16. Application example: MNIST
In this section, you will see how to train a simple machine learning application in PopXL. The neural network in this example has two linear layers. It will be trained with the the MNIST dataset. This dataset contains 60,000 training images and 10,000 testing images. Each input image is a handwritten digit with a resolution of 28x28 pixels.
16.1. Import the necessary libraries
First, you need to import all the required libraries.
6import argparse
7from typing import Dict, List, Tuple, Mapping
8import numpy as np
9import torch
10from tqdm import tqdm
11import popxl
12import popxl.ops as ops
13import popxl.transforms as transforms
14from popxl.ops.call import CallSiteInfo
15from mnist_utils import Timer, get_mnist_data
16
16.2. Prepare dataset
You can use a torch.utils.data.DataLoader
for the training and validation data. Here, mnist is a function that returns
a torch.utils.data.DataSet for the MNIST dataset.
97 training_data = torch.utils.data.DataLoader(
98 mnist(train=True),
99 batch_size=batch_size,
100 shuffle=True,
101 drop_last=True,
102 )
103
104 validation_data = torch.utils.data.DataLoader(
105 mnist(train=False),
106 batch_size=test_batch_size,
107 shuffle=True,
108 drop_last=True,
109 )
16.3. Create IR for training
The training IR is created in build_train_ir. After creating an instance of IR, operations are added
to the IR within the context of its main graph. These operations are also forced to execute in the same
order as they are added by using context manager :py:func:~popxl.in_sequence`.
188 ir = popxl.Ir()
189 ir.num_host_transfers = 1
190 ir.replication_factor = 1
191 with ir.main_graph, popxl.in_sequence():
The initial operation is to load input images and labels to x and labels, respectively
from host-to-device streams img_stream and label_stream.
194 # Host load input and labels
195 img_stream = popxl.h2d_stream(
196 [opts.batch_size, 28, 28], popxl.float32, name="input_stream"
197 )
198 x = ops.host_load(img_stream, "x")
199
200 label_stream = popxl.h2d_stream(
201 [opts.batch_size], popxl.int32, name="label_stream"
202 )
203 labels = ops.host_load(label_stream, "labels")
After the data is loaded from host, you can build the network, calculate the loss and gradients, and finally update the weights. This process is shown in Fig. 16.1 and will be detailed in later sections.
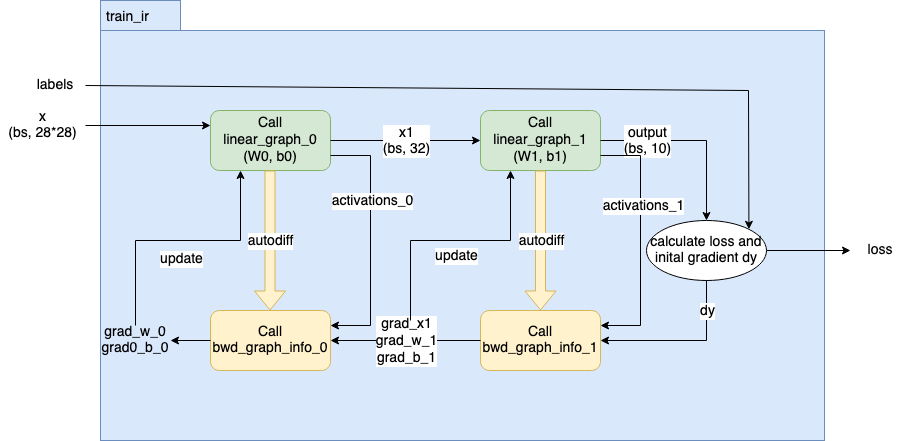
Fig. 16.1 Overview of how to build a training IR in PopXL
To monitor the training process, you can also stream the loss from the IPU devices to the host.
219 # Host store to get loss
220 loss_stream = popxl.d2h_stream(loss.shape, loss.dtype, name="loss_stream")
221 ops.host_store(loss_stream, loss)
16.3.1. Create network
The network has 2 linear layers. A linear layer is defined by the class Linear that
inherits from popxl.Module. We are here overriding the build method which builds the
subgraph to do the linear computation.
30class Linear(popxl.Module):
31 def __init__(self) -> None:
32 """
33 Define a linear layer in PopXL.
34 """
35 self.W: popxl.Tensor = None
36 self.b: popxl.Tensor = None
37
38 def build(
39 self, x: popxl.Tensor, out_features: int, bias: bool = True
40 ) -> Tuple[popxl.Tensor, ...]:
41 """
42 Override the `build` method to build a graph.
43 """
44 self.W = popxl.graph_input((x.shape[-1], out_features), popxl.float32, "W")
45 y = x @ self.W
46 if bias:
47 self.b = popxl.graph_input((out_features,), popxl.float32, "b")
48 y = y + self.b
49
50 y = ops.gelu(y)
51 return y
52
53
In the diagram Fig. 16.1, you can see two graphs created from the two linear
layers by using popxl.Ir.create_graph() and called by using popxl.call_with_info().
The tensors x1 and y are respectively the outputs of the first linear graph call and the
second linear graph. The weight tensors, bias tensors, output tensors, graphs, and graph callsite
infos are all returned for the next step. This forward graph of the network is created in the method
create_network_fwd_graph.
58def create_network_fwd_graph(
59 ir, x
60) -> Tuple[
61 Tuple[popxl.Tensor], Dict[str, popxl.Tensor], List[popxl.Graph], Tuple[CallSiteInfo]
62]:
63 """
64 Define the network architecture.
65
66 Args:
67 ir (popxl.Ir): The ir to create model in.
68 x (popxl.Tensor): The input tensor of this model.
69
70 Returns:
71 Tuple[Tuple[popxl.Tensor], Dict[str, popxl.Tensor], List[popxl.Graph], Tuple[CallSiteInfo]]: The info needed to calculate the gradients later
72 """
73 # Linear layer 0
74 x = x.reshape((-1, 28 * 28))
75 W0_data = np.random.normal(0, 0.02, (x.shape[-1], 32)).astype(np.float32)
76 W0 = popxl.variable(W0_data, name="W0")
77 b0_data = np.random.normal(0, 0.02, (32)).astype(np.float32)
78 b0 = popxl.variable(b0_data, name="b0")
79
80 # Linear layer 1
81 W1_data = np.random.normal(0, 0.02, (32, 10)).astype(np.float32)
82 W1 = popxl.variable(W1_data, name="W1")
83 b1_data = np.random.normal(0, 0.02, (10)).astype(np.float32)
84 b1 = popxl.variable(b1_data, name="b1")
85
86 # Create graph to call for linear layer 0
87 linear_0 = Linear()
88 linear_graph_0 = ir.create_graph(linear_0, x, out_features=32)
89
90 # Call the linear layer 0 graph
91 fwd_call_info_0 = ops.call_with_info(
92 linear_graph_0, x, inputs_dict={linear_0.W: W0, linear_0.b: b0}
93 )
94 # Output of linear layer 0
95 x1 = fwd_call_info_0.outputs[0]
96
97 # Create graph to call for linear layer 1
98 linear_1 = Linear()
99 linear_graph_1 = ir.create_graph(linear_1, x1, out_features=10)
100
101 # Call the linear layer 1 graph
102 fwd_call_info_1 = ops.call_with_info(
103 linear_graph_1, x1, inputs_dict={linear_1.W: W1, linear_1.b: b1}
104 )
105 # Output of linear layer 1
106 y = fwd_call_info_1.outputs[0]
107
108 outputs = (x1, y)
109 params = {"W0": W0, "W1": W1, "b0": b0, "b1": b1}
110 linears = [linear_0, linear_1]
111 fwd_call_infos = (fwd_call_info_0, fwd_call_info_1)
112
113 return outputs, params, linears, fwd_call_infos
114
115
16.3.2. Calculate gradients and update weights
After creating the forward pass in the training IR, we will calculate the gradients in calculate_grads
and update the weights and bias in update_weights_bias.
Calculate
lossand initial gradientsdyby usingnll_loss_with_softmax_grad().209 # Calculate loss and initial gradients 210 probs = ops.softmax(outputs[1], axis=-1) 211 loss, dy = ops.nll_loss_with_softmax_grad(probs, labels)
Construct the graph to calculate the gradients for each layer,
bwd_graph_info_0andbwd_graph_info_1by using :py:func:~popxl.transforms.autodiff` (Section 10.1, Autodiff) transformation on its forward pass graph. Note that, you only need to calculate the gradients forW0andb0in the first layer, and gradients for all the inputs,x1,W1andb1, in the second layer. In this example, you will see two different ways to useautodiffand how to use it to get the required gradients.Let’s start fromt the second layer. The
bwd_graph_info_1, returned fromautodiffof the second layer, contains the graph to calculate the gradient for the layer. The activations for this layeractivations_1is obtained from the corresponding forward graph call. After calling the gradient graph,bwd_graph_info_1.graphwithpopxl.ops.call_with_info, thegrads_1_call_infois used to get all the gradients with regard to the inputsx1,W1, andb1. The methodfwd_parent_ins_to_grad_parent_outsgives a mapping from the corresponding forward graph inputs,x1,W1, andb1, and their gradients,grad_x1,grad_w_1, andgrad_b_1. The input gradient forgrads_1_call_infoisdy.126 # Obtain graph to calculate gradients from autodiff 127 bwd_graph_info_1 = transforms.autodiff(fwd_call_infos[1].called_graph) 128 129 # Get activations for layer 1 from forward call info 130 activations_1 = bwd_graph_info_1.inputs_dict(fwd_call_infos[1]) 131 132 # Get the gradients dictionary by calling the gradient graphs with ops.call_with_info 133 grads_1_call_info = ops.call_with_info( 134 bwd_graph_info_1.graph, dy, inputs_dict=activations_1 135 ) 136 # Find the corresponding gradient w.r.t. the input, weights and bias 137 grads_1 = bwd_graph_info_1.fwd_parent_ins_to_grad_parent_outs( 138 fwd_call_infos[1], grads_1_call_info 139 ) 140 x1 = outputs[0] 141 W1 = params["W1"] 142 b1 = params["b1"] 143 grad_x_1 = grads_1[x1] 144 grad_w_1 = grads_1[W1] 145 grad_b_1 = grads_1[b1]
For the first layer, we can obtain the required gradients in a similar way. Here we will show you an alternative approach. We define the list of tensors that require gradients
grads_required=[linears[0].W, linears[0].b]inautodiff. Their gradients are returned directly from thepopxl.ops.callof the gradient graphbwd_graph_info_0.graph. The input gradient forgrads_0_call_infofis the gradients w.r.t the input of the second linear graph, the output of the first linear graph,grad_x_1.148 # Use autodiff to obtain graph that calculate gradients, specify which graph inputs need gradients 149 bwd_graph_info_0 = transforms.autodiff( 150 fwd_call_infos[0].called_graph, grads_required=[linears[0].W, linears[0].b] 151 ) 152 # Get activations for layer 0 from forward call info 153 activations_0 = bwd_graph_info_0.inputs_dict(fwd_call_infos[0]) 154 # Get the required gradients by calling the gradient graphs with ops.call 155 grad_w_0, grad_b_0 = ops.call( 156 bwd_graph_info_0.graph, grad_x_1, inputs_dict=activations_0 157 )
Update the weights and bias tensors with SGD by using
scaled_add_().165def update_weights_bias(opts, grads, params) -> None: 166 """ 167 Update weights and bias by W += - lr * grads_w, b += - lr * grads_b. 168 """ 169 for k, v in params.items(): 170 ops.scaled_add_(v, grads[k], b=-opts.lr) 171 172
16.4. Run the IR to train the model
After an IR is built taking into account the batch size args.batch_size, we can run it repeatedly until the end of the required
number of epochs. Each session is initiated by one IR as shown in the following code:
345 train_session = popxl.Session(train_ir, "ipu_model")
346 with train_session:
347 train(train_session, training_data, opts, input_streams, loss_stream)
The session is run for nb_batches times for each epoch. Each train_session run consumes a batch of input images
and labels, and produces their loss values to the host.
255def train(train_session, training_data, opts, input_streams, loss_stream) -> None:
256 nb_batches = len(training_data)
257 for epoch in range(1, opts.epochs + 1):
258 print(f"Epoch {epoch}/{opts.epochs}")
259 bar = tqdm(training_data, total=nb_batches)
260 for data, labels in bar:
261 inputs: Mapping[popxl.HostToDeviceStream, np.ndarray] = dict(
262 zip(
263 input_streams,
264 [data.squeeze().float().numpy(), labels.int().numpy()],
265 )
266 )
267
268 outputs = train_session.run(inputs)
269 loss = outputs[loss_stream]
270 bar.set_description(f"Average loss: {np.mean(loss):.4f}")
271
272
After the training session finishes running, the trained tensor values, in a mapping from tensors to their values trained_weights_data_dict,
are obtained by using train_session.get_tensors_data.
16.5. Create an IR for testing and run the IR to test the model
For testing the trained tensors, you need to create an IR for testing, test_ir, and its corresponding session,
test_session to run the test. The method write_variables_data is used to copy the trained values from
trained_weights_data_dict to the corresponding tensors in test IR, test_variables.
354 # Build the ir for testing
355 test_ir, test_input_streams, out_stream, test_variables = build_test_ir(opts)
356 test_session = popxl.Session(test_ir, "ipu_model")
357 # Get test variable values from trained weights
358 test_weights_data_dict = get_test_var_values(
359 test_variables, trained_weights_data_dict
360 )
361 # Copy trained weights to the test ir
362 test_session.write_variables_data(test_weights_data_dict)
363 with test_session:
364 test(test_session, test_data, test_input_streams, out_stream)