5.6. CPU packing
5.6.1. Background
The IPU runs static graphs and processes input data of a fixed size each time. If the input length is not fixed, additional zero padding operations are required; otherwise, the data processing power of the IPU cannot be effectively utilised.
The CPU packing functionality is implemented through the popart.PackRunner class and is specifically designed for a dynamic sequence length. After the user request is packed, the number of zero paddings is greatly reduced. When packing is combined with model modifications to achieve the equivalent transformations, the data processing efficiency of the IPU can be effectively utilised.
5.6.2. Functional modules
In essence, packing accumulates user requests of unfixed lengths within a fixed period of time and then packs the data together and sends it to the IPU in one batch.
Timeout processing
In order to increase the amount of valid data sent to the IPU, it is necessary to accumulate batches over a certain period of time. This is achieved by setting a timeout.
User data preprocessing
If the data has already been filled with zeros, this zero-filled data will be removed during preprocessing based on mask data provided in the request.
Data accumulation
Pack maintains an internal queue, where user requests will be queued. When the timeout module issues a request or the data being packed reaches the maximum value (reaches the maximum number of entries or about to exceed the model input size), PackRunner will send the accumulated requests to the IPU (out of queue).
Post-packing processing
After the IPU operation is completed, the packing program will be notified to retrieve the data and copy the output back to the user address. The user program will obtain the result corresponding to the input. No special processing is required.
There are two situations when packing copies data:
If the unpack operator is inserted in the network, then the output length is fixed. Simply copy it back according to the fixed length.
If there is no unpack operator in the network, then the default output length copied back is equal to the effective length of the input data (the input excludes the length of the user pad).
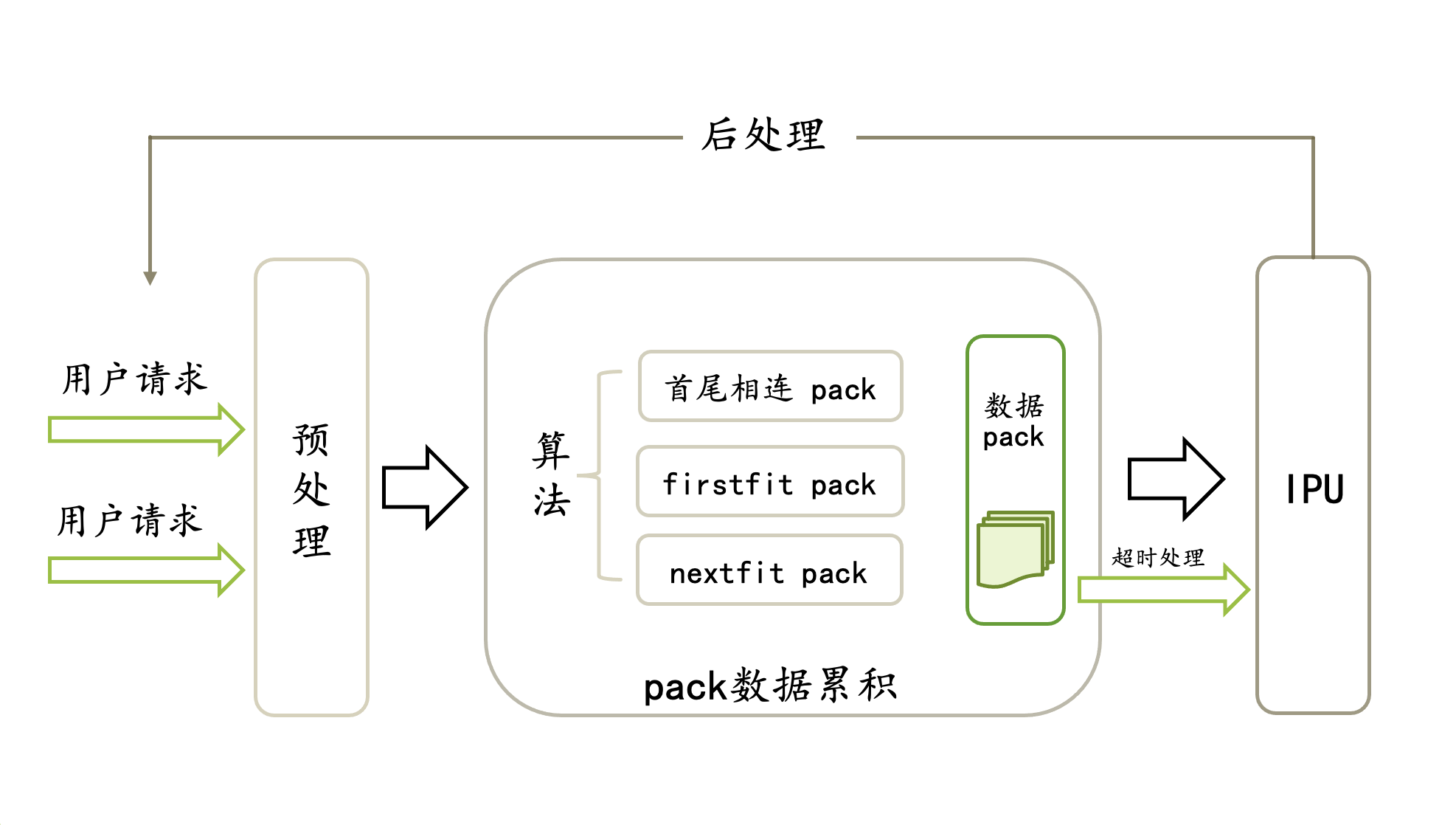
Fig. 5.8 Schematic diagram of packing functional modules
5.6.3. Packing algorithms
CPU packing currently supports the following methods:
end-to-end
FirstFit
NextFit
Packing has the following three restrictions built in:
The total number of data entries in the packing cannot exceed the value set for
maxValidNum.The total data length of the packing cannot exceed the maximum length of the input when compiling the model.
The time interval between the first and last data of the packing cannot exceed the maximum value set by the user.
End-to-end method
The end-to-end packing method (Fig. 5.9) is used to concatenate the data end-to-end until the set maximum number of entries is reached or the maximum input value (input size when compiling the model) is about to be exceeded. With the end-to-end packing method, data can cross lines, and the unpack and repack operators need to be inserted into the network.
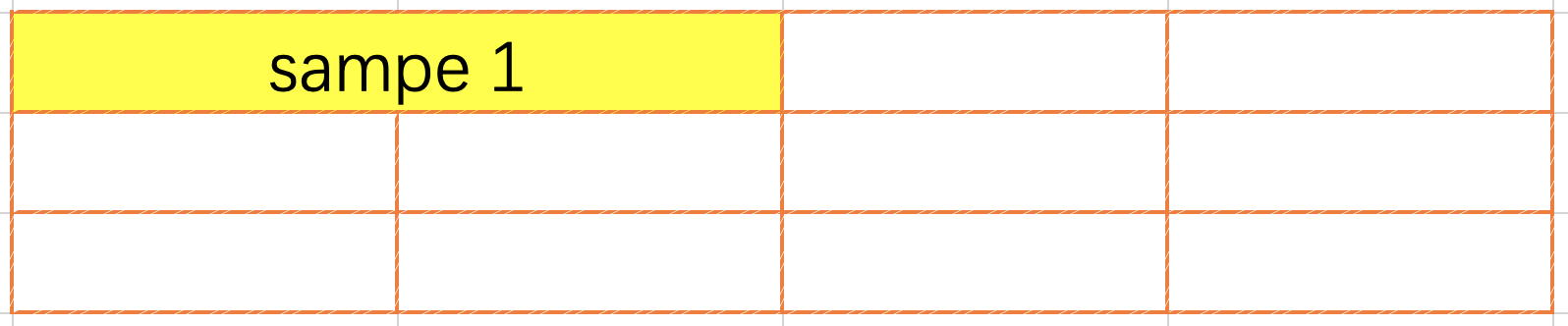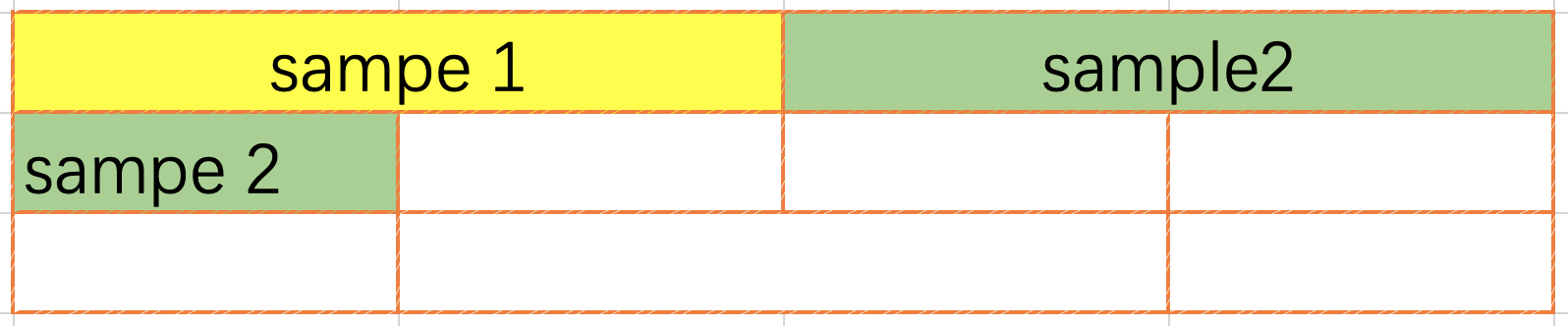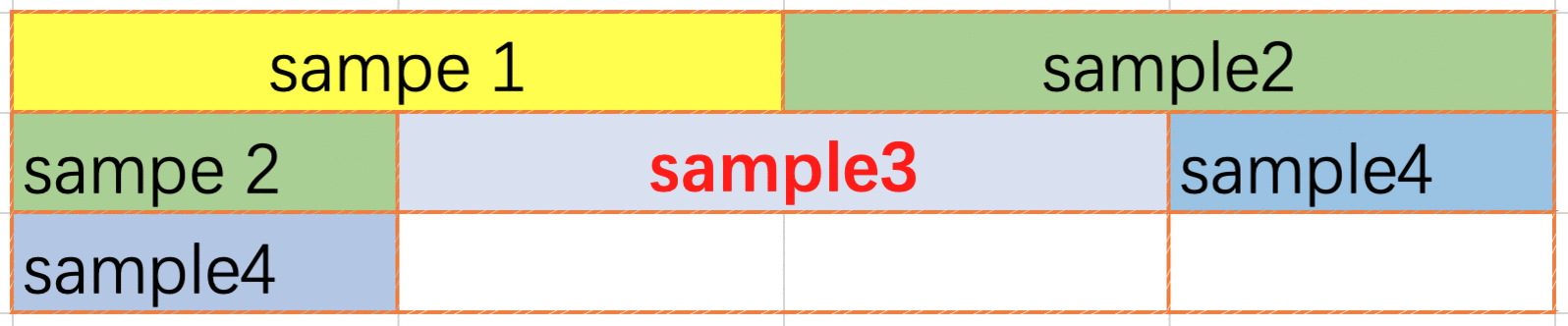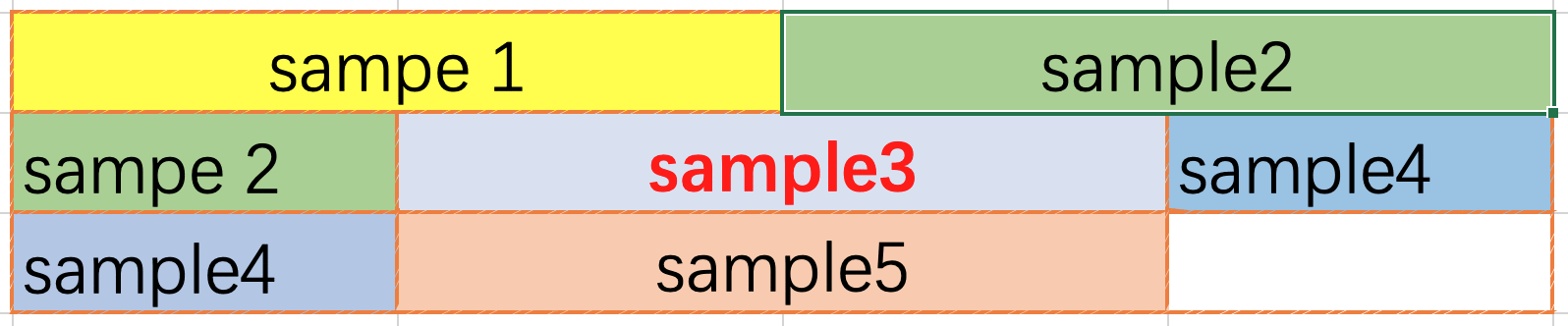
Fig. 5.9 End-to-end packing
FirstFit method
The FirstFit packing method (Fig. 5.10) is an “intraline” method, which means that data cannot cross lines. When a user request arrives, the scanning will start from the first line, until a line is found to put this data in. If a line is not found, then it will start a new line. According to network requirements, it may be necessary to insert several zeros as separators between two entries of data. A separator is not required before the first entry of data in the line. Although FirstFit changes the relative order of user requests within the packing, the result order will be consistent with the input order for the user because the built-in program will adjust the result order. Compared to NextFit, FirstFit improves space utilisation.
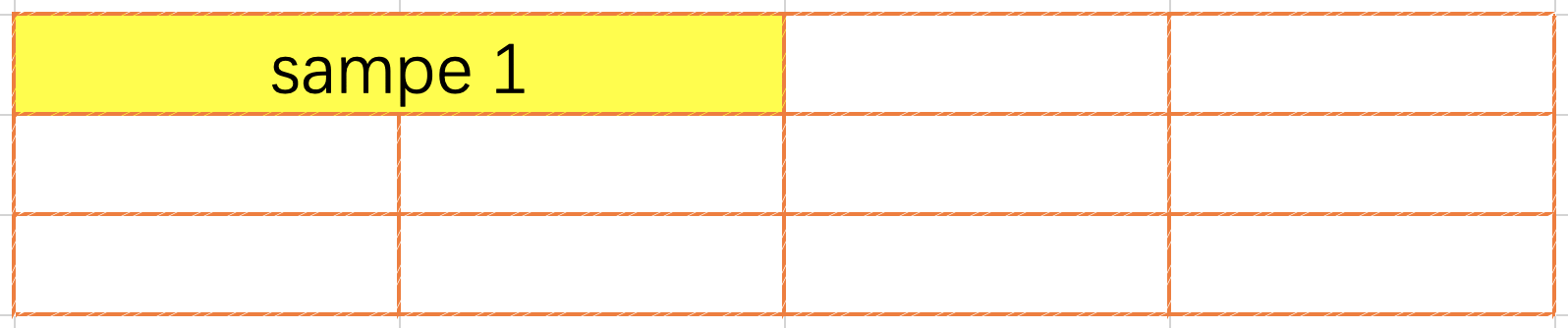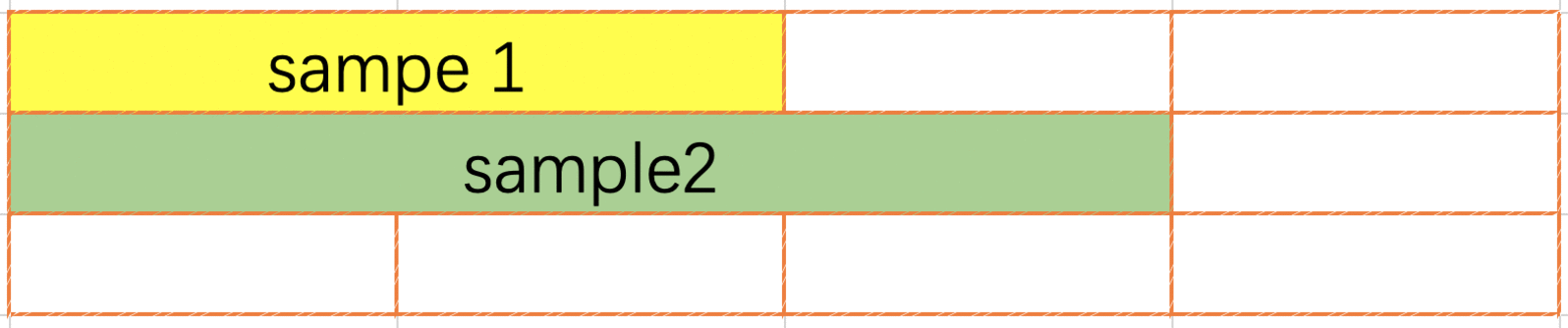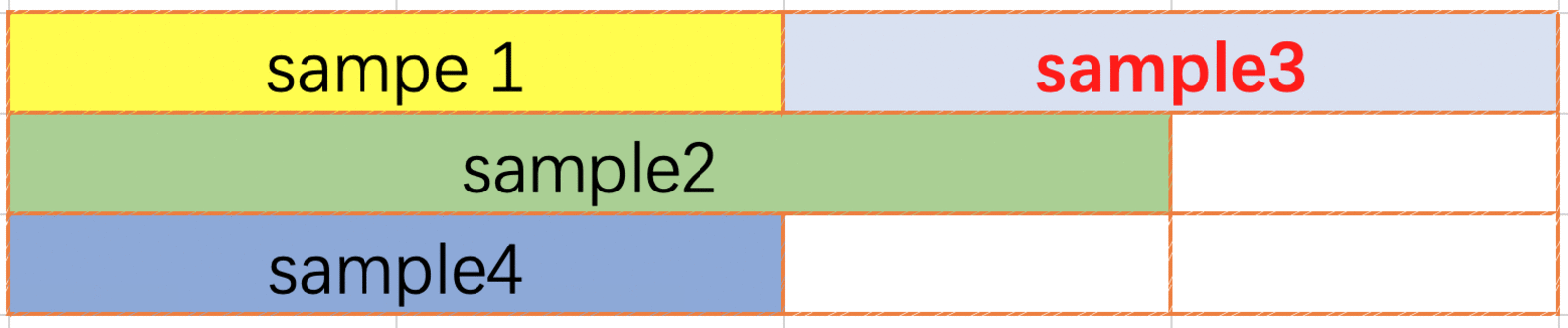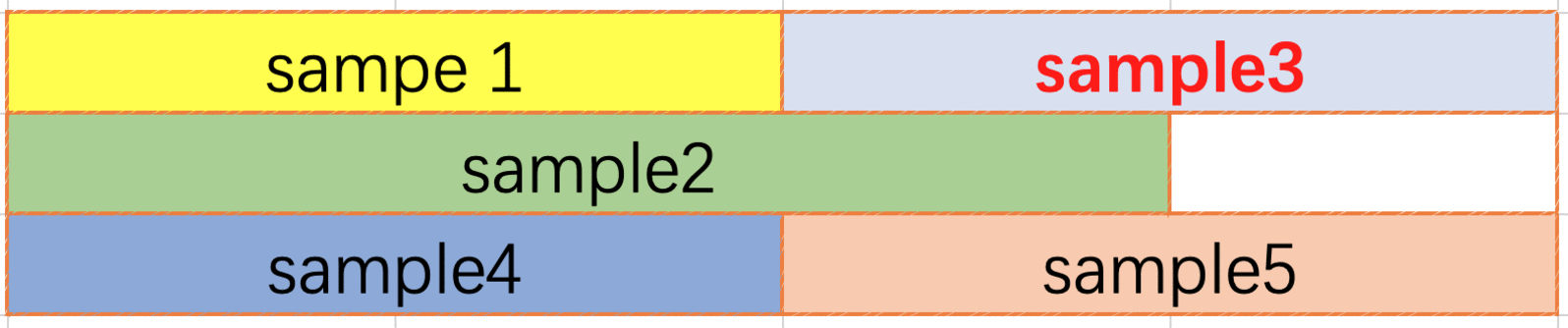
Fig. 5.10 FirstFit packing
NextFit method
NextFit packing (Fig. 5.11) is also an intraline packing method, and data cannot cross lines. When a user request arrives, the scanning will start from the end of the previous entry of data until a line is found to put this data in. If a line is not found, then it will start a new line.
Similarly, the total data length of the packing cannot exceed the maximum length of the input at the compiling time. Like FirstFit, it may be necessary to insert separators between two entries of data.

Fig. 5.11 NextFit packing
5.6.4. Examples
PopRT contains two end-to-end examples to illustrate how to use packing on the IPU. Each example includes the three packing algorithms and the corresponding performance data. PopRT examples are available on the examples code page.
BERT packing example: packed_bert_example
DeBERTa packing example: packed_deberta_example
For detailed instructions, see README.md in each directory.