1. Introduction
The Poplar® SDK is the world’s first complete tool chain specifically designed for creating graph software for machine intelligence applications. Poplar seamlessly integrates with TensorFlow, PyTorch and Open Neural Network Exchange (ONNX) allowing developers to use their existing machine intelligence development tools and existing machine learning models.
Poplar enables you to exploit features of the Graphcore Intelligence Processing Unit (IPU), such as parallel execution and efficient floating-point operations. Models written in industry-standard machine learning (ML) frameworks such as TensorFlow and PyTorch are compiled by Poplar to run in parallel on one or more IPUs.
You can import models from other ML frameworks using the Poplar advanced runtime (PopART™), and run them on the IPU. You can also use the Poplar graph library from C++ to create graph programs to run on IPU hardware.
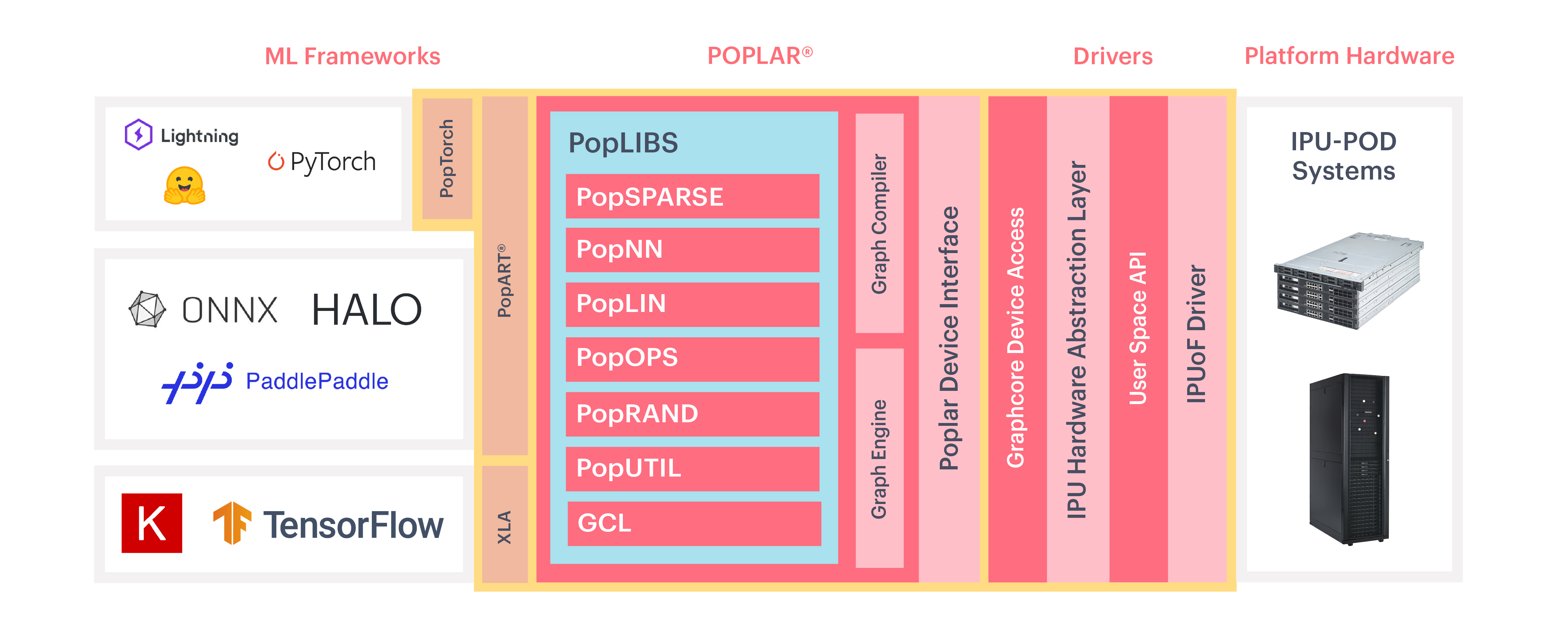
Fig. 1.1 The Poplar SDK software stack
For more information about the IPU and its programming models, refer to the IPU Programmer’s Guide.
2. PyTorch
The Poplar software stack provides support for running PyTorch training and inference models on the IPU. This requires minimal changes to your existing PyTorch code.
You can create a wrapper for your existing PyTorch model with a single function call. This will create a PopTorch model that runs in parallel on a single IPU.
You can then choose how to split the model across multiple IPUs, to create a pipelined implementation that exploits data parallelism across the IPUs.
See the PyTorch for the IPU: User Guide and PyTorch Quick Start for more information.
Note
PyTorch is not supported on CentOS 7.6 (since Poplar SDK 3.1).
3. TensorFlow
The Poplar SDK includes an implementation of TensorFlow 2.6 for the IPU which includes IPU-specific functionality.
Note
There are TensorFlow wheel files built and optimised for both AMD and Intel processors. You must install the appropriate version for your system.
The SDK also includes an implementation of Keras 2.6 for the IPU as well as a collection of add-ons created for TensorFlow for the IPU. These include IPU-specific TensorFlow layers and IPU-specific Keras layers and optimizers.
Note
TensorFlow 2, IPU TensorFlow Addons for TensorFlow 2 and Keras for the IPU are not included for CentOS 7.6 (since SDK 3.1).
For more information, refer to and Targeting the IPU from TensorFlow 2 and TensorFlow 2 Quick Start.
Note
An implementation of TensorFlow 1.15 for the IPU is also available but only for CentOS 7.6 (since Poplar SDK 3.1). There is also a collection of add-ons created for TensorFlow 1.15 for the IPU, containing IPU-specific TensorFlow layers. Refer to the Targeting the IPU from TensorFlow 1 and TensorFlow 1 Quick Start for more information.
4. PopART and ONNX
The Poplar advanced run-time (PopART) enables the efficient execution of both inference and training graphs on the IPU. Its main import format is Open Neural Network Exchange, an open format for representing machine learning models.
You can import and execute models created using other industry-standard frameworks, including using differentiation and optimization to train their parameters. You can also create graphs in PopART directly. Models can be exported in ONNX format, for example after training.
PopART includes Python and C++ APIs.
See the PopART User Guide and PopART Quick Start for more information.
5. The Poplar libraries
The Poplar libraries are a set of C++ libraries consisting of the Poplar graph library and the open-source PopLibs™ libraries.
The Poplar graph library provides direct access to the IPU by code written in C++. You can write complete programs using Poplar, or use it to write functions to be called from your application written in a higher-level framework such as TensorFlow.
Poplar enables you to construct graphs, define tensor data and control how the code and data are mapped onto the IPU for execution. The host code and IPU code are both contained in a single program. Poplar compiles code for the IPU and copies it to the device to be executed. You can also pre-compile the device code for faster startup.
The open-source PopLibs library provides a range of higher level functions commonly used in machine learning applications. This includes highly optimised and parallelised primitives for linear algebra such as matrix multiplications and convolutions. There are also several functions used in neural networks (for example, non-linearities, pooling and loss functions) and many other operations on tensor data.
The source code for PopLibs is provided so you can use the library as a starting point for implementing your own functions.
For more information, refer to the Poplar and PopLibs User Guide and the Poplar Quick Start.
Each vertex of a Poplar graph runs a “codelet” that executes code directly on one of the many parallel cores in the IPU. These codelets can be written in C++ or, when more performance is required, assembly.
6. Running programs on the IPU
6.1. Distributed applications
The PopRun tool is provided with the SDK to assist with the task of running an application across multiple IPUs. It is a command line utility to launch distributed applications on Pod systems. It creates multiple instances of the application. Each instance can either be launched on a single host server or multiple host servers within the same Pod, depending on the number of host servers available on the target Pod.
PopRun is implemented with the PopDist API. This provides functions you can use to write a distributed application.
For more information, see the PopDist and PopRun: User Guide.
6.2. Model Runtime and PopEF
Model Runtime is a library to easily load and run models stored in the Poplar Exchange Format (PopEF) on the IPU. Model Runtime consists of various tools for deploying models, covering a wide range of inference applications. The Model Runtime library contains both a C++ API and a Python API. For more information, see Model Runtime: User Guide.
PopEF is a Graphcore file format that is mainly used for exporting and importing models. PopEF is supported by the popef library that is a part of the Poplar SDK. The library contains both a C++ API and a Python API. For more information, see PopEF: User Guide.
6.3. Triton Inference Server
The Poplar SDK includes a backend for the Triton Inference Server to support IPU systems. This enables inference models, written using PopTorch, PopART or TensorFlow for the IPU, and trained on the IPU, to be served for execution on IPU systems.
For more information see the Poplar Triton Backend: User Guide.
6.4. TensorFlow Serving
The Poplar SDK includes the TensorFlow Serving 1 and TensorFlow Serving 2 applications for serving inference models. The applications support models exported from TensorFlow 1 and TensorFlow 2 into the IPU-optimized SavedModel format using the TensorFlow 1 export API and TensorFlow 2 export API respectively.
For more information, refer to IPU TensorFlow Serving 1 User Guide and IPU TensorFlow Serving 2 User Guide.
Note
From Poplar SDK 3.1:
TensorFlow Serving 1 is only available on CentOS 7.6.
TensorFlow Serving 2 is no longer available on CentOS 7.6.
7. PopVision™ analysis tools
The PopVision analysis tools enable you to get an understanding of how applications are performing and utilising the IPU.
For more information see the PopVision PopVision Graph Analyser User Guide and PopVision System Analyser User Guide.
7.1. PopVision Graph Analyser
The PopVision Graph Analyser is an analysis tool that helps you gain a deep understanding of how your application is performing and utilising the IPU. By integrating directly with the internal profiling support of the Poplar graph engine and compiler, it enables you to profile and optimise the performance and memory usage of your machine learning models, whether developed in TensorFlow, PyTorch or natively using Poplar and PopLibs.
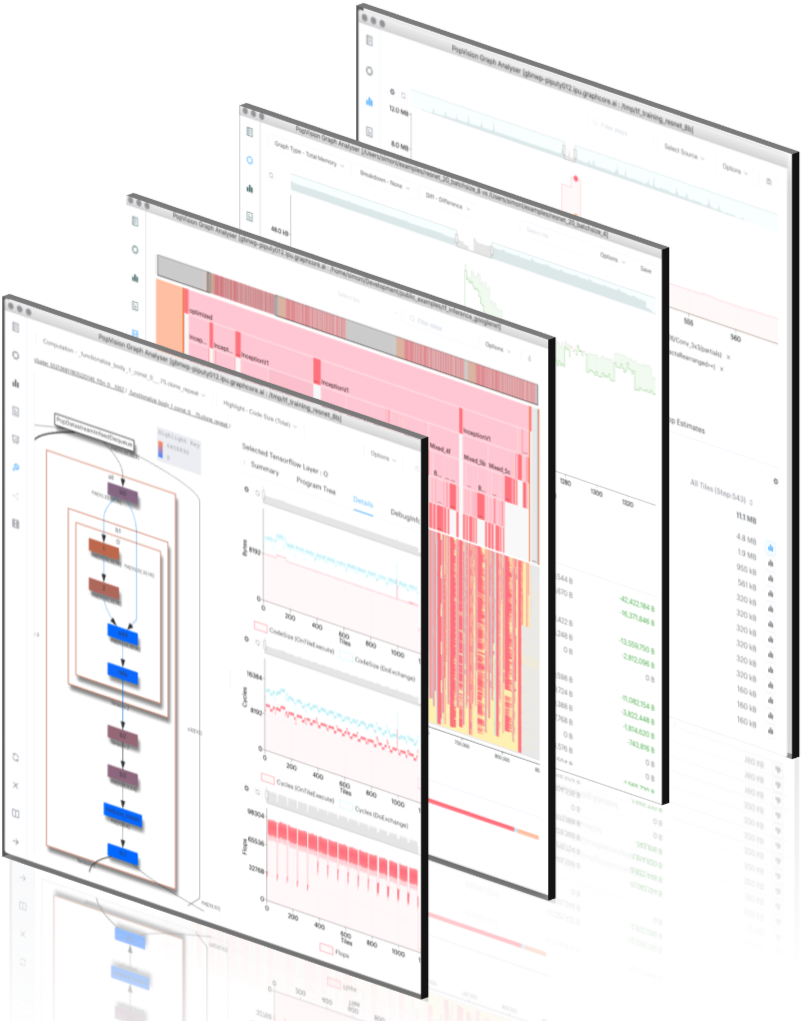
Fig. 7.1 The PopVision Graph Analyser
The program provides a graphical display of information about your program, including:
Summary report: Essential program information.
Memory report: Analyse program memory consumption and layout on one or multiple IPUs.
Liveness report: Explore temporary peaks in memory and their impact.
Execution trace report: View program execution.
For more information see the the PopVision Graph Analyser blog post
7.2. PopVision System Analyser
The PopVision System Analyser allows you to identify bottlenecks on the host CPU by showing the profiling information collected by the PopVision Trace Instrumentation library for Poplar, frameworks and the user application.
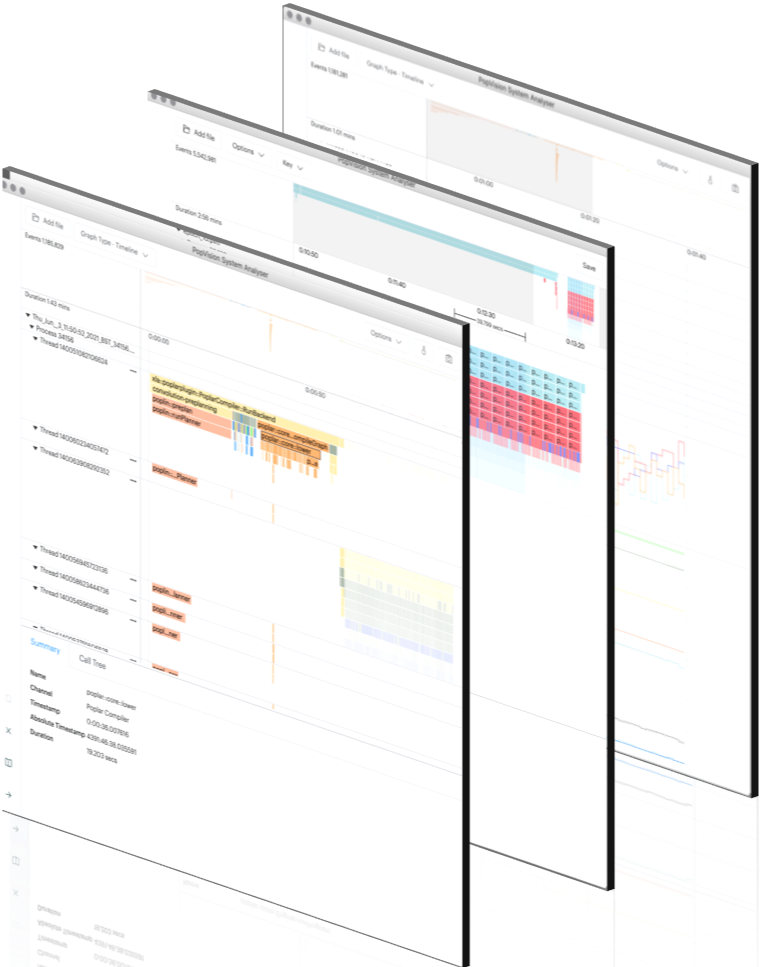
Fig. 7.2 The PopVision System Analyser
It provides information about the behaviour of the host-side application code. It shows an interactive graphical view of the timeline of execution steps, helping you to identify any bottlenecks between the CPUs and IPUs.
For more information see the the PopVision Analysis Tools blog post
7.3. The PopVision libraries
The PopVision analysis library (libpva) allows programmatic analysis of the IPU profiling information used by the Graph Analyser. The library provides both C++ and Python APIs that can be used to query the Poplar profiling information for you application.
The PopVision trace instrumentation library (libpvti) provides functions to manage the capturing of profiling information for the host-code of your IPU application. This data can then be explored with the PopVision System Analyser. The library provides C++ and Python APIs.
8. Contents of the SDK
The Poplar SDK can be downloaded from the Graphcore software download portal. See the Getting Started guides for your system for full installation instructions.
The PopVision analysis tools can be downloaded from the PopVision tools web page. Full documentation is available on the Graphcore documentation portal. Further information and resources can be found on the Graphcore developer site.
Full details of what is contained in the SDK for each operating system is given in the release notes.
Note
On some cloud-based systems, each user sees a virtual machine and so you may need to install all the necessary software. See the Getting Started guides for your system for more information about what software is installed.
8.1. Requirements
To use the Poplar software you will need suitable hardware, such as a Bow Pod, or access to a cloud-based service that supports IPUs.
Supported operating systems:
Ubuntu 20.04
RHEL 8.6
Debian 10.7
CentOS 7.6
Refer to the SDK release notes for details on the versions of Python that are supported in each operating system. Other packages required by TensorFlow or PopTorch will be automatically installed when you install the wheel file. We recommend running TensorFlow and PopTorch in a Python virtual environment.
The Intel build of TensorFlow requires a processor that supports the AVX-512 instruction set extensions (Skylake, or later).
The AMD build of TensorFlow requires a Ryzen class processor.
The SDK also includes a software model of the IPU so it is possible to develop and test your code even when IPU hardware is not available. This has limited functionality but can be useful for unit testing, for example.
9. Docker containers
You can pull pre-configured Docker containers from Docker Hub. These provide Poplar SDK images ready for deployment.
A full list of images is given in the Using Docker images section in the document Using IPUs from Docker.
10. Support
Support is available from the Graphcore support portal. You can also join the Graphcore Slack Community.
Graphcore has GitHub repositories with further examples, including:
-
TensorFlow, PyTorch and PopART versions of commonly used machine learning models for training and inference
Tutorials
Examples of using Poplar and IPU features
Examples of simple models
Source code from videos, blogs and other documents
For more information, see the Examples and Tutorials page.
When looking for answers or asking questions on StackOverflow, use the tag “ipu”.
For general help, discussions and announcements, please join our Graphcore Slack Community.