4. Features
4.1. Options
You can change how PopTorch compiles and executes models using Options.
You can find a full list of options in Section 11.1, Options.
Broadly speaking, the options fall into the following categories:
General options (see
Options)Options related to half precision (see
opts.Precision.*)Management of the training process (see
opts.Training.*)Location of tensors (see:
opts.TensorLocations.*andTensorLocationSettings)Options relevant to the Torch JIT compiler (see
opts.Jit.*)Control of distributed execution environments when using tools other than PopRun (see
opts.Distributed.*)
See Section 5, Efficient data batching for a full
explanation of how deviceIterations(),
gradientAccumulation() and
replicationFactor() interact with a model’s input and
output sizes.
You can choose to use the IPU Model instead of IPU hardware
with the useIpuModel() option.
4.1.1. Setting options via config file
In addition to setting these options programmatically, you can also set them in a
config text file by using loadFromFile().
Each line in the file must contain a single command corresponding to setting an option
in Options. To set an option within the file, write the command as you
would within a Python script but omit the options. prefix. For example:
1deviceIterations(1)
2setExecutionStrategy(poptorch.ShardedExecution())
3replicationFactor(1)
4enableSyntheticData(True)
Then, instantiate Options and call loadFromFile():
1opts = poptorch.Options()
2opts.loadFromFile("tmp/poptorch.conf")
4.2. Model wrapping functions
The basis of PopTorch integration comes from the two model wrapping functions described in the following sections.
Note
PopTorch makes a shallow copy of the model. Changes to the parameters
in the models returned by these two model wrapping functions affect the
original model and vice versa. However, primitive variable types will not be
kept in sync. This includes the training bool of pytorch.nn.Module.
If your PyTorch model is named model, call model.eval() or
model.train(), if required, before calling these wrapping functions.
4.2.1. poptorch.trainingModel
This function wraps a PyTorch model, yielding a PopTorch model that can
be run on the IPU in training mode. See trainingModel() for
more information.
1import torch
2import poptorch
3
4
5class ExampleModelWithLoss(torch.nn.Module):
6 def __init__(self):
7 super().__init__()
8 self.fc = torch.nn.Linear(10, 10)
9 self.loss = torch.nn.MSELoss()
10
11 def forward(self, x, target=None):
12 fc = self.fc(x)
13 if self.training:
14 return fc, self.loss(fc, target)
15 return fc
16
17
18torch.manual_seed(0)
19model = ExampleModelWithLoss()
20
21# Wrap the model in our PopTorch annotation wrapper.
22poptorch_model = poptorch.trainingModel(model)
23
24# Some dummy inputs.
25input = torch.randn(10)
26target = torch.randn(10)
27ones = torch.ones(10)
28
29# Train on IPU.
30for i in range(0, 800):
31 # Each call here executes the forward pass, loss calculation, and backward
32 # pass in one step.
33 # Model input and loss function input are provided together.
34 poptorch_out, loss = poptorch_model(input, target)
35 print(f"{i}: {loss}")
36
37# Copy the trained weights from the IPU back into the host model.
38poptorch_model.copyWeightsToHost()
39
40# Execute the trained weights on host.
41model.eval()
42native_out = model(input)
43
44# Models should be very close to native output although some operations are
45# numerically different and floating point differences can accumulate.
46torch.testing.assert_close(native_out, poptorch_out, rtol=1e-04, atol=1e-04)
Note
By default, PopTorch will only return the final batch of outputs.
Please see Section 5.7, poptorch.Options.outputMode for details on what PopTorch returns
when using trainingModel() and how you can calculate
statistics such as training accuracy over all batches.
4.2.2. poptorch.inferenceModel
This function wraps a PyTorch model, yielding a PopTorch model that can
be run on the IPU in inference mode. See inferenceModel() for
more information.
1import torch
2import torchvision
3import poptorch
4
5# Some dummy imagenet sized input.
6picture_of_a_cat_here = torch.randn([1, 3, 224, 224])
7
8# The model, in this case a MobileNet model with pretrained weights that comes
9# canned with PyTorch.
10model = torchvision.models.mobilenet_v2(pretrained=True)
11model.train(False)
12
13# Wrap in the PopTorch inference wrapper
14inference_model = poptorch.inferenceModel(model)
15
16# Execute on IPU.
17out_tensor = inference_model(picture_of_a_cat_here)
18
19# Get the top 5 ImageNet classes.
20top_five_classes = torch.topk(torch.softmax(out_tensor, 1), 5)
21print(top_five_classes)
22
23# Try the same on native PyTorch
24native_out = model(picture_of_a_cat_here)
25
26native_top_five_classes = torch.topk(torch.softmax(native_out, 1), 5)
27
28# Models should be very close to native output although some operations are
29# numerically different and floating point differences can accumulate.
30assert any(top_five_classes[1][0] == native_top_five_classes[1][0])
31# inference_half_start
32model = torch.nn.Linear(1, 10)
33
34# Cast the parameters (weights) to half.
35model.half()
36
37t1 = torch.tensor([1.]).half()
38
39opts = poptorch.Options()
40
41inference_model = poptorch.inferenceModel(model, opts)
42out = inference_model(t1)
43
44assert out.dtype == torch.half
45# inference_half_end
4.2.3. poptorch.PoplarExecutor
You should not create this class directly. It is a wrapper around the model
that was passed into inferenceModel() or trainingModel().
It has a few methods which you can use to interface with the IPU.
The PoplarExecutor will implicitly keep in sync the
parameters of the source PyTorch model and the PopTorch model(s). However, you
need to explicitly copy the weights before you run a model on the IPU if you
train the model on the CPU after you have already wrapped it for the IPU. You
also need to explicitly copy the weights if you alter an already wrapped model
parameter by some other means.
See PoplarExecutor for a complete description of the IPU interface
functionality.
1model = Model()
2model.eval()
3
4poptorch_inf = poptorch.inferenceModel(model)
5
6# Switch for "poptorch.trainingModel": poptorch_inf will remain in "eval" mode
7model.train()
8poptorch_train = poptorch.trainingModel(model)
9
10# train on IPU
11train(poptorch_train)
12torch.save(model.state_dict(), "model.save") # OK
13
14# Aready in "eval" mode
15validate(poptorch_inf) # OK
16
17# switch to "eval" mode for CPU
18model.eval()
19validate(model) # OK
20
21# train on CPU
22model.train()
23train_on_cpu(model)
24
25# Explicit copy needed
26poptorch_inf.copyWeightsToDevice()
27validate(poptorch_inf)
4.2.4. poptorch.isRunningOnIpu
One useful utility function is isRunningOnIpu(). This
returns True when executing on the IPU and False when executing
the model outside IPU scope. This allows for different code paths within
the model.
A common use case is executing equivalent code to a PopART custom operator when running on the CPU. For example:
class Network(torch.nn.Module):
def forward(self, x, y):
if poptorch.isRunningOnIpu():
# IPU path
return my_custom_operator(x, y)
else:
# CPU path
return my_torch_implementation(x,y)
4.3. Error handling
4.3.1. Recoverable runtime errors
This category of error is likely to be transient.
Exception type raised by PopTorch: poptorch.RecoverableError (inherits from poptorch.Error)
The exception contains the action required to recover from this error in its recovery_action string attribute.
This attribute can contain:
IPU_RESET: Reset the IPU and reload the IPU memory.
LINK_RESET: Reset the IPU-Links in a non-Pod system. This retrains the IPU-Links between IPUs.
PARTITION_RESET: Reset the IPU partition in a Pod system. This retrains the IPU-Links between IPUs.
FULL_RESET: Power cycle the system.
4.3.2. Unrecoverable runtime errors
These errors are likely to persist. You should take the system out of operation for analysis and repair.
Exception type raised by PopTorch: poptorch.UnrecoverableError (inherits from poptorch.Error)
4.3.3. Application and other errors
This kind of error is due to an error in the program or a misuse of an API.
Exception type raised by PopTorch: poptorch.Error if the error was detected in the C++ backend, or some generic Python Exception if it happened in the Python layer.
poptorch.Error has the following string attributes:
messageThe error message without any of the context.
typeThe part of the software stack that raised the exception and the category of the error if available.
locationWhere the exception was raised.
Example:
1 try:
2 m = PytorchModel(model_param)
3 inference_model = poptorch.inferenceModel(m)
4 t1 = torch.tensor([1.])
5 t2 = torch.tensor([2.])
6 assert inference_model(t1, t2) == 3.0
7 except poptorch.RecoverableError as e:
8 print(e)
9 if e.recovery_action == "FULL_RESET":
10 reboot_server()
11 elif e.recovery_action == "IPU_RESET":
12 print("Need to reset the IPU")
13 elif e.recovery_action == "PARITION_RESET":
14 print("Need to reset the partition")
15 except poptorch.UnrecoverableError as e:
16 print(f"Unrecoverable error: machine needs to be taken offline: {e}")
17 shutdown_system()
18 except poptorch.Error as e:
19 print(f"Received {e.message} from component {e.type}, "
20 f"location: {e.location}")
21 # Or you could just print all the information at once:
22 print(e)
23 except Exception as e:
24 print(e)
4.4. Multi-IPU execution strategies
This section describes strategies to run PopTorch code on more than one IPU.
Some of these allow you to run code in parallel on multiple IPUs.
You will need to use one of these execution strategies for PopTorch code that
does not fit on a single IPU, but if you do not explicitly select one,
PopTorch will use the default execution strategy,
PipelinedExecution.
Note
In general, we advise pipelining over as few IPUs as possible. However, You may need to experiment to find the optimal pipeline length. In some corner cases, a longer pipeline can lead to faster throughput.
There are four kinds of execution strategies that you can use to run a model on a multi-IPU device:
You can select this with the
setExecutionStrategy() option.
The following subsections first introduce the general functions which are relevant to all four parallel execution strategies. Next, they explain the four strategies with examples.
By default, PopTorch will not let you run the model if the number of IPUs is
not a power of 2.
For this reason, it is preferable to annotate the model so that the number of
IPUs used is a power of 2.
However, you can also enable autoRoundNumIPUs() to
automatically round up the number of IPUs reserved to a power of 2, with the
excess being reserved but idle.
This option is not enabled by default to prevent unintentional overbooking of
IPUs.
4.4.1. Annotations
In PopTorch, you can divide a model into blocks. Blocks are associated to stages and stages can be grouped into phases. This chapter will describe how to define them and how to use them to set up different execution modes.
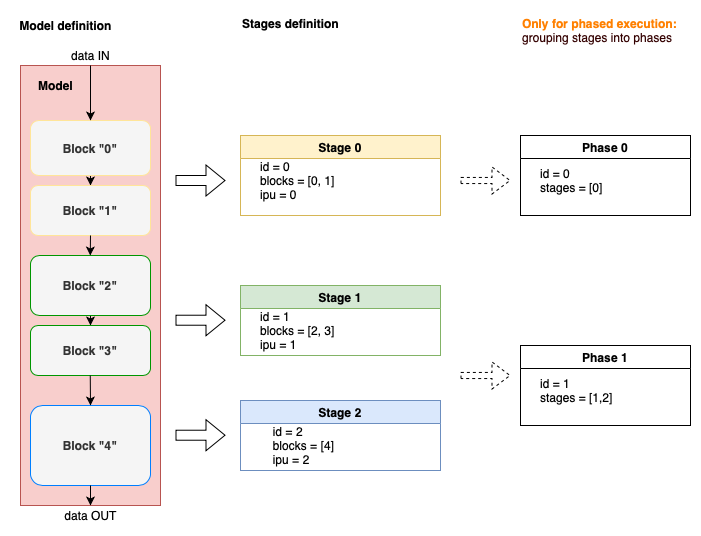
Fig. 4.1 PopTorch model partition summary
Model partitioning using blocks
BeginBlock is a wrapper class, Block
is a context manager, and BlockFunction() is a function
decorator. You can use one or more of these to partition models into “blocks”
that can be executed on different IPUs.
You can use BeginBlock to annotate an existing model. Each
call, with example arguments (layer_n, ipu_id=m), places layers enclosed in
layer_n on IPU m. Note that, PopTorch places the first layers on
ipu_id 0 by default. However, layers in between
BeginBlock annotations will inherit that of the previous
annotated block.
1import transformers
2import torch
3import poptorch
4
5# A bert model from hugging face. See the packaged BERT example for actual usage.
6pretrained_weights = 'mrm8488/bert-medium-finetuned-squadv2'
7
8
9# For later versions of transformers, we need to wrap the model and set
10# return_dict to False
11class WrappedModel(torch.nn.Module):
12 def __init__(self):
13 super().__init__()
14 self.wrapped = transformers.BertForQuestionAnswering.from_pretrained(
15 pretrained_weights)
16
17 def forward(self, input_ids, attention_mask, token_type_ids):
18 return self.wrapped.forward(input_ids,
19 attention_mask,
20 token_type_ids,
21 return_dict=False)
22
23 def __getattr__(self, attr):
24 try:
25 return torch.nn.Module.__getattr__(self, attr)
26 except AttributeError:
27 return getattr(self.wrapped, attr)
28
29
30model = WrappedModel()
31
32# A handy way of seeing the names of all the layers in the network.
33print(model)
34
35# All layers before "model.bert.encoder.layer[0]" will be on IPU 0 and all layers from
36# "model.bert.encoder.layer[0]" onwards (inclusive) will be on IPU 1.
37model.bert.encoder.layer[0] = poptorch.BeginBlock(model.bert.encoder.layer[0],
38 ipu_id=1)
39
40# Now all layers before layer are on IPU 1 and this layer onward is on IPU 2
41model.bert.encoder.layer[2] = poptorch.BeginBlock(model.bert.encoder.layer[2],
42 ipu_id=2)
43
44# Finally all layers from this layer till the end of the network are on IPU 3.
45model.bert.encoder.layer[4] = poptorch.BeginBlock(model.bert.encoder.layer[4],
46 ipu_id=3)
47
48# We must batch the data by at least the number of IPUs. Each IPU will still execute
49# whatever the model batch size is.
50data_batch_size = 4
51
52# Create a poptorch.Options instance to override default options
53opts = poptorch.Options()
54opts.deviceIterations(data_batch_size)
Note
The BeginBlock annotations internally use PyTorch hooks.
If the module passed to BeginBlock() uses hooks, for example with
register_forward_pre_hook,
then the assignment of operations to blocks may depend on the order those hooks are added.
A concrete example may help to clarify this: consider a layer, and an operation that is defined in a hook function.
If register_forward_pre_hook() is called on the layer, followed by a call to BeginBlock() passing the same layer as argument,
then the operation defined in the hook will be assigned to the preceding block (so not the same block as the layer).
If instead the call to BeginBlock() happens before register_forward_pre_hook(), then the operation
will be assigned in the same block as the layer.
You can use Block to annotate a model from within its
definition. This context manager class defines a scope in the context of
the model. Everything within that scope is placed on the IPU specified (unless
overridden by a Stage).
1class Network(torch.nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.layer1 = torch.nn.Linear(5, 10)
5 self.layer2 = torch.nn.Linear(10, 5)
6 self.layer3 = torch.nn.Linear(5, 5)
7 self.layer4 = torch.nn.Linear(5, 5)
8
9 self.act = torch.nn.ReLU()
10 self.softmax = torch.nn.Softmax(dim=1)
11
12 def forward(self, x):
13
14 # Explicit layers on a certain IPU
15 poptorch.Block.useAutoId()
16 with poptorch.Block(ipu_id=0):
17 x = self.act(self.layer1(x))
18
19 with poptorch.Block(ipu_id=1):
20 x = self.act(self.layer2(x))
21
22 with poptorch.Block(ipu_id=2):
23 x = self.act(self.layer3(x))
24 x = self.act(self.layer4(x))
25
26 with poptorch.Block(ipu_id=3):
27 x = self.softmax(x)
28 return x
29
30
31model = Network()
32opts = poptorch.Options()
33opts.deviceIterations(4)
34poptorch_model = poptorch.inferenceModel(model, options=opts)
35print(poptorch_model(torch.rand((4, 5))))
36
In addition, you can use the BlockFunction() function decorator
to place functions (containing one or more layers) onto a particular block.
Everything within that function is placed on the IPU specified (unless
overridden by a Stage).
1class Network(torch.nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.layer1 = torch.nn.Linear(5, 10)
5 self.layer2 = torch.nn.Linear(10, 5)
6 self.layer3 = torch.nn.Linear(5, 5)
7 self.layer4 = torch.nn.Linear(5, 5)
8
9 self.act = torch.nn.ReLU()
10 self.softmax = torch.nn.Softmax(dim=1)
11
12 def forward(self, x):
13 poptorch.Block.useAutoId()
14 x = self.block_one(x)
15 x = self.block_two(x)
16 x = self.final_activation(x)
17 return x
18
19 @poptorch.BlockFunction(ipu_id=0)
20 def block_one(self, x):
21 x = self.act(self.layer1(x))
22 x = self.act(self.layer2(x))
23 return x
24
25 @poptorch.BlockFunction(ipu_id=1)
26 def block_two(self, x):
27 x = self.act(self.layer3(x))
28 x = self.act(self.layer4(x))
29 return x
30
31 @poptorch.BlockFunction(ipu_id=1)
32 def final_activation(self, x):
33 return self.softmax(x)
34
35
36model = Network()
37opts = poptorch.Options()
38opts.deviceIterations(4)
39poptorch_model = poptorch.inferenceModel(model, options=opts)
40print(poptorch_model(torch.rand((4, 5))))
You can use any, or a combination, of these three annotation options.
In the above examples, ipu_id is used to specify blocks. This alone is
sufficient to enable parallel execution: by default,
AutoStage will set up a pipeline for which the pipeline
stage is equal to the ipu_id for each block. However, it would be equally
valid to instead use the user_id argument to assign names to each block.
Then, using Stage or Phase classes,
you can manually assign each block in a pipeline using their names, as outlined
in the next sections.
BeginBlock, Block and
BlockFunction() need to follow a set of rules:
You must declare all the layers inside a
Blockscope, using either the context manager orBlockFunction(), to avoid missing annotations.BeginBlockdoes not have this constraint because all the layers called after this will automatically be added to the lastBeginBlock.Note that PopTorch needs to reserve IPUs in powers of 2. You are advised to configure your model accordingly to take full advantage of the IPUs available. However, if you need to run with a different number of IPUs, you can use
poptorch.Options().autoRoundNumIPUs(True)to allow PopTorch to reserve more IPUs than the model specifies.You should not include unused or dead layers in any
BeginBlockorBlock.If layer A happens before layer B inside the model and each layer has a
BeginBlockassociated with it, you need to writeBeginBlockfor layer A beforeBeginBlockfor layer B.
Failing to obey above rules will result in compilation errors.
poptorch.Stage and poptorch.AutoStage
Conceptually, BeginBlock and
Block collect the
layers of a model into a Stage.
You can combine multiple stages into a Phase.
Multiple phases form an execution strategy.
poptorch.Stage
Stage defines the layers of the model to run on one IPU.
A stage can consist of one or more blocks created using
BeginBlock or Block
and identified by their user_id.
You can define consecutive layers in a model in either the same stage or consecutive stages. Whether stages run in parallel or sequentially depends on the specific execution strategy.
Internally, each operation in a model is assigned a stage_id
through Stage.
poptorch.AutoStage
You can use AutoStage if you don’t want to
specify stages by hand.
This will assign one Stage
per BeginBlock or Block.
By default, AutoStage.SameAsIpu is true, which means the
stage_id of the Stage will be set to the ipu_id
specified for the BeginBlock or
Block.
Note that stage_id must have ascending values in
PipelinedExecution.
Let’s use the code example above.
If your blocks “0”, “1”, and “2” are assigned to IPU 0, 1, and 0.
Then the Block
“2” will be assigned stage_id 0. This will cause
the compiler to fail to
schedule the last two stages “1” and “2” due to a conflict:
The model implies “1” should run earlier than “2”
Their
stage_idvalues suggest “2” should run earlier than “1”
When AutoStage.AutoIncrement is true, each new
BeginBlock or
Block will be assigned an automatically incremented
stage_id.
In the previous example the last stage would be assigned stage_id 2 and
the compilation would succeed.
poptorch.Phase
Phase defines a processing unit of phased execution.
It can contain one or more Stage stages.
Phase is only used in
SerialPhasedExecution and
ParallelPhasedExecution.
It is not used in
ShardedExecution and
PipelinedExecution.
1class Model(torch.nn.Module):
2 def forward(self, x, y):
3 with poptorch.Block("A"):
4 c = x + x
5 with poptorch.Block("B"):
6 d = y + y
7 with poptorch.Block("C"):
8 e = x * 3
9
10 return c, d, e
11
12
13first = poptorch.Phase(poptorch.Stage("A").ipu(0))
14# Regrouped in a single stage
15second = poptorch.Phase(poptorch.Stage("B", "C").ipu(1))
16# 2 separate stages
17second = poptorch.Phase(poptorch.Stage("B").ipu(1), poptorch.Stage("C").ipu(3))
In the code snippet above, “A” and “B” will run in parallel on IPUs 0 and 1 simultaneously because they are placed in two stages. They will run sequentially on one IPU if they are placed in a single stage.
Advanced annotation with strings
You can use Python strings to represent the user_id and ipu_id for a
Block or
BeginBlock.
Because strings are evaluated at runtime,
they allow for a dynamic number of stages and phases.
Here is an example showing how to use formatted strings(f-strings) in
ParallelPhasedExecution.
In Listing 4.11, there are several places where f-strings are used:
Line 25:
f"phase{phase}_ipu{ipu}", wherephasehas the values 0, 1, 1, 2, 3, 3, 4, 5, and 5, andipuranges from 0 to 1. The total number of instances for this f-string is 12, from 6 phases and 2 IPUs.Line 32:
f"phase{N*2-1}_ipu1", wherephaseis 5 andipuis 1.Lines 46-47 and 50-51: when defining
Stage, four f-strings are used wherenranges from 0 to 2f"phase_{2*n}_ipu0"f"phase{2*n}_ipu1"f"phase_{2*n+1}_ipu0"f"phase{2*n+1}_ipu1"
These refer to phases 0, 2, 4 and 1, 3, 5, with
ipu0andipu1, respectively. So all these 12 f-strings are defined inBeginBlock, and used inStagedynamically. These match exactly.
1poptorch.setLogLevel("DEBUG") # Force debug logging
2N = 3
3size = 10
4
5
6class Model(torch.nn.Module):
7 def __init__(self):
8 super().__init__()
9 self.weights = torch.nn.ParameterList([
10 torch.nn.Parameter(torch.rand(size, size), requires_grad=True)
11 for n in range(N * 6)
12 ])
13
14 def forward(self, in0, target=None):
15 phase = 0
16 weight = iter(self.weights)
17 with poptorch.Block("phase0_ipu0"):
18 ins = torch.split(in0, size)
19 for n in range(N * 3):
20 out = []
21 for ipu in range(2):
22 x = ins[ipu]
23 with poptorch.Block(f"phase{phase}_ipu{ipu}"):
24 x = torch.matmul(next(weight), x)
25 out.append(F.relu(x))
26 ins = out[1], out[0]
27 # We want 2 matmuls in the same phase
28 if n % 3 != 1:
29 phase += 1
30 with poptorch.Block(f"phase{N*2-1}_ipu1"):
31 res = ins[0] + ins[1]
32 if target is None:
33 return res
34 return res, torch.nn.L1Loss(reduction="mean")(res, target)
35
36
37input = torch.rand(size * 2, 1)
38target = torch.rand(size, 1)
39model = Model()
40opts = poptorch.Options()
41phases = []
42# Alternate between 0-2 and 1-3
43for n in range(N):
44 phases.append([
45 poptorch.Stage(f"phase{2*n}_ipu0").ipu(0),
46 poptorch.Stage(f"phase{2*n}_ipu1").ipu(2)
47 ])
48 phases.append([
49 poptorch.Stage(f"phase{2*n+1}_ipu0").ipu(1),
50 poptorch.Stage(f"phase{2*n+1}_ipu1").ipu(3)
51 ])
52opts.setExecutionStrategy(poptorch.ParallelPhasedExecution(*phases))
53poptorch_model = poptorch.trainingModel(model, opts)
54poptorch_model.compile(input, target)
55
With the above functions as building blocks, you can set execution strategies using the four kinds of execution modes, as shown below.
4.4.2. Available execution strategies
Note that you can use the same annotation for each execution strategy. They only differ in the method of parallelisation and tensor locations.
Pipelined execution
PipelinedExecution is the default execution strategy.
When running a model for inference with
PipelinedExecution, you must set deviceIterations() to be greater than or equal to
the number of pipeline stages used by the model. You can also do this for
training to improve efficiency.
Each time you switch IPU, PopTorch adds a new pipeline stage. If two consecutive blocks/stages use the same IPU, PopTorch will merge them into a single block/stage. It is usually better not to revisit an IPU, creating more than one pipeline stage on the same IPU, because the IPU can not run both stages at the same time. Hence in most cases, the number of pipeline stages for inference will be equal to the number of IPUs you have used.
When training, PopTorch doubles the number of pipeline stages in order to run backpropagation, except for the last forward stage which becomes a combined forward and backward pipeline stage (Fig. 4.2).
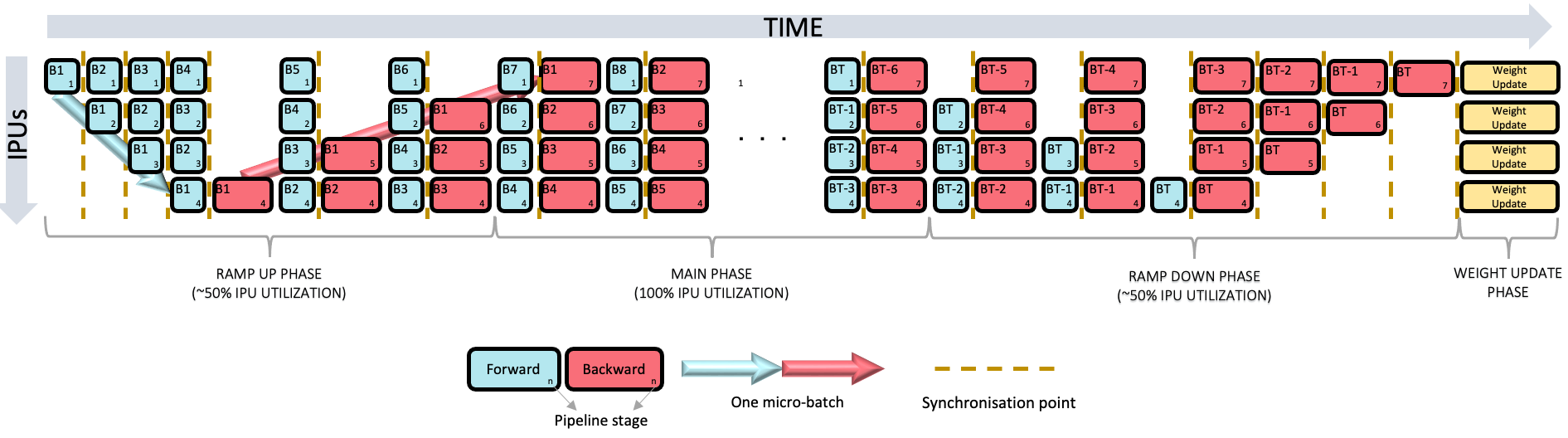
Fig. 4.2 PopTorch pipelined execution for training. The last forward stage is combined with the first backward stage.
You must set
gradientAccumulation() to be greater
than or equal to the number of pipeline stages (forward and backward).
As well as these constraints, you must also consider that the number of batches
obtained each time you call the model will be multiplied (from the conventional
model batch size, known as the micro-batch size) by
deviceIterations() *
(replicationFactor() / input_group_size) *
gradientAccumulation() during
training and deviceIterations() *
(replicationFactor() / input_group_size) during
inference (for details of input_group_size see
replicationFactor()). You can use
poptorch.DataLoader to abstract this calculation but
you should still be aware that this will take place.
Note
The effective or conventional batch size for layers which depend on it
(such as batch normalization) is known as the micro-batch size. If you use
DataLoader, the batch_size which you pass to it is
the micro-batch size.
After each IPU has finished processing a micro-batch, the same IPU immediately starts processing the next micro-batch while the next IPU processes the micro-batch that the same IPU just processed. This creates a pipeline which processes multiple micro-batches in parallel.
An IPU can only start its own stage of a micro-batch after the previous stage of that micro-batch has been processed. Hence, not all IPUs will be occupied until after a “ramp-up” period.
There is also a “ramp-down” period at the end of processing, during which there
are no new micro-batches entering the pipeline for the first IPU to process while
the IPUs down the pipeline still have micro-batches to process. Hence, during
this period, the number of IPUs occupied will reduce each step. For this reason,
you should try using a larger value for
gradientAccumulation(). But you
should note that reducing the frequency of parameter updates will also have
an adverse effect on training.
Although you only define the Phase for forward passes,
the corresponding phases for backward passes are also created.
Sharded execution
In this strategy, each IPU
will sequentially execute a distinct part of the model.
A single unit of processing ShardedExecution is called a
shard.
A shard is specified using Stage,
or if no Stage is specified,
the user_id passed by
BeginBlock or Block is used.
Each shard is executed sequentially on a single IPU (Fig. 4.3).
You can place multiple shards on multiple IPUs.
However, only one IPU is used at a time, while
the other IPUs are idle.
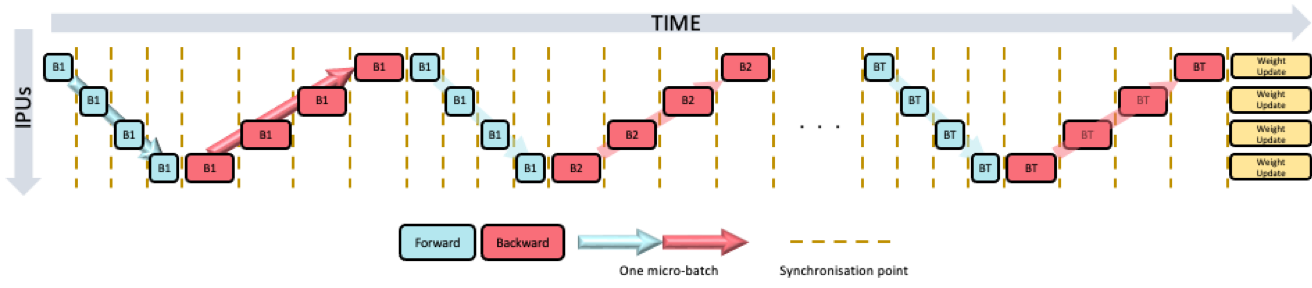
Fig. 4.3 PopTorch sharded execution for training.
If an IPU is allocated to run consecutive stages, PopART will merge consecutive stages into one on the same IPU. Weights and activations will use the on-chip memory of the IPUs. You need to place layers that share weights on the same IPU.
ShardedExecution can be useful
for processing a single sample or for debugging.
Overall, it has low efficiency because only one IPU is used at a time.
Phased execution
ParallelPhasedExecution and
SerialPhasedExecution have the following
features in common:
A portion of the weights and activations are transferred to and from Streaming Memory, before and after each phase.
If the desired weights and activations are already stored in an IPU of the same group of IPUs, intra-phase cross-IPU copies can replace the copies to and from Streaming Memory.
This specific portion is needed by the layers of the model wrapped in
BeginBlockorBlockin currentPhase.They both trade off some performance for larger models with higher memory needs.
Any number of phases is allowed.
The number of stages in each
Phaseshould match the number of IPUs in each group of IPUs.Stages inside each
Phasecan run in parallel.
Although you only define the Phase for forward passes,
the corresponding phases for backward passes are also created.
The order of phased execution for backward passes won’t change
but you can decide whether a phase is shared by both
forward and backward passes. In other words, you decide whether to avoid
a memory transfer of a portion of the weights and activations.
Serial phased execution
In SerialPhasedExecution,
phases execute on a single group of IPUs sequentially.
1strategy = poptorch.SerialPhasedExecution(
2 poptorch.Phase(poptorch.Stage("A"), poptorch.Stage("A2")),
3 poptorch.Phase(poptorch.Stage("B"), poptorch.Stage("B2")),
4 poptorch.Phase(poptorch.Stage("C"), poptorch.Stage("C2")))
5
6strategy.phase(0).ipus(0, 1)
7strategy.phase(1).ipus(0, 1)
8strategy.phase(2).ipus(0, 1)
9
10opts.setExecutionStrategy(strategy)
The code above causes all phases to run serially on IPUs 0 and 1. (A,B and C on IPU 0, A2, B2, C2 on IPU 1).
Parallel phased execution
In ParallelPhasedExecution,
phases are executed in parallel alternating between two groups of IPUs.
Even phases must run on even IPUs and odd phases on odd IPUs.
Inter-phase cross-IPU copies can replace the memory transfers to and from
the Streaming Memory, if the desired weights and activations are already
available in another group of IPUs.
1strategy = poptorch.ParallelPhasedExecution(
2 poptorch.Phase(poptorch.Stage("0"), poptorch.Stage("1")),
3 poptorch.Phase(poptorch.Stage("2"), poptorch.Stage("3")),
4 poptorch.Phase(poptorch.Stage("4"), poptorch.Stage("5")))
5
6strategy.phase(0).ipus(0, 2)
7strategy.phase(1).ipus(1, 3)
8strategy.phase(2).ipus(0, 2)
9
10opts.setExecutionStrategy(strategy)
In the code example above, there are three phases. Each phase has two stages and each IPU group has two IPUs, so the number of groups matches the number of IPUs. Even phases 0 and 2 run on IPU 0 and 2, while odd phase 1 runs on IPU 1 and 3. This allows for faster cross-IPU copies, both inter-phase and intra-phase.
poptorch.Liveness
Liveness controls the availability of tensors on IPU,
and is only needed for
ParallelPhasedExecution
and SerialPhasedExecution.
The default Liveness is AlwaysLive.
OffChipAfterFwd, OffChipAfterFwdNoOverlap and
OffChipAfterEachPhase may be helpful if you run a large model
with a tight memory budget.
4.4.3. Grouping tensor weights across replicas
PopTorch supports configuring weight tensors such that a different value of the
weight tensor is sent to each replica, or to groups of replicas. This
functionality can be used, for instance, to split a weight tensor and process
parts of it on different groups of replicas. This functionality is accessed
using the replicaGrouping() method on the weight tensor in question.
1class ModelWithLoss(torch.nn.Module):
2 def __init__(self, W_init):
3 super().__init__()
4 self.W = torch.nn.Parameter(W_init)
5
6 def forward(self, X):
7 Z = X @ self.W
8 return Z, poptorch.identity_loss(Z**2, reduction="mean")
9
10
11# Split the weight tensor into 4, and the input data tensor into 2.
12tensor_shards = 4
13data_shards = 2
14
15# Set up the problem
16random = numpy.random.RandomState(seed=100)
17prob_X = random.normal(size=(24, 40)).astype(numpy.float32)
18prob_W_init = random.normal(size=(40, 56)).astype(
19 numpy.float32) * (5 * 8)**-0.5
20prob_steps = 4
21
22X = torch.tensor(prob_X)
23
24# Run on 8 IPUs
25W_init = torch.tensor(
26 prob_W_init.reshape(prob_W_init.shape[0], tensor_shards,
27 prob_W_init.shape[1] // tensor_shards).transpose(
28 1, 0, 2)).contiguous()
29m = ModelWithLoss(W_init)
30optim = torch.optim.SGD(m.parameters(), lr=0.01)
31
32pt_opts = poptorch.Options()
33pt_opts.replicationFactor(data_shards * tensor_shards)
34pt_opts.inputReplicaGrouping(tensor_shards,
35 poptorch.enums.CommGroupType.Consecutive)
36pt_opts.outputMode(poptorch.OutputMode.All)
37pt_m = poptorch.trainingModel(m, optimizer=optim, options=pt_opts)
38pt_m.W.replicaGrouping(poptorch.enums.CommGroupType.Orthogonal, data_shards,
39 poptorch.enums.VariableRetrievalMode.OnePerGroup)
40pt_losses = []
41if data_shards > 1:
42 X = X.reshape(data_shards, X.shape[0] // data_shards, *X.shape[1:])
43for _ in range(prob_steps):
44 _, loss = pt_m(X)
45 # We divide by the number of replicas because the mean is being
46 # taken only over a part of the tensor on each replica, so we need to
47 # divide by the number of replicas to get the correct mean.
48 pt_losses.append(torch.sum(loss.detach()) / (data_shards * tensor_shards))
49pt_losses = numpy.array(pt_losses)
50pt_W_final = m.W.detach().numpy().transpose(1, 0, 2) \
51 .reshape(prob_W_init.shape)
52
In the code example above, eight replicas are used. The weight tensor W is
split four ways between orthogonal groups, each containing two replicas.
Orthogonal groups are organised perpendicularly to the replica ordering, so that
in this example replicas 0 and 4 would form the first group, 1 and 5 the
second, and so on. See CommGroupType for other replica
group organisation options (also illustrated in Fig. 4.4),
and VariableRetrievalMode for options relating to how
many replicas will be involved in value retrieval.
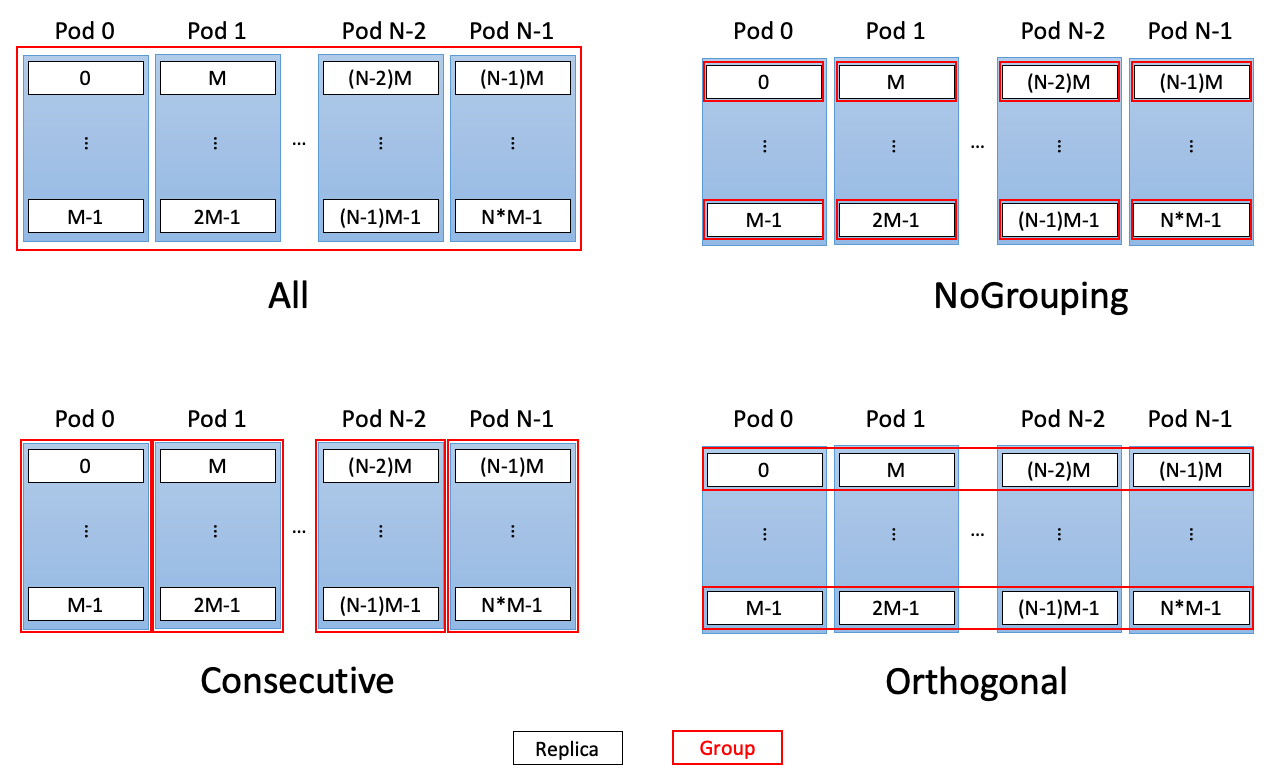
Fig. 4.4 Possible CommGroupTypes
Note that in this code example, the input tensor X is split two ways. This
is achieved using inputReplicaGrouping().
4.5. Optimizers
PopTorch supports the following optimizers:
In addition, PopTorch has features to support float16 models, such as loss scaling, velocity scaling, bias correction and accumulator types.
Important
All of these extra attributes (except velocity_scaling) must have the same values for different param_groups and therefore you must set them at the optimizer level.
1opt = poptorch.optim.SGD(model.parameters(),
2 lr=0.01,
3 loss_scaling=2.0,
4 use_combined_accum=False)
5poptorch_model = poptorch.trainingModel(model, options, opt)
6poptorch_model(input, target)
7# Update optimizer attribute
8opt.loss_scaling = 1.0
9# Update param_group attribute
10opt.param_groups[0]["loss_scaling"] = 1.0
11# Set the new optimizer in the model
12poptorch_model.setOptimizer(opt)
13poptorch_model(input, target)
Important
You must call setOptimizer() to apply the new optimizer values to the model.
Warning
PopTorch does not directly use the Python implementation of the optimizers. Built-in implementations are used in their place. This means that you cannot currently use custom optimizers. Subclassing a built-in optimizer will generate a warning. Any custom behaviour in a custom optimizer is unlikely to take effect, other than simply setting the existing attributes.
4.5.1. Loss scaling
When training models which use half or float16 values, you can use loss scaling to prevent the gradients from becoming too small and causing underflows.
Before calculating the gradients, PopTorch will scale the loss by the value of the loss_scaling parameter.
PopTorch will multiply the gradients by the inverse scale prior to updating the optimizer state.
Therefore, beyond improving numerical stability, neither the training nor the hyper-parameters are affected.
Higher loss_scaling values can improve numerical stability by minimising underflow.
However, too high a value can result in overflow.
The optimal loss scaling factor depends on the model.
You can either set the loss_scaling factors manually, or you can set setAutomaticLossScaling() in opts.Training,
which will automatically set a global loss scaling factor. If you both set loss_scaling manually and enable automatic loss scaling, the manually
set factor(s) will be used initially and updated automatically during training.
Warning
Automatic loss scaling is a preview feature. It is well tested and enabled in some of our example applications, but may not behave as expected in all models. Recommendation: if your model with automatic loss scaling enabled does not converge or triggers a compilation error, then you will need to set the loss scale manually.
4.5.2. Velocity scaling (SGD combined variant only)
The SGD optimizer, when used with momentum, updates weights based
on the velocity values.
The combined variant uses one tensor per parameter to store the
velocity and the changes to the velocity from accumulated gradients.
Unlike the separate variant, therefore, each gradient accumulation step involves
adding or subtracting values of a different magnitude to the gradients (for
which loss scaling is used). You can therefore use the velocity_scaling parameter to scale the combined velocity tensor to improve numerical precision when using half/float16 values.
(Note that the gradients are, in effect, scaled by velocity_scaling/loss_scaling so the loss_scaling has no impact on the effective scaling of velocity parameters.)
As with loss scaling, higher values can minimise underflow of the velocity values but may result in overflow.
4.5.3. Accumulation types
In order to improve numerical stability some of the optimizers (LAMB, Adam, AdamW, RMSprop) give you the option to tweak the data type used by the optimizer’s accumulators.
accum_type lets you choose the type used for gradient accumulation.
first_order_momentum_accum_type / second_order_momentum_accum_type give you control over the type used to store the first-order and second-order momentum optimizer states.
4.5.4. Constant attributes
In order to improve performance and / or save memory PopTorch will try to embed directly in the program the attributes which are constant.
Important
Trying to modify a constant attribute after the model has been compiled will result in an error.
For PopTorch optimizers (those from the poptorch.optim namespace) by default the attributes explicitly passed to the optimizer’s constructor will be considered variables and the others will be considered as constant.
You can override this behaviour using markAsConstant() and markAsVariable() before compiling the model.
1# lr, momentum and loss_scaling will be marked as variable.
2opt = poptorch.optim.SGD(model.parameters(),
3 lr=0.01,
4 momentum=0.0,
5 use_combined_accum=False)
6# momentum and loss_scaling will be marked as constant.
7opt = poptorch.optim.SGD(model.parameters(), lr=0.01, use_combined_accum=False)
8# lr and momentum will be marked as variable.
9# loss_scaling will be marked as constant.
10opt = poptorch.optim.SGD(model.parameters(),
11 lr=0.01,
12 momentum=0.0,
13 loss_scaling=2.0,
14 use_combined_accum=False)
15opt.variable_attrs.markAsConstant("loss_scaling")
16# lr, momentum and loss_scaling will be marked as variable.
17opt = poptorch.optim.SGD(model.parameters(),
18 lr=0.01,
19 loss_scaling=2.0,
20 use_combined_accum=False)
21opt.variable_attrs.markAsVariable("momentum")
For native optimizers (those from the torch.optim namespace) the attributes which are left to their default value in the constructor will be considered to be constant.
There is no method to override this behaviour which is why we recommend you always use the poptorch.optim optimizers instead.
1# momentum will be marked as constant (It's not set)
2opt = torch.optim.SGD(model.parameters(), lr=0.01)
3# lr will be marked as variable.
4# momentum will still be marked as constant (Because its default value is 0.0)
5opt = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.0)
6# lr and momentum will both be marked as variable.
7opt = torch.optim.SGD(model.parameters(), lr=0.01, momentum=1.0)
Note
There is an exception: lr is always marked as variable.
4.5.5. Reading and writing optimizer state
When you use a poptorch.optim optimizer with a trainingModel(), you can use the optimizer’s state_dict() and load_state_dict() functions to read/write optimizer state to/from the IPU.
This can be used to restart training from a checkpoint saved previously.
optimizer = poptorch.optim.Adam(model.parameters())
poptorch_model = poptorch.trainingModel(model, optimizer=optimizer)
poptorch_model(input, target)
# Saving the optimizer state
torch.save({'optimizer_state_dict': optimizer.state_dict()}, PATH)
# Destroy original model to prevent an error when wrapping the model again
poptorch_model.destroy()
new_optimizer = poptorch.optim.Adam(model.parameters())
# Loading the optimizer state back
checkpoint = torch.load(PATH)
new_optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# The new training model will use the loaded optimizer state
new_poptorch_model = poptorch.trainingModel(model, optimizer=optimizer)
Note
The structure of the state dictionary, as well as the keys within, will differ from those in PyTorch. As such, you cannot load a state dictionary with PopTorch that was obtained by running native PyTorch.
4.6. PopTorch ops
This section describes some “helper” operations you can use within a model.
4.6.1. poptorch.ctc_beam_search_decoder
This function adds a Connectionist Temporal Classification (CTC) beam search decoder operator to the model.
1class Model(torch.nn.Module):
2 def forward(self, log_probs, lengths):
3 return poptorch.ctc_beam_search_decoder(log_probs, lengths)
4
5
For more information see: ctc_beam_search_decoder().
4.6.2. poptorch.ipu_print_tensor
This function adds an op to print the content of a tensor on the IPU.
Note
To prevent the print operation being optimised out by the graph
optimiser, you must use the return value of ipu_print_tensor().
1class ExampleModel(torch.nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.bias = torch.nn.Parameter(torch.zeros(()))
5
6 def forward(self, x):
7 x = x + 1
8
9 # It is important to make sure the result of the print is used.
10 x = poptorch.ipu_print_tensor(x)
11
12 return x + self.bias
13
14
For more information see: ipu_print_tensor().
4.6.3. poptorch.identity_loss
You can use this function to implement custom losses. It takes a single PyTorch tensor and will backpropagate a gradient of ones through it.
1def custom_loss(output, target):
2 # Mean squared error with a scale
3 loss = output - target
4 loss = loss * loss * 5
5 return poptorch.identity_loss(loss, reduction="mean")
6
7
8class ExampleModelWithCustomLoss(torch.nn.Module):
9 def __init__(self):
10 super().__init__()
11 self.model = ExampleModel()
12
13 def forward(self, input, target):
14 out = self.model(input)
15 return out, custom_loss(out, target)
16
17
For more information see: identity_loss().
4.6.4. poptorch.MultiConv
Use the MultiConv wrapper class to define multi-convolutions.
Refer to the PopLibs documentation for multi-convolutions for further information.
For more information see: MultiConv and MultiConvPlanType.
4.6.5. poptorch.nop
PopTorch includes a “no-op” function for debugging purposes.
For more information see: nop().
4.6.6. poptorch.dynamic_slice
Standard PyTorch slicing syntax cannot currently be used to create dynamic slices. This function supports dynamic slicing on the IPU.
For more information see: dynamic_slice().
4.6.7. poptorch.dynamic_update
Standard PyTorch slicing syntax cannot currently be used to dynamically update a slice
of a tensor. poptorch.dynamic_update allows updating a tensor with a statically sized
slice at a dynamic index.
This function supports dynamic updates on the IPU.
For more information see: dynamic_update().
4.6.8. poptorch.serializedMatMul
Use this function to create a serialized matrix multiplication, which splits a larger matrix multiplication into smaller matrix multiplications to reduce memory requirements.
For more information see: serializedMatMul().
4.6.9. poptorch.set_available_memory
Use this function to override the default proportion of tile memory available as temporary memory for use by operations such as a convolution or matrix multiplication. The operators that can be tuned with this setting include:
convolution
matrix multiplication
embedding lookup
indexing operations
For more information see:
technical note on optimising temporary memory usage
4.6.10. Miscellaneous functions
The following PopTorch functions, not related to model creation, are available:
4.7. 16-bit float support
PopTorch supports the half-precision floating point (float16) format.
You can simply input float16 tensors into your model.
(You can convert a tensor to float16 using tensor = tensor.half())
You can use your models in one of the following ways:
Convert all parameters (weights) to
float16by using aModule’s.half()method. This is the most memory efficient, however small updates to weights may be lost, hindering training.Keep the parameters (weights) as
float32, in which case the parameter updates will occur usingfloat32. However, the parameters will be converted tofloat16if you call an operation with afloat16input. This is more memory efficient than usingfloat32tensors (inputs) but less memory efficient than usingfloat16weights.Use a mix of
float32andfloat16parameters by manually specifying parameters asfloat16orfloat32.
Note
When PyTorch encounters a mix of float16 and float32 inputs for a given operation, it will usually cast all inputs to float32,
and PopTorch complies with this convention.
1model = torch.nn.Linear(1, 10)
2
3# Cast the parameters (weights) to half.
4model.half()
5
6t1 = torch.tensor([1.]).half()
7
8opts = poptorch.Options()
9
10inference_model = poptorch.inferenceModel(model, opts)
11out = inference_model(t1)
12
13assert out.dtype == torch.half
4.8. PyTorch buffers
PopTorch supports PyTorch buffers in some circumstances.
You can use buffers to make tensors persistent,
that is to allow tensors to keep their values from the previous run on each new run,
without making them model parameters.
However, you must make sure that you only make in-place modifications to the
buffer using PyTorch in-place operations (such as += or those ending in _).
For example, you can torch.Tensor.copy_ to copy the contents of another
tensor to the buffer.
Unlike when running on the CPU, the following PyTorch code does not increment
model.i each time, when running on the IPU:
1class CounterModel(torch.nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.i = torch.tensor([0.], dtype=torch.float)
5
6 def forward(self):
7 self.i += 1
8 return self.i
9
10
11model = CounterModel()
12poptorch_model = poptorch.inferenceModel(model)
13print(poptorch_model()) # tensor([1.])
14print(poptorch_model()) # tensor([1.])
This is because the PyTorch dispatcher will capture the value for model.i when
building the graph and freeze the value as a constant.
You can keep the value of a tensor between runs by registering it as a buffer in PyTorch, as the following examples shows:
1class CounterModel(torch.nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.register_buffer("i", torch.tensor([0.], dtype=torch.float))
5
6 def forward(self):
7 self.i += 1
8 return self.i
9
10
11model = CounterModel()
12poptorch_model = poptorch.inferenceModel(model)
13
14print(poptorch_model()) # tensor([1.])
15print(poptorch_model()) # tensor([2.])
Note
When running an inference model
(with inferenceModel()), any buffers which your model
modifies will not be implicitly copied to the host. You will need to call
copyWeightsToHost() before reading the value
of a buffer which has been changed as a result of a model call.
Note
PopTorch does not support broadcasting of buffers between replicas.
You can make each replica use its own buffer by setting the PopTorch option
broadcastBuffers() to False:
poptorch.Options().broadcastBuffers(False)
You need to ensure that your model still works with each replica using a separate buffer.
4.9. Creating custom ops
If you need to implement functionality that is not directly supported in in PopTorch, you can create a custom op.
There are two steps to creating a custom op in PopTorch:
Implement the op in C++ using the PopART API
Make the op available in PopTorch so you can use it in your PyTorch model
4.9.1. Implementing the custom op
You will need to implement the new op as C++ code by creating subclasses of, at least, the Op and Opx base classes provided by the PopART API.
If you are going to use the custom op for training, then you will also need to define the classes that implement the gradient operation. For details of how to do this, see the Custom operators chapter of the PopART User Guide.
You can find some examples of custom ops in the Graphcore GitHub examples repository.
Compiling the PopART custom op will create a dynamic library file, which you can use with your PyTorch code.
4.9.2. Make the op available to PyTorch
After you have compiled the C++ implementation of the custom op, you can load
the library file, and call the op from your PyTorch program, using the
custom_op class.
First, load the dynamic library as shown in Listing 4.23.
1myso = list(pathlib.Path("tests").rglob("libcustom_cube_op.*"))
2assert myso, "Failed to find libcustom_cube_op"
3myop = ctypes.cdll.LoadLibrary(myso[0])
4
You can now call your custom op using the PopTorch class
custom_op.
Both the forward op and backward op are implemented in the PopART code. However, in this inference model example, only the forward op is called:
1def test_inference():
2 class BasicNetwork(nn.Module):
3 def forward(self, x, bias):
4 x, y = poptorch.custom_op([x, bias],
5 "Cube",
6 "com.acme",
7 1,
8 example_outputs=[x, x])
9 return x, y
10
In this example [x, x] is assigned to example_outputs, where x
is one of the input tensors which is used as a template for the output tensors.
The custom op code will need to create the tensors that it returns.
You can also call this custom op inside a training model using
custom_op and the backward op will be called automatically.
The Graphcore examples repository contains a feature example demonstrating how to load and in and use a custom op in a PopTorch model: PopTorch example: Custom op.
4.9.3. Passing attributes to the custom op
You can pass attributes to the custom op using a Python dictionary, as shown in Listing 4.25.
1 class Model(torch.nn.Module):
2 def forward(self, x):
3 x = poptorch.custom_op([x],
4 "LeakyRelu",
5 "com.acme",
6 1,
7 example_outputs=[x],
8 attributes={"alpha": 0.02})
9 return x[0]
10
You can then access these attributes within the C++ custom op code. The above
example passes a Float attribute with the name alpha to the LeakyRELU
implementation. See the Custom operators
chapter of the PopART User Guide for more information.
Table Table 4.1 and the code example in
Listing 4.26 show how to pass other attribute types
to a custom op. PopTorch supports all attributes supported in PopART except for
Graph.
PopART attribute type |
Python equivalent |
|---|---|
|
Python float (converted to |
|
List or tuple of Python float |
|
Python int (converted to 64-bit signed int) |
|
List or tuple of Python int |
|
Python str (converted to ASCII) |
|
List or tuple of Python str |
|
Not supported |
1def test_many_attributes_examples():
2 class Model(torch.nn.Module):
3 def forward(self, x):
4 attributes = {
5 "float_one": 1.0,
6 "float_minus_two": -2.0,
7 "int_zero": 0,
8 "int_minus_five": -5,
9 "floats_one_two_three": [1.0, 2.0, 3.0],
10 "floats_minus_one_two_three": [-1.0, -2.0, -3.0],
11 "ints_one_two_three": [1, 2, 3],
12 "ints_minus_one_two_three": [-1, -2, -3],
13 "a_string": "string with quotes and slash \" ' \\ end",
14 "strs": ["abc", "def", "ghi"]
15 }
16
17 x = poptorch.custom_op([x],
18 "ManyAttributeOp",
19 "test.poptorch",
20 1,
21 example_outputs=[x],
22 attributes=attributes)
4.10. Precompilation and caching
4.10.1. Caching
By default PopTorch will re-compile the model every time you instantiate a model. However if you often run the same models you might want to enable executable caching to save time.
You can do this by either setting the POPTORCH_CACHE_DIR environment variable or by calling enableExecutableCaching.
Warning
The cache directory might grow large quickly because PopTorch doesn’t delete old models from the cache and, depending on the number and size of your models and the number of IPUs used, the executables might be quite large. It is your responsibility to delete the unwanted cache files.
4.10.2. Precompilation
PopTorch supports precompilation: This means you can compile your model on a machine which doesn’t have an IPU and export the executable to a file. You can then reload and execute it on a different machine which does have an IPU.
Important
The PopTorch versions on both machines must be an exact match.
To precompile your model you need to wrap it using either trainingModel() or inferenceModel() then call compileAndExport() on the wrapper.
1import torch
2import poptorch
3
4
5class ExampleModelWithLoss(torch.nn.Module):
6 def __init__(self):
7 super().__init__()
8 self.fc = torch.nn.Linear(10, 10)
9 self.loss = torch.nn.MSELoss()
10
11 def forward(self, x, target=None):
12 fc = self.fc(x)
13 if self.training:
14 return fc, self.loss(fc, target)
15 return fc
16
17
18torch.manual_seed(0)
19model = ExampleModelWithLoss()
20
21opts = poptorch.Options()
22# You don't need a real IPU to compile the executable.
23opts.useOfflineIpuTarget(ipu_target_version)
24
25# Wrap the model in our PopTorch annotation wrapper.
26poptorch_model = poptorch.trainingModel(model, opts)
27
28# Some dummy inputs.
29input = torch.randn(10)
30target = torch.randn(10)
31
32poptorch_model.compileAndExport(filename, input, target)
Note
If you don’t know the IPU version on your system you can use ipuHardwareVersion().
The exported file by default will contain your original PyTorch model (including the weights), and enough information to re-create the PopTorch wrapper and reload the executable.
Important
For your model and weights to be exported, your model must be picklable. See https://docs.python.org/3/library/pickle.html for more information.
If your model is not picklable then use export_model=False, as shown in Listing 4.30.
Now both the torch model, PopTorch wrapper and executable can be restored on the target machine using load():
1poptorch_model = poptorch.load(filename)
2
3# That's all: your model is ready to be used.
4poptorch_model(input, target) # Run on IPU
In some cases you might want to provide some runtime information to select the device: you can do this
using the edit_opts_fn argument of load():
1def setIpuDevice(opts):
2 opts.useIpuId(1) # always use IPU 1
3
4
5poptorch_model = poptorch.load(filename, edit_opts_fn=setIpuDevice)
6poptorch_model(input, target) # Run on IPU 1
Note
When loading a precompiled model, only run-time options will be applied; all others will be ignored.
Going back to the precompilation step: in some cases you might want to export only the executable and not the python wrapper or torch model (for example if your model cannot be pickled).
1poptorch_model.compileAndExport(filename, input, target, export_model=False)
It means you will need to re-create and wrap the model yourself before loading the executable:
1model = ExampleModelWithLoss()
2
3opts = poptorch.Options()
4
5# Wrap the model in our PopTorch annotation wrapper.
6poptorch_model = poptorch.trainingModel(model, opts)
7poptorch_model.loadExecutable(filename)
8
9# Some dummy inputs.
10input = torch.randn(10)
11target = torch.randn(10)
12
13poptorch_model(input, target) # Run on IPU
Important
Exported models lose their connections to other models.
For example, if you have a trainingModel() and a inferenceModel() based
on the same PyTorch model, you wouldn’t usually need to keep the weights synchronised between the two;
PopTorch would take care of it for you, implicitly.
In the following example, PopTorch automatically copies the weights from the training model to the inference model:
1model = ExampleModelWithLoss()
2
3opts = poptorch.Options()
4
5# Wrap the model in our PopTorch annotation wrapper.
6training_model = poptorch.trainingModel(model, opts)
7model.eval()
8validation_model = poptorch.inferenceModel(model, opts)
9
10# Some dummy inputs.
11input = torch.randn(10)
12target = torch.randn(10)
13
14# Train the model:
15for epoch in epochs:
16 training_model(input, target)
17
18# Weights are implicitly copied from the training model
19# to the validation model
20prediction = validation_model(input)
If you were to export these models:
1model = ExampleModelWithLoss()
2
3opts = poptorch.Options()
4
5# Some dummy inputs.
6input = torch.randn(10)
7target = torch.randn(10)
8
9# Wrap the model in our PopTorch annotation wrapper.
10training_model = poptorch.trainingModel(model, opts)
11training_model.compileAndExport("training.poptorch", input, target)
12model.eval()
13validation_model = poptorch.inferenceModel(model, opts)
14validation_model.compileAndExport("validation.poptorch", input)
Note
Don’t forget to call model.eval() or model.train(), as required, before calling compileAndExport().
You could then insert explicit copy operations:
1training_model = poptorch.load("training.poptorch")
2validation_model = poptorch.load("validation.poptorch")
3
4for epoch in epochs:
5 print("Epoch ", epoch)
6 run_training(training_model)
7 # Need to explicitly copy weights between the two models
8 # because they're not connected anymore.
9 training_model.copyWeightsToHost()
10 validation_model.copyWeightsToDevice()
11 run_validation(validation_model)
Or you would need to re-connect the two models by creating the second one from the first one and then loading the executable:
1training_model = poptorch.load("training.poptorch")
2# Create a validation python model based on the training model
3validation_model = poptorch.inferenceModel(training_model)
4validation_model.model.eval()
5# Load the executable for that model:
6validation_model.loadExecutable("validation.poptorch")
7
8for epoch in epochs:
9 print("Epoch ", epoch)
10 run_training(training_model)
11 # Nothing to do: training_model and validation_model are now connected
12 # and PopTorch will implicitly keep the weights in sync between them.
13 run_validation(validation_model)
4.11. Environment variables
4.11.1. Logging level
PopTorch uses the following levels of logging:
OFF: No logging
ERR: Errors only
WARN: Warnings and errors only
INFO: Info, warnings and errors (default)
DEBUG: Adds some extra debugging information
TRACEandTRACE_ALL: Trace everything inside PopTorch
You can use the POPTORCH_LOG_LEVEL environment variable to set the logging level:
export POPTORCH_LOG_LEVEL=DEBUG
4.11.2. Profiling
When running programs using PopTorch, you can enable profiling by using the POPLAR_ENGINE_OPTIONS environment variable used by Poplar.
In order to capture the reports needed for the PopVision Graph Analyser you only need to set POPLAR_ENGINE_OPTIONS='{"autoReport.all":"true"}':
export POPLAR_ENGINE_OPTIONS='{"autoReport.all":"true"}'
By default, report files are output to the current working directory. You can specify a different output directory by setting autoReport.directory, for example:
export POPLAR_ENGINE_OPTIONS='{"autoReport.all":"true", "autoReport.directory":"./tommyFlowers"}'
For more options, refer to the PopVision Graph Analyser User Guide.
In order to capture the pvti reports needed for the PopVision System Analyser
you need to enable the PopVision Trace Instrumentation library (PVTI).
To do so, set PVTI_OPTIONS='{"enable":"true"}'.
Important
By default, PopVision will display multiple trace files using relative time. This is because most of the time we want to compare two executions of the same model, for example. However, in this case we want the traces to be aligned on absolute time: this can be done by selecting “Absolute Timing” in the PopVision options.
You can also add extra tracepoints in your own code by using Channel.
4.11.3. IPU Model
By default PopTorch will try to attach to a physical IPU.
If instead you want to use the model, you can do so by setting POPTORCH_IPU_MODEL to 1:
export POPTORCH_IPU_MODEL=1
See the Poplar and PopLibs User Guide for the limitations of the IPU Model.
4.11.4. Wait for an IPU to become available
By default, attempting to attach to an IPU when all IPUs are
already in use will raise an exception.
If you would rather wait for an IPU to become available, you can do so by setting POPTORCH_WAIT_FOR_IPU to 1.
export POPTORCH_WAIT_FOR_IPU=1
4.11.5. Enable executable caching
You can enable executable caching by either setting the POPTORCH_CACHE_DIR environment variable or by calling enableExecutableCaching.
export POPTORCH_CACHE_DIR=/tmp/poptorch_cache
For more information, see Section 4.10.1, Caching.