6. Performance optimisation
This chapter describes techniques for optimising the performance of your model. For a general description of how to optimise memory and performance on the IPU, refer to the Memory and Performance Optimisation on the IPU.
6.1. Pipelined execution
Pipelining is a feature for optimising utilization of a multi-IPU system by parallelizing the execution of model partitions, with each partition operating on a separate mini-batch of data. We refer to these partitions here as pipeline stages. Refer to the section on ipu-programmers-guide:model parallelism and pipelining in the IPU Programmer’s Guide for a more detailed description of pipelining.
A simple example of pipelining in PopART is available in the Graphcore examples repository.
Note
The PopART tutorials are only supported up to Poplar SDK 3.1.
You can split a model into pipeline stages by annotating operations in the
ONNX model using the Builder class (Python,
C++).
You can place a specific operation on a specific pipeline stage. For example, to place a convolution onto pipeline stage 1, you can either do it directly as follows:
o = builder.aiOnnx.conv([x, w])
builder.pipelineStage(o, 1)
or you can use the context manager as follows:
with builder.pipelineStage(1):
o = builder.aiOnnx.conv([x, w])
Alternatively, if you have annotated the operations with VirtualGraph
attributes, then you can defer annotating pipeline stage attributes to
the Session constructor (Python,
C++). However, it is recommended that you profile
the model to choose a partitioning with the optimal utilization.
You can enable pipelined execution by setting the session option
enablePipelining to True (Python, C++).
Note that, by default, pipelining a training model with variable tensors stored over different pipeline stages results in ‘stale weights’ (see Zhang et al. 2019). This can be avoided by enabling gradient accumulation. In this case, the pipeline is flushed before the weight update applies the accumulated gradients. Gradient accumulation is described in detail in the IPU Programmer’s Guide.
6.2. Graph replication
PopART has the ability to run multiple copies of your model, in parallel, on distinct sets of IPUs. This is called graph replication. Informally, replication is a means of parallelising your inference or training workloads.
When training, weight updates are coordinated between replicas to ensure
replicas benefit from each other’s weight updates. A reduction is
applied on the weight updates across replicas according to the
ReductionType (Python,
C++) specified by the accumulationAndReplicationReductionType
session option (Python,
C++). The reductions involve some communication between replicas. This
communication is managed by PopART.
When you use replication, PopART also manages the splitting and distribution of
input data, making sure the data specified in the StepIO instance (Python,
C++) is split evenly
between replicas. This does mean you need to provide enough input data to
satisfy all (local) replicas.
There are two tiers of replication available in PopART:
local (Section 6.2.1, Local replication)
global (Section 6.2.2, Global replication)
Note
Replication is not supported on IPU Model targets.
6.2.1. Local replication
Local replications are replications managed by a single PopART
process. This means local replication is limited to those IPUs that are
accessible to the host machine that PopART is running on. To enable local
replication, set the session option
enableReplicatedGraphs to True (Python,
C++) and set replicatedGraphCount (Python,
C++) to the
number of times you want to replicate your model. For example, to replicate
a model twice, pass the following session options to your session:
opts = popart.SessionOptions()
opts.enableReplicatedGraphs = True
opts.replicatedGraphCount = 2
Note that if one replica of your model uses, say, 3 IPUs then with a
replicatedGraphCount of 2 you will need 6 IPUs to run both replicas.
Also, you will need to provide twice the volume of input data. The data returned
for each anchor tensor will include a local replication dimension for
all values of AnchorReturnType.
More details on the expected shapes of input and output data (for a given set of
session options) can be found in the C++ API documentation for the IStepIO and DataFlow classes, respectively.
6.2.2. Global replication
It is possible for multiple PopART processes (which means processes running on multiple hosts) to work together using global replication. With this option, as the PopART processes may run on separate hosts, you are not limited to using only the IPUs that are available to a single host. It is also possible to combine local and global replication.
To enable global replication, set enableDistributedReplicatedGraphs (Python,
C++) to
True and set globalReplicationFactor (Python, C++) to the desired total number of
replications (including any local replications). Finally, set
globalReplicaOffset (Python,
C++) to a different offset for each PopART
process involved, using offsets starting from 0 and incremented by the local
replication factor for each process.
For example, if the local replication factor is 2 and we want to replicate this
over four PopART processes then we need to configure a global replication
factor of 8. We then expect the globalReplicaOffset in the PopART
processes to be set to 0, 2, 4 and 6, respectively – the offset values increase in increments equal to the local replication factor. Then, for the second host, the configuration of the PopART session is as follows:
opts = popart.SessionOptions()
# Local replication settings.
opts.enableReplicatedGraphs = True
opts.replicatedGraphCount = 2
# Global replication settings.
opts.enableDistributedReplicatedGraphs = True
opts.globalReplicationFactor = 8
opts.globalReplicaOffset = 2 # <-- Different offset for each PopART instance
Note that when local and global replication are used together, the data provided
to each PopART instance (in the IStepIO instance passed to Session::run)
should contain only the data required for the local replicas. Moreover,
the output anchors will also only contain the output data for the local
replicas. Essentially, input and output data shapes are unaffected by global
replication settings.
More details on the input and output shapes can be found in the C++ API documentation for the IStepIO and DataFlow classes, respectively.
6.3. Sync configuration
In a multi-IPU system, synchronisation (sync) signals are used to ensure that IPUs are ready to exchange data and that data exchange is complete. These sync signals are also used to synchronise host transfers and access to remote buffers.
Each IPU can be allocated to one or more “sync groups”. At a synchronisation point, all the IPUs in a sync group will wait until all the other IPUs in the group are ready.
Sync groups can be used to to allow subsets of IPUs to overlap their operations. For example, one sync group can be transferring data to or from the host, while another sync group can be processing a batch of data that was transferred previously.
You can configure the sync groups using the PopART syncPatterns option (Python,
C++)
when creating a device with DeviceManager (Python,
C++). The types of sync patterns available are described in detail in Section 6.3.1, Sync patterns.
For example, the following code shows how to set the sync configuration to
SyncPattern.ReplicaAndLadder which allows for alternating between host I/O and processing.
sync_pattern = popart.SyncPattern.Full
if args.execution_mode == "PHASED":
sync_pattern = popart.SyncPattern.ReplicaAndLadder
device = popart.DeviceManager().acquireAvailableDevice(
request_ipus,
pattern=sync_pattern)
6.3.1. Sync patterns
There are three sync patterns available. These control how the IPUs are allocated to two sync groups.
The sync patterns are described with reference to Fig. 6.1, which shows four IPUs: A, B, C and D.
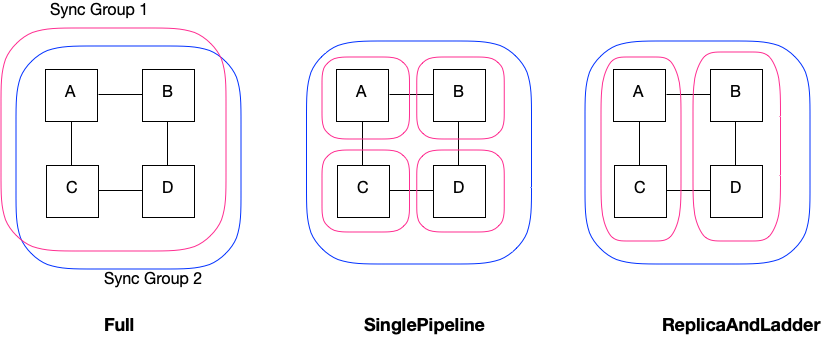
Fig. 6.1 Sync patterns
Full: All four IPUs are in both sync groups. Any communication between the IPUs or with the host, will require all IPUs to synchronise.
SinglePipeline: One sync group contains all four of the IPUs. So any communication using that sync group will synchronise all the IPUs.
The other sync group is used separately by each IPU. This means that they can each sync with the host independently, without syncing with each other. This allows any IPU to be doing host IO, for example, while others are processing data.
ReplicaAndLadder: One sync group contains all the IPUs. The other sync group is used independently by sets of IPUs, for example A+C and B+D. This means that each subset can communicate independently of each other. The two groups of IPUs can then alternate between host I/O and processing.
For more information on how the sync groups are used by the Poplar framework, please refer to the Sync groups section in the Poplar and PopLibs User Guide.