1. Introduction
PopTorch is a set of extensions for PyTorch to enable PyTorch models to run directly on the Graphcore IPU. PopTorch has been designed to require as few changes as possible to your models in order to run on the IPU. However, it does have some differences from native PyTorch execution, to get the most out of IPU hardware. The IPU Programmer’s Guide provides an introduction to the IPU architecture, programming model and tools available.
PopTorch is included with the Poplar SDK. See the Getting Started guide for your system for how to install the Poplar SDK. Refer to Section 2, Installation for how to install the PopTorch wheel.
In the Graphcore software stack, PyTorch sits at the highest level of abstraction. Poplar and PopLibs provide a software interface to operations running on the IPU. PopTorch compiles PyTorch models into Poplar executables and also provides IPU-specific functions.
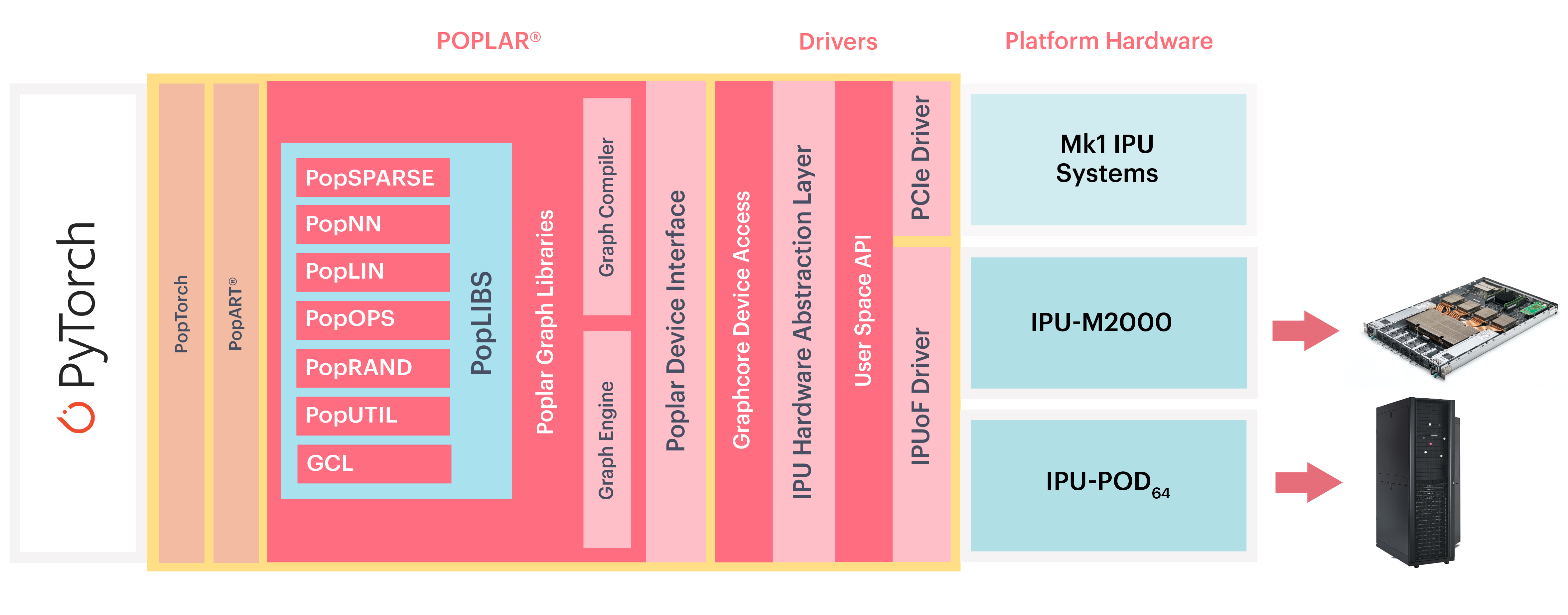
Fig. 1.1 PyTorch, PopTorch and the Poplar software stack
PopTorch supports executing native PyTorch models for both inference and training. To run a PyTorch model on the IPU, you must wrap your model with either:
Both of these functions accept a PyTorch model (torch.nn.Module) and create a representation of the model that can be executed on the IPU hardware.
In training mode, PopTorch uses its own automatic differentiation engine
(autograd) that differs from native PyTorch. The input model (torch.nn.Module)
is required to have at least one loss built into the forward pass. PopTorch
backpropagates the gradients from the loss value(s) to update the model
parameters. This is all taken care of automatically so your training loop does not
need to call .backward() on the loss value(s) or .step() on the optimiser.
The following example shows a typical native PyTorch training loop. The model
incorporates a loss criterion within the .forward() method, and returns the loss
value as a second output (along with the prediction). This native PyTorch training
loop manually invokes the .backward() method to backpropagate the gradients.
The loop also manually updates the optimiser by calling the .step() method.
1 training_data = torch.utils.data.DataLoader(ExampleDataset(shape=[1],
2 length=20000),
3 batch_size=10,
4 shuffle=True,
5 drop_last=True)
6
7 model = ExampleModelWithLoss()
8 model.train()
9
10 optimizer = torch.optim.AdamW(model.parameters(), lr=0.001)
11
12 momentum_loss = None
13
14 for batch, target in training_data:
15 # Zero gradients
16 optimizer.zero_grad()
17
18 # Run model.
19 _, loss = model(batch, target)
20
21 # Back propagate the gradients.
22 loss.backward()
23
24 # Update the weights.
25 optimizer.step()
26
27 if momentum_loss is None:
28 momentum_loss = loss
29 else:
30 momentum_loss = momentum_loss * 0.95 + loss * 0.05
31
32 if momentum_loss < 0.1:
33 optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001)
1.1. Data batching
An equivalent training loop executing the model on the IPU with PopTorch is shown
below. The DataLoader class is used to efficiently load data batches
on the IPU. PopTorch follows the data batching semantics of PopART. By default,
this means you will just pass in data of the normal batch size. However, there are a
number of options provided in PopTorch which will enable more efficient data
loading. See Section 5, Efficient data batching for more information.
Notice that the torch.optim.AdamW optimiser is passed as an input argument to the
trainingModel() wrapper which applies the optimiser algorithm
during training on the IPU. The optimiser state is automatically managed by the
PopART framework so there is no need to call the .step() method. Another
significant change from the native training loop is there is no loss.backward().
As mentioned above, PopTorch uses its own automatic differentiation engine and will
detect the loss value to backpropagate the gradients from.
1 # Set up the PyTorch DataLoader to load that much data at each iteration
2 opts = poptorch.Options()
3 opts.deviceIterations(10)
4 training_data = poptorch.DataLoader(options=opts,
5 dataset=ExampleDataset(shape=[1],
6 length=20000),
7 batch_size=10,
8 shuffle=True,
9 drop_last=True)
10
11 model = ExampleModelWithLoss()
12 model.train()
13
14 optimizer = torch.optim.AdamW(model.parameters(), lr=0.001)
15
16 # Wrap the model in a PopTorch training wrapper
17 poptorch_model = poptorch.trainingModel(model,
18 options=opts,
19 optimizer=optimizer)
20
21 momentum_loss = None
22
23 for batch, target in training_data:
24 # Performs forward pass, loss function evaluation,
25 # backward pass and weight update in one go on the device.
26 _, loss = poptorch_model(batch, target)
27
28 if momentum_loss is None:
29 momentum_loss = loss
30 else:
31 momentum_loss = momentum_loss * 0.95 + loss * 0.05
32
33 # Optimizer can be updated via setOptimizer.
34 if momentum_loss < 0.1:
35 poptorch_model.setOptimizer(
36 torch.optim.AdamW(model.parameters(), lr=0.0001))
1.2. Parallel and Distributed execution
To scale your models, you can enable Multi-IPU execution strategies using the PopTorch Annotations to label or wrap individual parts of your model and assign parts of the model to an individual IPU or execution phase. You can also use PopTorch’s Available execution strategies to determine how the model executes the phases.
Having assigned the model to run on one or more IPUs, you can add additional parallelism with replication. Each replica represents an additional copy of the entire model. These copies run in parallel.
PopTorch can also run across multiple hosts. This is necessary for using more than 64 IPUs across IPU Pod systems and may be beneficial when using a smaller number of IPUs, for example with models that involve intensive pre-processing on the CPU. We recommend using the PopRun command-line tool and and PopDist configuration library, which can automatically set up PopTorch to run across multiple IPU-POD hosts. Refer to the PopDist and PopRun User Guide for more information, including details about the installation of Horovod if you are using the MPI communication protocol.
1.3. Constraints
The following constraints apply when using PopTorch:
All tensor data types and shapes must be constant for the entire dataset.
As PopTorch compiles to a static graph, it cannot handle control flow variations within the model. This means that the inputs passed at run-time cannot vary the control flow of the model or the shapes or sizes of results. If this is attempted, the graph will be frozen to whichever control flow path was activated as a result of the first inputs given to the wrapped model.
Not all PyTorch operations are implemented within the PopTorch compiler. See Section 6, IPU supported operations for a list of operators that are supported on the IPU. Please also report any unsupported operators to support@graphcore.ai so that these ops may be incorporated into a future release.
Whilst any argument type can be used in the forward method, only tensor arguments may change between model invocations, as other types will be statically compiled inside the executable.
1.4. Other resources
Switching from GPUs to IPUs for Machine Learning Models provides a high-level overview of the programming changes required when switching from GPUs to IPUs and Memory and Performance Optimisation on the IPU presents guidelines to help you develop high-performance machine learning models running on the IPU.
The Graphcore Examples GitHub repository contains PopTorch applications, feature examples, tutorials and simple applications. Further developer resources can be found on Graphcore’s developer portal.