9. Graphs
9.1. Main graph
You can create the main graph of an IR by calling main_graph.
The returned main graph can be used as a context to include its operations
and tensors.
9.2. Graphs
You can create a subgraph (Section 3.2, Graphs) in PopXL by calling, for
example, create_graph(). You then connect the
subgraph with the calling graph with the call() op. In
PopXL, you have access to create_graph() before
you call a graph with call(), which gives you the
flexibility to manipulate the graph.
Listing 9.1 shows a basic example for how to create and
call subgraphs. In the example, a subgraph is created and called instead of
directly calling the Python function increment_fn().
16def increment_fn(x: popxl.Tensor):
17 return x + np.ones(x.shape, x.dtype.as_numpy())
18
19
20with main:
21 # host load
22 input = popxl.h2d_stream([2, 2], popxl.float32, name="input_stream")
23 x = ops.host_load(input, "x")
24
25 # create graph
26 increment_graph = ir.create_graph(increment_fn, x)
27
28 # call graph
29 (o,) = ops.call(increment_graph, x)
9.3. Creating a graph
You can create a subgraph by calling the function create_graph().
You can use the same function to create multiple subgraphs.
In the example in Listing 9.2, two different graphs are created
for different input tensors, w1 and w2, which have different shapes.
16def matmul_fn(x: popxl.Tensor, w: popxl.Tensor):
17 return x @ w
18
19
20with main:
21 # host load
22 input = popxl.h2d_stream([2, 2], popxl.float32, name="input_stream")
23 x = ops.host_load(input, "x")
24
25 w1 = popxl.variable(np.ones(x.shape, x.dtype.as_numpy()), name="w1")
26 w2 = popxl.variable(np.ones(x.shape[-1], x.dtype.as_numpy()), name="w2")
27
28 # create two graphs
29 matmul_graph1 = ir.create_graph(matmul_fn, x, w1)
30 matmul_graph2 = ir.create_graph(matmul_fn, x, w2)
31
Download create_multi_subgraphs_from_same_func.py
You can also create the subgraph with an additional graph input with graph_input()
in its Python function. graph_input() creates a new input tensor for the
subgraph. An example can be found in Listing 9.3.
9.4. Calling a graph
After you have created a subgraph, you can invoke it with call(). The input tensors are as follows:
call(graph: Graph,
*inputs: Union[Tensor, List[Tensor]],
inputs_dict: Optional[Mapping[Tensor, Tensor]] = None
) -> Union[None, Tensor, Tuple[Tensor, ...]]:
inputs are the inputs the subgraph requires and they must
be in the same order as in create_graph(). If you are not sure about the order
of the subgraph internal tensors that are defined by
graph_input(), you can use inputs_dict to
provide the mapping between the subgraph tensors and the parent graph tensors.
Listing 9.3 shows an example of a graph being called multiple times with different inputs.
In this example, the subgraph was created with an additional graph input value.
When you call this subgraph, you will have to pass a tensor to the subgraph
for this input as well. You can use it to instantiate the weights of layers internally.
16def increment_fn(x: popxl.Tensor):
17 value = popxl.graph_input(x.shape, x.dtype, "value")
18 return x + value
19
20
21with main:
22 # host load
23 input = popxl.h2d_stream([2, 2], popxl.float32, name="input_stream")
24 x = ops.host_load(input, "x")
25
26 # create graph
27 increment_graph = ir.create_graph(increment_fn, x)
28
29 # two variable values
30 value1 = popxl.variable(np.ones(x.shape, x.dtype.as_numpy()), name="value1")
31 value2 = popxl.variable(2 * np.ones(x.shape, x.dtype.as_numpy()), name="value2")
32
33 # call graph
34 (o,) = ops.call(increment_graph, x, value1)
35 (o,) = ops.call(increment_graph, o, value2)
Download multi_call_graph_input.py
Instead of calling a graph with call(), you can call it and get the information about the call site with the op
call_with_info(). This op returns a
CallSiteInfo object that provides extra information about the call site. For
instance, you can get the graph being called using called_graph.
inputs and outputs return the input tensors and
output tensors respectively. You can also obtain the input and output tensors at
a given index with parent_input(index) and
parent_output(index) respectively. You can find the input
graph tensor that corresponds to a parent tensor using
parent_to_graph (parent_tensor).
graph_to_parent(graph_tensor) provides an input or output tensor in
called_graph that associates the input or output tensor in the parent graph.
With the CallSiteInfo object, you can use set_parent_input_modified(subgraph_tensor) to specify
that the input tensor subgraph_tensor can be modified by this call_with_info() op. This provides
support for in-place variable updates as in Listing 9.4. After calling the subgraph, the value
of the variable tensor x is changed to 2.
15def increment_fn(x: popxl.Tensor):
16 value = popxl.graph_input(x.shape, x.dtype, "value")
17 # inplace increment of the input tensor
18 ops.var_updates.copy_var_update_(x, x + value)
19
20
21with main, popxl.in_sequence():
22 x = popxl.variable(1)
23 value1 = popxl.constant(1)
24
25 # create graph
26 increment_graph = ir.create_graph(increment_fn, x)
27 # call graph
28 info = ops.call_with_info(increment_graph, x, value1)
29 info.set_parent_input_modified(x)
30 # host store
31 o_d2h = popxl.d2h_stream(x.shape, x.dtype, name="output_stream")
32 ops.host_store(o_d2h, x)
The op call_with_info() is helpful when building and optimizing the backward graph. More details are given in Section 10.1, Autodiff.
9.5. Calling a graph in a loop
You can use the op repeat() to create a loop.
repeat(graph: Graph,
repeat_count: int,
*inputs: Union[Tensor, Iterable[Tensor]],
inputs_dict: Optional[Mapping[Tensor, Tensor]] = None
) -> Tuple[Tensor, ...]:
This calls a subgraph graph for repeat_count number of times.
Its inputs are:
inputsdenotes the inputs passed to the subgraph function and,
inputs_dictdenotes a mapping from internal tensors in the subgraph being called to tensors at the call site in the parent graph.
Both inputs from inputs and inputs_dict are “loop-carried” inputs. This
means that they are copied into the subgraph as inputs before the first
iteration is run. The outputs of each iteration are copied to the inputs of the
next iteration as shown in Fig. 9.1. The outputs of the last
iteration serve as the outputs of the repeat() op.
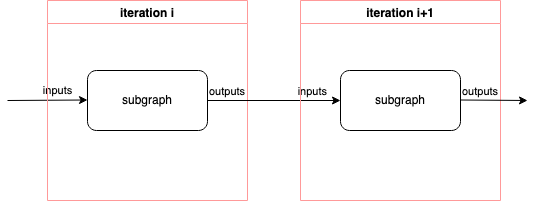
Fig. 9.1 Repeat op graph
The repeat() op requires that the number of the subgraph inputs, including the inputs and the inputs_dict, to be at least the number of outputs.
Note
This operation requires the repeat count to be greater than 0.
In Listing 9.5, the graph increment_graph
from increment_fn is called twice. The input x is incremented twice by
value. After the first iteration, the outputs x + value and value
are copied to the inputs for the second iteration.
15def increment_fn(x: popxl.Tensor, value: popxl.Tensor):
16 return x + value
17
18
19with main:
20 # host load
21 x = popxl.variable(np.ones([2, 2], np.float32), name="x")
22 value = popxl.variable(np.ones(x.shape, x.dtype.as_numpy()), name="value")
23
24 # create graph
25 increment_graph = ir.create_graph(increment_fn, x, value)
26
27 # call graph in a loop
28 (o,) = ops.repeat(increment_graph, 2, x, value)
Listing 9.6 shows how to use the
inputs_dict. The callable class Linear defines a linear
layer. The subgraph linear_graph is created from the PopXL build
method.
19class Linear(popxl.Module):
20 def __init__(self):
21 self.W: popxl.Tensor = None
22 self.b: popxl.Tensor = None
23
24 def build(
25 self, x: popxl.Tensor, out_features: int, bias: bool = True
26 ) -> Tuple[popxl.Tensor, ...]:
27 self.W = popxl.graph_input((x.shape[-1], out_features), popxl.float32, "W")
28 y = x @ self.W
29 if bias:
30 self.b = popxl.graph_input((out_features,), popxl.float32, "b")
31 y = y + self.b
32 return y
33
34
35with main:
36 # host load
37 x = popxl.variable(np.ones([2, 2], np.float32), name="x")
38 W = popxl.variable(np.ones([2, 2], np.float32), name="W")
39 b = popxl.variable(np.ones([2], np.float32), name="b")
40
41 # create graph
42 linear = Linear()
43 linear_graph = ir.create_graph(linear, x, out_features=2)
44
45 # call graph in a loop
46 # the x, W, b will be copied to the input of the `linear_graph` before the first iteration
47 # the outputs of each iteration will be copied to the inputs of the next iteration
48 # The outputs of the last iteration serve as the output of the `repeat` op
49 (o,) = ops.repeat(linear_graph, 2, x, inputs_dict={linear.W: W, linear.b: b})
9.6. Graph replication
For improved performance, multiple IPUs can run in data parallel mode. In data parallel mode multiple replicas of the graph are run on separate sets of IPUs.
Replicas can be grouped, see Section 14, Replication. By default, there is only one group. Replicas in a group are loaded with the same values.
Most operations can use replica grouping to reduce over only the grouped replica graphs, allowing for all replicas in a group to benefit from each other’s updates.
Graph replication cannot be used with IPU Model targets.
To set the replication factor (the number of replicated graphs), you
can set the ir.replication_factor.
9.7. Code loading from Streaming Memory
By default, tile memory is required for the tensors in the graph and for the executable code for the compiled graph. To help alleviate this memory pressure, as with tensors, you can store the executable code in Streaming Memory and load it, when required, back into executable memory on the tiles.
Note not all the code will be offloaded and re-loaded. For example, Poplar will decide whether mutable vertex state or global exchange code will remain always live. The code that is not offloaded will just stay in executable memory, and executing the graph will always work without the requirement to explicitly load those parts of code onto the IPU.
9.7.1. Minimal example
In PopXL, this code loading happens at the granularity of Graph objects, because
it is each Graph that is compiled into one or more poplar::Function objects, which is then
compiled into executable IPU code.
A minimal example follows:
23
24 with ir.main_graph:
25 # (1) insert many ops ...
26
27 with popxl.in_sequence():
28 # (2) load the code from remote memory into compute tiles on-chip
29 ops.remote_code_load(g, destination="executable")
30 # call the graph
31 ops.call(g, x)
32
33 # insert more ops...
34
35 # call the graph again
36 ops.call(g, x)
37
38 # (3) call the graph for the final time
39 ops.call(g, x)
40
From the example, you can see that no remote buffer for the Graph code is
explicitly created by the user. Instead, the ops.remote_code_load() for
that graph from Streaming Memory tells PopXL to create that remote buffer implicitly
for you. Multiple ops.remote_code_load calls from Streaming Memory on the same Graph
will reuse the same remote buffer. Note it is your responsibility to remember to insert
the remote_code_load op, otherwise it will seem to PopXL that the user intends
to have the code always-live in executable memory as normal. The
in_sequence() context around the remote_code_load and call is
also mandatory to ensure the copy is scheduled before the call. The need for
this is explained later. The other possible values of the parameter
destination are also explained later.
In the above example, all the ops and tensors will be lowered into Poplar as
usual, then the Poplar liveness analyser will try to minimise liveness across the
computation by reusing memory where available. In this case, the liveness
analyser will see that the code does not need to be live until the
remote_code_load call. Therefore the code is “dead” from (1) until
(2), and hence less memory is consumed during this time. After
the remote_code_load, the code is considered live. We can call the Graph
(that is, execute the code) as many times as we want — the code is still on device.
At (3), we call the
Graph for the final time. The Poplar liveness analyser may use this fact
to consider the code dead after this point, and again recycle that memory for
another use.
To summarise, the code is only live from (2) to (3), whereas without
code loading, the code would have been always-live.
Note that when we say the code is “dead” or “not live”, it is not guaranteed that the memory will indeed be reused for something else, only that it could be. Any part of the compilation stack may choose to optimise the graph in a different way instead if it believes doing so to be more beneficial.
Lastly, the fact that the remote_code_load and call are inside an
in_sequence context is very important. Recall that, in PopXL, you are
building a data-flow graph of ops and tensors, and by default they will execute
in whatever order the internal scheduler decides best (it aims to minimise
liveness). Observe that there is no data-flow dependence between the
remote_code_load and the call, meaning there is no tensor that the
remote_code_load produces that the call consumes. This means, without
the in_sequence, they could be scheduled in any order, and if the call
comes first, the Poplar liveness analyser will think the code needs to be
always-live (in the case of the above example). Therefore, failing to use
in_sequence results in undefined behaviour with respect to the code
liveness, and the onus is on you to remember to use it.
9.7.2. Controlling liveness between multiple calls
Every time you call a graph, it signifies that the code should be in tile
executable memory since either the last
remote_code_load(destination='executable'), or if there is no previous
remote_code_load(destination='executable'), the start of the program, in other words
the code is always-live.
Every time you use remote_code_load to load a Graph into a location, it signifies
that the code did not need to be live in that location since the last call, or
if there is no previous call, from the start of the program.
Together, this gives full control of the code liveness of your graphs. Say
you have repeated calls to a Graph and you want the code to always be dead
in between calls until the latest possible moment. You simply insert
remote_code_load ops just before every call. The following example
demonstrates this:
44
45 with ir.main_graph:
46 with popxl.in_sequence():
47 # Dead...
48
49 # Live
50 ops.remote_code_load(g, destination="executable")
51 ops.call(g, x)
52
53 # Dead again, due to a subsequent load...
54
55 # Live again
56 ops.remote_code_load(g, destination="executable")
57 ops.call(g, x)
58
59 # Dead again, due to a subsequent load...
60
61 # Live again
62 ops.remote_code_load(g, destination="executable")
63 ops.call(g, x)
64
65 # Dead again, as graph never called again
66
Note in the example we do not copy back the code from device to Streaming Memory. This is for two reasons. Firstly, the code has no mutable state, so it is valid to just keep loading repeatedly from the same remote buffer. In Poplar, it is possible for code to have “mutable vertex state”, but currently Poplar will never offload that part of the code anyway and keep it always-live. Secondly, Poplar attempts no liveness analysis in Streaming Memory to reuse a buffer for something else when it is not needed. If this were the case, copying the code to device would effectively free that space in Streaming Memory; so since that space cannot be reused, it is pointless to perform the copy. Therefore, there is no API for copying code to Streaming Memory.
9.7.3. Optimisation: merging the code load operations
Poplar will attempt to merge exchanges of code data just like with other remote
buffer copies. That is, if you are loading code for multiple
graphs, and if there are no ops that cause a global exchange between the load ops in
the schedule (which you can ensure is the case using in_sequence), then
Poplar will merge the exchanges for those loads, resulting in a speed-up. In
PopXL, it is up to you to decide if this is beneficial for your use-case
and impose such a schedule using in_sequence().
Secondly, again as with regular tensors, careful scheduling of the ops can
ensure the IO of the code loading overlaps with computation. Though we cannot
give a full exposition of overlapped IO here, the basics are as follows: if
you want IO A to overlap with compute B:
Amust come beforeBin the schedule.There can be no data-dependency between
AandB.Amust be placed on IO tiles.Bmust be placed on compute tiles.If
Aconsists of multiple stream copies, they must be adjacent in the Poplar sequence so that they are mergeable.
9.7.4. Advanced example: nested code loading
To help us further understand the semantics of code loading, let’s examine
a nested example where we use remote_code_load to load a graph that
uses remote_code_load to load another graph:
18
19 def expensive_id(x: popxl.Tensor) -> popxl.Tensor:
20 return x.T.T
21
22 g1 = ir.create_graph(expensive_id, x.spec)
23
24 def load_g1():
25 ops.remote_code_load(g1, destination="executable")
26
27 g2 = ir.create_graph(load_g1)
28
29 with ir.main_graph, popxl.in_sequence():
30 # Loads code for g1
31 ops.remote_code_load(g1, destination="executable")
32
33 # Loads code for g1
34 ops.call(g2)
35
36 # Execute g1
37 ops.call(g1, x)
38
In this example, calling g1 performs the load for g2. After this, we can
now execute g2 on device.
We could also change the load_g1 function to instead take the Graph as a
parameter, then dynamically make many graphs for loading the code of other
graphs. Note however that the graph that performs the loading cannot
dynamically load any graph — it is fixed to a certain graph on creation.
Only the function load_graph for creating such a Graph is dynamic and
can be reused for creating many graphs:
42
43 def load_graph(g: popxl.Graph):
44 ops.remote_code_load(g, destination="executable")
45
46 g3 = ir.create_graph(load_graph, g1)
47 g4 = ir.create_graph(load_graph, g2)
48
49 with ir.main_graph, popxl.in_sequence():
50 ops.remote_code_load(g3, destination="executable")
51 ops.call(g3)
52
53 ops.remote_code_load(g4, destination="executable")
54 ops.call(g4)
55
9.7.5. Advanced concept: code loading in dynamic branches
Graphs can have dynamic branching in them, for example through an if op.
Say there are ops.remote_code_load ops in these dynamic
branches, what effect will this have on the liveness of that code?
Liveness analysis is a static compile-time concept. We do not know which branch
will be taken at runtime. Say we perform the remote_code_load op in only one of
the branches, then call the graph after the branches merge again (so after
the if op). At the point of the call, the compiler does not know if the
remote_code_load will have happened or not, as it does not know which branch
will be taken at runtime. The compiler has to produce a program that accounts
for all possible cases, so it must pessimistically plan as if the
remote_code_load did not happen. Therefore, it will assume the code was
already live on the device before the branching.
Essentially, if there is branching before a call, only if all possible
branches contain a remote_code_load can we assume that the code was dead and
in Streaming Memory until the remote_code_load op. If any possible branch does
not perform a remote_code_load, we must assume that there was no
remote_code_load and the code was already live before the branching.