared_ptr<popef::Model> model = examples::createPopefModel(popef_paths);
43
44 static const std::string frozen_input_name = "tensor_B";
45
46 examples::print(fmt::format("Looking for tensor {} inside the PopEF model.",
47 frozen_input_name));
48 const popef::Anchor *tensor_b_anchor =
49 examples::findAnchor(frozen_input_name, model.get());
50 examples::print(fmt::format("Found {}.", *tensor_b_anchor));
51
52 examples::print("Creating frozen input tensor data.");
53 const std::vector<float> tensor_b_data =
54 examples::createFrozenTensorData(tensor_b_anchor);
55
56 examples::print("Creating ModelRunnerConfig.");
57 model_runtime::ModelRunnerConfig config;
58
59 examples::print(fmt::format("Tensor {} is frozen - will be treated as "
60 "constant in each execution request.",
61 frozen_input_name));
62 const uint64_t tensor_b_size_in_bytes =
63 tensor_b_anchor->tensorInfo().sizeInBytes();
64
65 config.frozen_inputs = {
66 {frozen_input_name, model_runtime::ConstTensorMemoryView{
67 tensor_b_data.data(), tensor_b_size_in_bytes}}};
68
69 config.device_wait_config =
70 model_runtime::DeviceWaitConfig{600s /*timeout*/, 1s /*sleep_time*/};
71
72 model_runtime::ModelRunner model_runner(model, config);
73
74 examples::print("Allocating input tensors");
75
76 const model_runtime::InputMemory input_memory =
77 examples::allocateHostInputData(model_runner.getExecuteInputs());
78
79 examples::printInputMemory(input_memory);
80
81 examples::print("Sending single synchronous request with empty data.");
82 const model_runtime::OutputMemory output_memory =
83 model_runner.execute(examples::toInputMemoryView(input_memory));
84
85 examples::print("Received output:");
86
87 using ValueType = std::pair<const std::string, model_runtime::TensorMemory>;
88
89 for (const ValueType &name_with_memory : output_memory) {
90 auto &&[name, memory] = name_with_memory;
91 examples::print(fmt::format("Output tensor {}, {} bytes", name,
92 memory.data_size_bytes));
93 }
94
95 examples::print("Success: exiting");
96 return EXIT_SUCCESS;
97}
98
99namespace examples {
100
101std::shared_ptr<popef::Model>
102createPopefModel(const std::vector<std::string> &popef_paths) {
103 auto reader = std::make_shared<popef::Reader>();
104 for (const auto &path : popef_paths)
105 reader->parseFile(path);
106
107 return popef::ModelBuilder(reader).createModel();
108}
109
110const popef::Anchor *findAnchor(const std::string &name, popef::Model *model) {
111 const auto &anchors = model->metadata.anchors();
112
113 const auto anchor_it = std::find_if(
114 anchors.cbegin(), anchors.cend(),
115 [&](const popef::Anchor &anchor) { return anchor.name() == name; });
116
117 if (anchor_it == anchors.cend()) {
118 throw std::runtime_error(fmt::format(
119 "Anchor {} not found in given model. Please make sure that PopEF was "
120 "generated by `model_runtime_example_generate_simple_popef`.",
121 name));
122 }
123
124 if (auto anchorDataType = anchor_it->tensorInfo().dataType();
125 anchorDataType != popef::DataType::F32) {
126 throw std::runtime_error(fmt::format(
127 "Example expects anchor {} with popef::DataType::F32. Received {}",
128 name, anchorDataType));
129 }
130
131 return &(*anchor_it);
132}
133
134std::vector<float> createFrozenTensorData(const popef::Anchor *anchor) {
135 const auto size_in_bytes = anchor->tensorInfo().sizeInBytes();
136 const auto num_elements = size_in_bytes / sizeof(float);
137
138 return std::vector<float>(num_elements, 11.0f);
139}
140
141} // namespace examples
3.5. Conditional execution
When a compiled graph contains one model, you must provide data for all input
and output anchors for correct execution of the graph on the IPU. This is the
default execution for a ModelRunner object.
Sometimes, a graph compiled by Poplar can contain multiple models
(Fig. 3.1). In this case, the IPU will conditionally execute
one of these models based on an input parameter (specified in an input anchor)
that selects the appropriate execution path. In order to
execute different models through one ModelRunner
instance, you must provide data for only the anchors that are
required by the IPU to perform the request.
There are two steps you must perform:
You must disable the
validate_io_paramsoption. This option checks if you have provided enough input parameters to complete the request. In other words, it checks that each parameter corresponds to an existing internal queue. By disabling it, you will be able to provide inputs for only the model you want to execute and not all models.You must know which anchors are associated with each model in the graph. When you send a request, you need to provide the data only required by the model you want to execute. The PopEF file contains information about the anchors that the graph contains, but it does not contain information about which anchors are associated with a model. You can use the popef_dump tool to display the anchors in the graph.
Note
If you provide inputs for a different model than the one you want to execute, then a timeout will occur. This will be the only information you will receive in the case of an incorrect execution of the request.
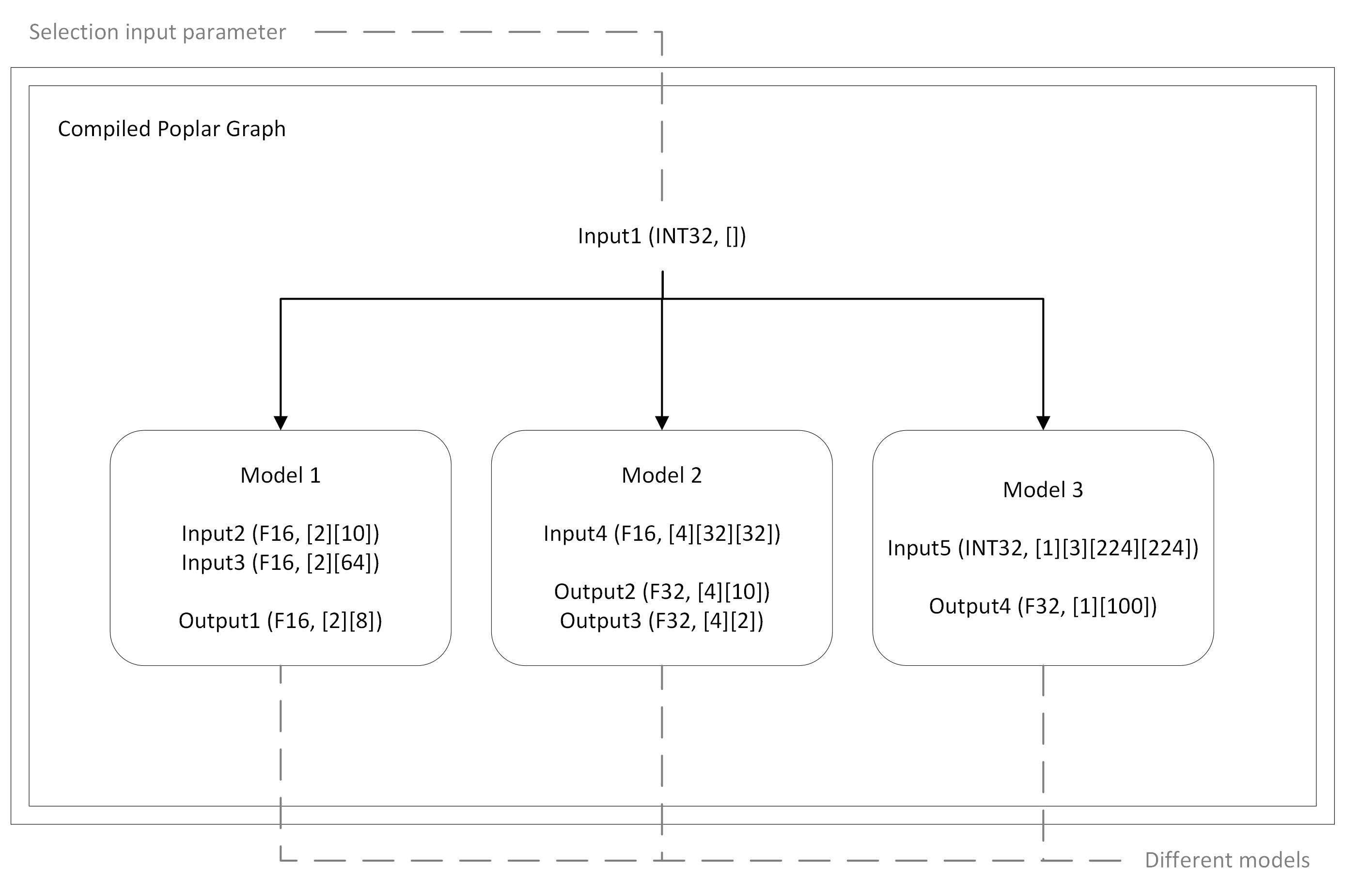
Fig. 3.1 An example graph construction with multiple models
3.6. Dynamic batch sizing
By default, ModelRunner only accepts model inputs
and outputs with batch sizes that are an integer multiple of the batch size from
the PopEF model. By setting the
batching_dim configuration option,
you can enable dynamic batch sizing which allows you to specify any batch size.
By default, dynamic batch sizing is disabled
(batching_dim == 0xFFFFFFFF).
In this case, the batch size must be an integer multiple of the batch size from
the PopEF model. For example, without dynamic batch sizing enabled and for a
PopEF model with an input shape of [3, 4, 2] where dimension 0 specifies the
batch size, ModelRunner can only accept inputs with shapes defined by [N * 3,
4, 2], (where N is any positive integer).
To enable dynamic batch sizing, we set
batching_dim to the dimension that
contains the value for the batch size. The value of batching_dim must be an
integer between 0 and max_dimension_model-1.
For example to enable dynamic batch sizing on dimension 1, you would set
batching_dim == 1. Now dimension 1 can contain any batch size. Using the
example from earlier, ModelRunner can service inference requests with input
and output shapes [4, batch_size, 2] where batch_size is any positive
integer.
3.7. Improved model fusion and I/O overlap performance
Model fusion is a concept in machine learning where the inputs and outputs of multiple small models are combined to improve the overall predictive performance for a specific problem. While Model Runtime can use the individual inputs and outputs of the smaller models as inputs and outputs into the single large model and can conditionally execute a branch related to a single (small) model, problems arise when input data is unavailable. In this case, the default Model Runtime behaviour is to flush all inputs and outputs. This degrades performance for fused models as this will execute the branches for all the different small models.
A similar situation occurs if I/O overlap is being used to improve model throughput. If there is not enough data to fill a batch, then there is a timeout. This also causes all data to be flushed.
To handle flushing of specific data in fused models or to flush some data during
I/O overlap, ModelRunnerConfig contains
flush_callback, a configuration
option that specifies a pointer to a callback function, which Model Runtime
calls once, after a timeout occurs when expected data is unavailable.
This callback function provides a mechanism to specify which input and output data is changed and how the data is changed. Input and output data can either be flushed (with null data) or the values can be updated.
The callback function must have the following parameters:
tensor_id: The ID of the tensor thatModelRunnerwas expecting when the timeout occurred.inputs: The pointer to the updated input data structure.ModelRunnerexpects to find the updated input data here after the callback returns and will then update its input queue.outputs: The pointer to the updated output data structure.ModelRunnerexpects to find the updated output data here after the callback returns and will then update its output queue.
You must assign a pointer to the callback function to the
flush_callback configuration
option.
For example, in your application, you would define:
ModelRunnerConfig config;
if (batch_size == 3)
config.flush_callback = [&inputs_to_be_flushed, &outputs_to_be_flushed](
const std::string &tensor_id,
const InputMemoryView *&inputs,
const OutputMemoryView *&outputs) {
BOOST_TEST_MESSAGE(
"flush_callback called without any change for tensor: "
<< tensor_id);
inputs = &inputs_to_be_flushed;
outputs = &outputs_to_be_flushed;
return;
};
else if (batch_size == 7)
config.flush_callback = [](const std::string &tensor_id,
const InputMemoryView *&inputs,
const OutputMemoryView *&outputs) {
BOOST_TEST_MESSAGE("Suppress the compile warning inputs: "
<< inputs << "outputs:" << outputs);
BOOST_TEST_MESSAGE(
"Return immediately in flush_callback for tensor: " << tensor_id);
return;
};
Note
The application defining the callback function must ensure that the unavailable tensor and the input and output data to be changed or flushed belong to the small model that is currently being executed. If not, inference results may become corrupted.
3.8. Monitoring statistics
ModelRunner can monitor your running inference applications and this can be easily integrated into your server framework and monitoring system. Statistics are available for the phases shown in Fig. 3.2.

Fig. 3.2 The phases that monitoring statistics are available for
You can collect the following statistics on the online server while running inference:
percentile of the latency in each phase of the request with the
getMonitoringStatisticsPercentile()funciton.time taken for different phases of the last request with the
getTimeTrace()function.mean latency in each phase with the
getMonitoringStatisticsMean()function.total number of requests in each phase with the
getMonitoringStatisticsTotalCount()function.
The collection of these metrics does not have any impact on the inference performance.
To use this in ModelRunner, you need to first set the following in ModelRunnerConfig:
flush_on_waiting_outputsto true.request_tracepoints_buffer_sizeto the size of the request tracepoint buffer. The default value is 1,000. If set to 0, the tracepoint buffer size is infinite.
Then you can call any of the monitoring functions. For example to get the P99.9 latency, you can call getMonitoringStatisticsPercentile(ms_info, 0.999) and to get the mean of the latencies, you can call getMonitoringStatisticsMean(ms_info) where
ms_info is a dictionary that contains the monitoring information. You need to pass in an empty dictionary in Python or std::map<std::string, float> in C++. The results returned, for example for Python, are as follows:
getMonitoringStatisticsPercentile()returns:{ "computation_monitoring_statistics_percentile_us": <value>, "read_queue_monitoring_statistics_percentile_us" : <value>, "request_monitoring_statistics_percentile_us" : <value>, "request_monitoring_statistics_percentile_us" : <value>, }
getTimeTrace()returns:{ "request_duration_us": <value>, "read_preparation_duration_us" : <value>, "read_queue_duration_us" : <value>, "computation_duration_us" : <value>, }
getMonitoringStatisticsMean()returns:{ "computation_monitoring_statistics_mean_us": <value>, "read_preparation_monitoring_statistics_mean_us" : <value>, "read_queue_monitoring_statistics_mean_us" : <value>, "request_monitoring_statistics_mean_us" : <value>, }
getMonitoringStatisticsTotalCount()returns:{ "read_preparation_monitoring_statistics_count": <value>, "read_queue_monitoring_statistics_count" : <value>, "computation_monitoring_statistics_count" : <value>, "request_monitoring_statistics_count" : <value>, }