1. Using IPUs for machine learning
If you have previously been using GPUs for your machine learning (ML) models then there are a few programming changes that you need to be aware of when starting to use IPUs. In this technical note we provide a high-level overview of these differences and give references to where you can find more details.
You can find a good introduction to the IPU programming model in the IPU Programmer’s Guide.
This document answers the following questions:
What is the Poplar SDK?
What is different for training?
What is different for fine-tuning?
What is different for performance profiling?
What is different for inference?
What if I want to use a larger system?
Can I use HuggingFace models?
Are there Jupyter notebooks for IPUs I can try?
What can I do if I get out of memory errors?
Can I use CUDA code with IPUs?
Where can I find some example code?
2. Poplar SDK
The Poplar® SDK is a complete tool chain for creating graph software in machine learning. Poplar integrates with industry-standard frameworks including TensorFlow, PyTorch, PyTorch Geometric, PyTorch Lightning and Open Neural Network Exchange (ONNX), enabling you to run your machine learning models on IPUs. Models are compiled by Poplar to run in parallel on one or more IPUs.
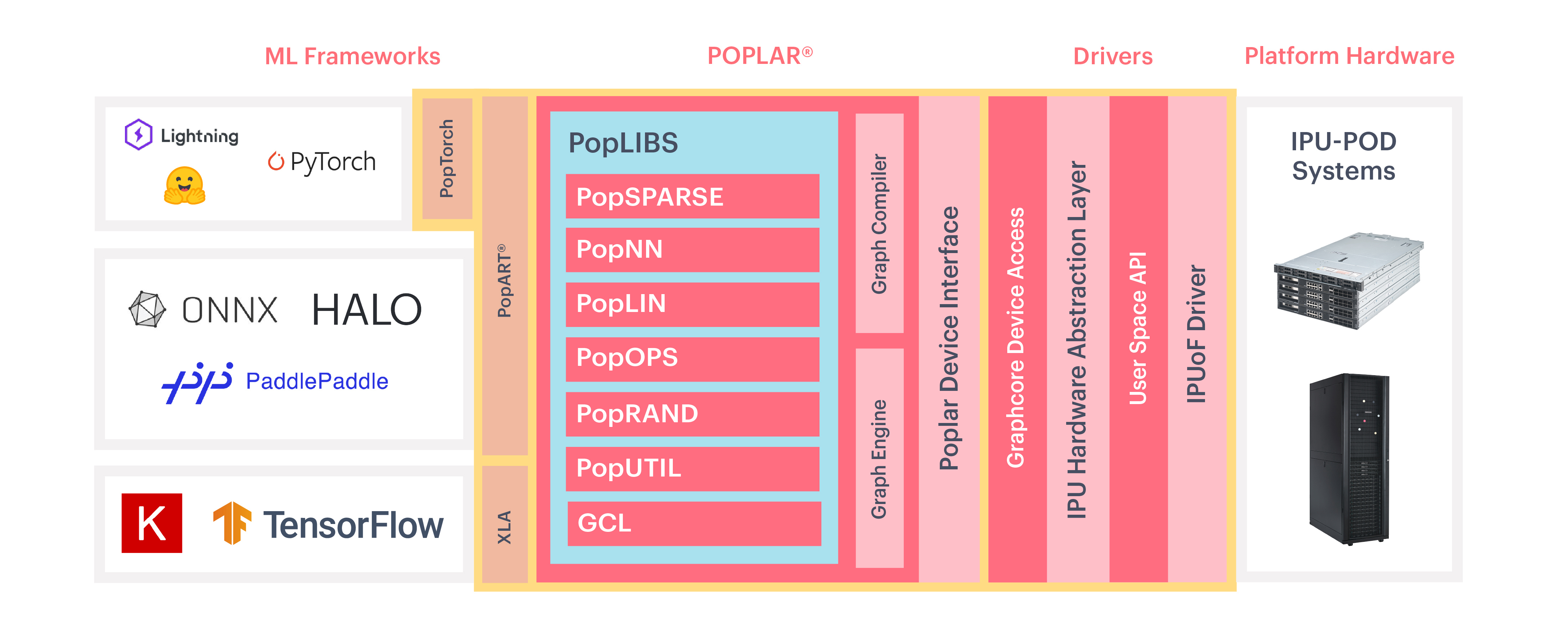
3. Training on IPUs
There are a few changes that you will need to make to your model when starting to use IPUs instead of GPUs for training. What you will need to change depends on the framework that you originally used for your model.
3.1. PyTorch models
If you want to use IPUs for training your PyTorch model, you will need to use PyTorch for the IPU.
PyTorch for the IPU (also known as PopTorch) is a set of extensions for PyTorch to enable PyTorch models to run directly on the IPU. PopTorch compiles PyTorch models into Poplar executables and also provides IPU-specific functions.
You only need to make a minor change to your PyTorch model in order to be able to use it on the IPU for training. You need to add a training wrapper. This function accepts a PyTorch model (torch.nn.Module) and creates a version of the model that can be executed on the IPU.
We have some examples of using PyTorch for the IPU for training, including a simple example with small data, how to achieve efficient data loading and pipelining, which is useful if your model too big to fit in the memory of one IPU.
3.2. PyTorch Geometric models
PyTorch Geometric (PyG) is a Python library built on the PyTorch framework for training Graph Neural Networks (GNNs) and is fully supported on the IPU. In order to run PyG models on the IPU you will need to make a few changes to your model as described in detail in PyTorch Geometric for the IPU.
There are some useful PyTorch Geometric tutorials , as well as a blog about how to get started using PyG with IPUs.
3.3. TensorFlow and Keras models
TensorFlow is a powerful graph-modelling framework that can be used for both training and inference with machine learning models. Keras is a high level API of the TensorFlow platform.
TensorFlow graphs are compiled into Poplar executables in the IPU implementation of TensorFlow. You need to make a few changes to your TensorFlow code to target the IPU efficiently. These include IPU-specific API configurations, model parallelism, error logging and report generation, as well as strategies for dealing with out-of-memory (OOM) issues.
For further information you can see our user guides for the IPU implementation of TensorFlow 2 and IPU implementation of TensorFlow 1.
In TensorFlow 2, Keras is the main API for constructing models, acting as an interface for the TensorFlow library. Keras can be used to train, evaluate or run machine learning models.
The Graphcore implementation of Keras provides support for training Keras models on the IPU. For an example of how to use it for training there is a tutorial available which uses a Keras model with the MNIST training and testing datasets.
3.4. ONNX models
Poplar Advanced Runtime (PopART) enables you to import or build models using the Open Neural Network Exchange (ONNX) and run the model using Poplar tools. PopART is part of the Poplar SDK.
You will need to make some code changes to your ONNX model in order for it to run in training mode on the IPU. You can find more details about the changes required in Executing graphs.
4. Fine-tuning on IPUs
If you want to use IPUs for fine-tuning a model then you have all the same options available to you as you would have for the initial training of a model — see Section 3, Training on IPUs.
There is a discussion about pre-training and fine-tuning a BERT-Large model in the Pre-Training and Fine-Tuning BERT for the IPU technical note which covers using both TensorFlow and PyTorch, as well as some key optimisation techniques for model development on the IPU.
The tutorial BERT Fine-tuning on the IPU demonstrates how to fine-tune a pre-trained BERT model with PyTorch on the IPU.
There are various strategies that you can use to optimise your machine learning model. For more information see the IPU optimisation technical notes.
5. Performance profiling on IPUs
For all models, the PopVision™ graph analyser is a useful tool for visualising what is happening on the IPUs when you run your model. The Graph Analyser shows performance, how the code is using individual IPUs, data about the graph program, memory use, and the time spent executing code and communicating. You may have used a similar tool such as NVIDIA’s Visual Profiler.
There are also some useful PopVision tutorials.
The information in the profiling chapter of the Poplar and PopLibs user guide can be helpful for understanding how to use the information from PopVision and also describes how to retrieve profiling information directly from Poplar. You can also retrieve profiling reports from PopART.
For TensorFlow models, you can still use the TensorBoard visualisation tool with IPUs. We have a tutorial about using TensorBoard with the IPU implementation of TensorFlow 2 which you might find useful.
6. Inference on IPUs
If you already have a pre-trained model and want to use it for inference on the IPU then there are several different tools available.
6.1. PyTorch models
If you want to use IPUs for inference with your PyTorch model, you will need to use PyTorch for the IPU.
PyTorch for the IPU (also known as PopTorch) is a set of extensions for PyTorch to enable PyTorch models to run directly on the IPU.
You only need to make a minor change to your PyTorch model in order to be able to use it on the IPU for inference. You need to add an inference wrapper. This function accepts a PyTorch model (torch.nn.Module) and creates a PopTorch inference model that can be executed on the IPU in inference mode.
For an example of running a PyTorch model in inference mode, there is a Dolly 2.0 LLM model available in the list of notebooks to run on the IPU.
You can also use Model Runtime for PyTorch models. Model Runtime is a Graphcore library that is included in the Poplar SDK.
6.2. PyTorch Geometric models
If you want to run a PyTorch Geometric (PyG) model for inference there are a few changes that you need to make to your model as described in detail in PyTorch Geometric for the IPU.
There are some useful PyTorch Geometric tutorials , as well as a blog about how to accelerate your performance using PyG models with IPUs.
You can also use Model Runtime for PyTorch Geometric models. Model Runtime is a Graphcore library that is included in the Poplar SDK.
6.3. Triton Inference Server
If you want to use IPUs to run your pre-trained model on the Triton Inference Server you will need to use the Poplar Triton Backend. The user guide contains instructions on how to use the Poplar Triton backend to get your model running on the inference server, for example how to configure the model repository and the Poplar backend as well as instructions on how to run the inference server.
The Poplar Triton backend is part of the Poplar SDK. It is packaged as a single plugin for the Triton Inference Server.
6.4. TensorFlow Serving
TensorFlow Serving is a library for serving pre-compiled machine learning models developed with TensorFlow or Keras. It is primarily for use with TensorFlow and Keras models but can be extended to serve other types of models.
Graphcore provides distributions of TensorFlow Serving 2 for the IPU (for TensorFlow 2) and TensorFlow Serving 1 for the IPU (for TensorFlow 1).
These user guides explain how to export and deploy your model with TensorFlow Serving.
IPU TensorFlow Serving is released as part of the Poplar SDK.
You can also use Model Runtime for TensorFlow models. Model Runtime is a Graphcore library that is included in the Poplar SDK.
6.5. ONNX models
The Poplar Advanced Runtime (PopART) enables you to import or build models using the Open Neural Network Exchange (ONNX) and run the model using Poplar tools. PopART is part of the Poplar SDK.
You will need to make some code changes to your ONNX model in order for it to run in inference mode on the IPU. You can find more details about the changes required in the Executing graphs section of the PopART User Guide. You can also find information about optimising performance for inference.
7. Distributed systems
PopRun is a powerful tool for scaling and you will need to use it if you are going to run your models on systems larger than a IPU‑POD64. It is a command line utility which lets you launch multiple instances of your application on one or more IPU Pods, which can increase performance for both training and inference.
The Poplar Distributed Configuration Library, PopDist provides a set of APIs to enable this.
To use PopRun effectively you need an understanding of how data parallelism and model parallelism can work to your advantage with ML models. With data parallelism you replicate your model over an IPU system and split the data up to run on the different instances of the same model; with model parallelism it is the model that is split across IPUs. The IPU Programmer’s Guide has useful information about parallelism and other algorithmic techniques which can make your model run more efficiently on the IPU.
8. Using IPUs in the Cloud
You can access IPUs in the Cloud on Paperspace, GCore and Graphcloud.
More details can be found in the getting started guides for each cloud provider:
You can easily and quickly run any of the Jupyter notebooks from our list of IPU-powered notebooks on Paperspace. These notebooks contain many examples of training, fine-tuning and inference for a wide variety of models and frameworks.
9. Hugging Face models
The Graphcore Optimum library is the interface between the Hugging Face Transformers library and IPUs and allows you to run training and inference with Hugging Face models on the IPU.
The tutorial Training a Hugging Face model on the IPU using a local dataset shows you how to reuse a Hugging Face model and train it on the IPU using a local dataset.
You can see all the models and datasets that are available on the Hugging Face Graphcore organisation page.
You can also run Hugging Face notebooks on IPUs on Paperspace.
10. Out of memory errors
Sometimes your model will not fit on the IPU(s) and you can get OOM (out of memory) errors.
You can use the PopVision Graph Analyser to analyse where you are running out of memory and there are options for adjusting memory use to resolve these errors. There is more information about how to resolve out of memory problems in the Memory and Performance Optimisation on the IPU guide.
11. CUDA code
You cannot directly port custom kernels from CUDA code to Poplar code. Creating custom operations for the IPU contains more details about how to handle custom functions.
12. Tutorials and examples
There are tutorials and code examples available on GitHub:
You can also search the Graphcore Model Garden and filter by model category, framework and type (training, inference).
13. Performance benchmarks
If you want to compare performance benchmarks for GPU and IPU you can find published performance benchmarks for some common models on IPU Pod platforms. This includes our results from the OGB-Large Scale Challenge, the MLPerf Training v2.0 submission, and results from our own benchmarking activities across a wider range of models for both training and inference.
You can reproduce our benchmarks. Refer to the Benchmarking tools section of the Examples repo README for details.
14. Useful resources
There is useful information about coding ML models on the Graphcore Developers page.
14.1. GitHub repositories
There are a number of Graphcore GitHub repositories that contain open source libraries, APIs, applications and code examples. The most popular are:
14.2. Documentation
The Graphcore Documentation portal contains all our public documentation and includes user guides and API references for our software, quick start and getting started guides, technical notes and whitepapers.
14.3. Other resources
You can browse the Graphcore Model Garden to find applications that run on IPUs. You can filter by category, model type and framework.
There are also how-to videos and webinars as well as useful blogs.
14.4. IPU-powered Jupyter notebooks
The list of IPU-powered Jupyter notebooks contains many examples of training, fine-tuning and inference for a wide variety of models and frameworks.
You can run these notebooks on Paperspace. More details about how to run the IPU notebooks on Paperspace can be found in the Paperspace: Getting Started with IPUs.
You can also use the Jupyter Notebook Quick Start if you are interested in running notebooks outside of the Paperspace environment.