6. Queue manager
The Poplar library
processes I/O operations asynchronously using
data streams. The Model Runtime
Session class wraps the Poplar mechanism using the
setUserOutputHandler() and
setUserInputHandler() functions.
This is described in detail in Section 4.5, Retrieving information from a session.
In summary, a user callback is called each time the Poplar runtime performs an I/O transfer.
Although such an approach gives you maximum flexibility, it also means you have more responsibility for the implementation. You must write the entire logic inside the callback to perform the following operations:
Copy data from or to the source
Ensure that the correct data is copied when processing multiple requests with changing inputs
Perform memory management for data I/O
Run the application when the output tensor is ready
The QueueManager class handles some of these
responsibilities and reduces the work you have to do.
QueueManager creates and registers callbacks for
each Anchor object for which an instance of your
AnchorCallbackPredicate predicate
passed to the QueueManager constructor
returns BIND_USER_CB.
Along with callbacks, QueueManager
creates and controls a set of tensor data queues, storing pointers to the
dedicated user-memory slots. Each queue is connected to the responding tensor
data stream callback and deals with transferring and receiving data received
from Poplar.
The only way to create a QueueManager object is
to use the Session method
createQueueManager(). It forwards all
parameters to the QueueManager constructor, stores
the created object in the memory owned by Session
and returns a QueueManager access pointer to the
model.
The lifetime of the QueueManager object is strictly
related to the lifetime of the Session instance.
// Assuming there is a session (Session) already created
model_runtime::QueueManager *queue_manager = session.createQueueManager();
The QueueManager instance creates one queue per
Anchor. There are two types of queues:
InputQueueprocesses input dataOutputQueueprocesses output data
Queues for the individual anchors can be accessed using
inputQueue() and
outputQueue().
Add requests to the queue using
model_runtime::InputQueue::enqueue() and
model_runtime::OutputQueue::enqueue().
For these methods, you can specify a
ReadCompleteCallback or
WriteCompleteCallback callback that will
be called when the IPU memory transfer is complete.
Each queue is based on SpscRingBuffer, which is an
implementation of a lock-free single-producer single-consumer circular FIFO
queue.
You can set the buffer size in the
QueueManager constructor. By default, the buffer
size is double the batch size (the outer tensor shape dimension).
Queues are not thread-safe, so you must ensure that an appropriate synchronization mechanism (for example std::mutex) is used between threads when adding new requests.
Queues store raw pointers to the user data. You are responsible for the memory allocation of the input and output tensors. You have to ensure that the data exists and pointers passed to the queue remain valid until a result is returned.
void enqueueInput(model_runtime::QueueManager *queue_manager,
const std::string &input_name,
void *input_data,
int64_t data_size) {
ReadStartCallback read_start_callback = [=]() {
std::cout << "Start reading " << input_name << " " << input_data
<< "\n";
};
ReadCompleteCallback read_complete_callback = [=]() {
std::cout << "Reading completed " << input_name << " " << input_data
<< "\n";
};
ReadCompleteCallback read_complete_callback = nullptr;
queue_manager->inputQueue(input_name).enqueue(input_data, data_size,
read_start_callback, read_complete_callback);
}
void enqueueOutput(model_runtime::QueueManager *queue_manager,
const std::string &output_name,
void *output_data,
int64_t data_size) {
WriteCompleteCallback write_complete_callback = [=]() {
std::cout << "Writing completed " << output_name << " "
<< output_data << "\n";
};
queue_manager->outputQueue(output_name).enqueue(output_data, data_size,
write_complete_callback, output_data);
}
// Assuming there is a session (QueueManager) already created and memory is
// allocated
// Queues are not thread_safe, in multithreaded environment appropriate
// synchronization mechanisms must be applied
static std::mutex g_i_mutex;
const std::lock_guard<std::mutex> lock(g_i_mutex);
enqueueInput(queue_manager, "input_data", static_cast<void*>(input_data),
8);
enqueueOutput(queue_manager, "output_data", static_cast<void*>(output_data),
8);
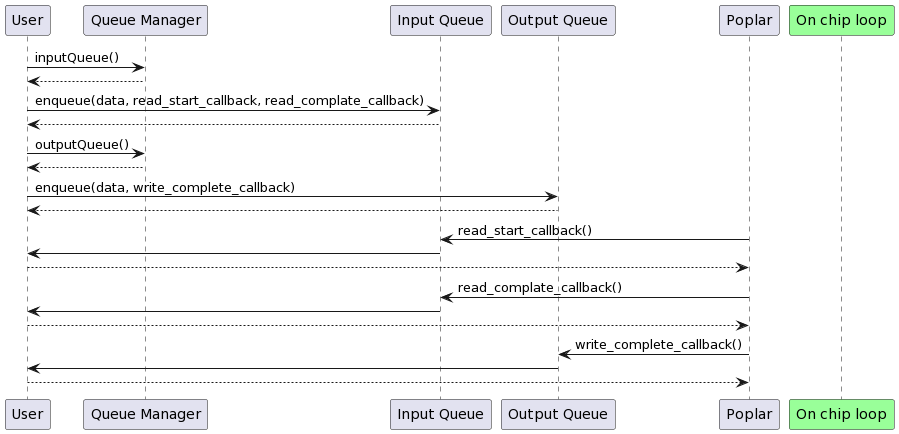
Fig. 6.1 Processing model I/O with Model Runtime queues.
This C++ example sends several inference requests to the
IPU using QueueManager.
1// Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2#include <atomic>
3#include <chrono>
4#include <cstdlib>
5#include <memory>
6#include <string>
7#include <thread>
8#include <vector>
9
10#include <boost/program_options.hpp>
11
12#include <model_runtime/DeviceManager.hpp>
13#include <model_runtime/QueueManager.hpp>
14#include <model_runtime/Session.hpp>
15
16#include "utils.hpp"
17
18int main(int argc, char *argv[]) {
19 using namespace std::chrono_literals;
20 static const char *example_desc = "Queue manager example.";
21 const boost::program_options::variables_map vm =
22 examples::parsePopefProgramOptions(example_desc, argc, argv);
23
24 auto reader = std::make_shared<popef::Reader>();
25 for (const auto &model_file : vm["popef"].as<std::vector<std::string>>()) {
26 reader->parseFile(model_file);
27 examples::print(fmt::format("Parsed {}", model_file));
28 }
29
30 popef::ModelBuilder builder(reader);
31 std::shared_ptr<popef::Model> model = builder.createModel();
32 examples::print("Model created from PopEF");
33
34 model_runtime::SessionConfig config;
35 config.policy = model_runtime::LaunchPolicy::Immediate;
36 config.wait_config =
37 model_runtime::DeviceWaitConfig{600s /*timeout*/, 1s /*sleep_time*/};
38
39 model_runtime::Session session(model, config);
40
41 examples::print("Create and configure Queue Manager");
42 const model_runtime::AnchorCallbackPredicate pred_main_or_empty =
43 examples::filterMainOrEmpty(model);
44 model_runtime::QueueManager *queue_manager = session.createQueueManager(
45 100, nullptr, 0ns, pred_main_or_empty, pred_main_or_empty);
46
47 // In case the model is configured with Prefetch and run with max_look_ahead >
48 // 0 then there is a number of inputs needed to be fetched before the first
49 // output is generated.
50 auto input_queues_feeder = [&]() {
51 for (auto &elem : queue_manager->inputs) {
52 const std::string &name = elem.first;
53 model_runtime::InputQueue &elem_queue = elem.second;
54 const popef::TensorInfo &info = elem_queue.tensorInfo();
55
56 const auto size = info.sizeInBytes();
57 // Prepare and enqueue dummy inputs
58 std::vector<char> elem_data(size, 0);
59 elem_queue.enqueue(elem_data.data(), size, [name]() {
60 examples::print(fmt::format("Enqueued data for input: {}", name));
61 });
62 }
63 };
64
65 // Prepare buffers for produced outputs
66 std::atomic<int> cnt_outputs = 0;
67 const auto num_of_outputs = queue_manager->outputs.size();
68 std::vector<std::vector<uint8_t>> outputs;
69 outputs.reserve(num_of_outputs);
70 for (const auto &out : queue_manager->outputs) {
71 const popef::TensorInfo &info = out.second.tensorInfo();
72 const auto size = info.sizeInBytes();
73 outputs.emplace_back(size);
74 }
75
76 auto output_queues_feeder = [&]() {
77 int i = 0;
78 for (auto &out : queue_manager->outputs) {
79 const std::string &name = out.first;
80 model_runtime::OutputQueue &out_queue = out.second;
81 const popef::TensorInfo &info = out_queue.tensorInfo();
82 const int64_t size = info.sizeInBytes();
83
84 out_queue.enqueue(outputs[i++].data(), size, [name, &cnt_outputs]() {
85 examples::print(fmt::format("Received output: {}", name));
86 cnt_outputs.fetch_add(1, std::memory_order::memory_order_relaxed);
87 });
88 }
89 };
90
91 examples::print("Starting data feeders");
92 auto feeders = std::thread([&]() {
93 while (cnt_outputs == 0) {
94 input_queues_feeder();
95 output_queues_feeder();
96 };
97 });
98
99 examples::print("Running load programs");
100 session.runLoadPrograms();
101
102 examples::print("Running main programs");
103 auto mainPrograms = std::thread([&]() { session.runMainPrograms(); });
104
105 examples::print("Waiting for 1st output");
106 while (cnt_outputs.load(std::memory_order_acquire) <
107 static_cast<int>(queue_manager->outputs.size()))
108 ;
109
110 examples::print("Stopping session after first output");
111 session.stop();
112
113 mainPrograms.join();
114 feeders.join();
115
116 examples::print("Success: exiting");
117 return EXIT_SUCCESS;
118}