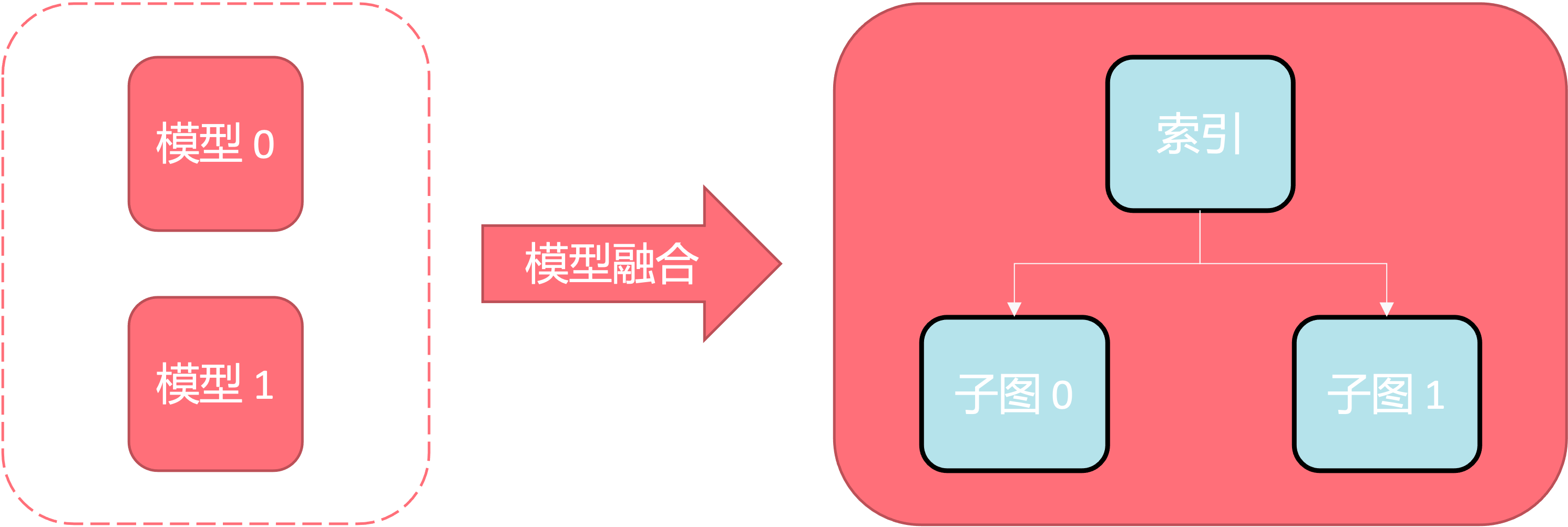
5.7. Model fusion
For Poplar, the model is first compiled into a binary executable that can be executed on the IPU, and then loaded into the IPU for execution. Since Poplar currently only supports the loading of one executable at the same time, executing multiple models on one IPU can cause repeated loading of different executables, leading to a sharp decrease in performance.
The function of model fusion is to fuse multiple user models into one model in the compilation stage, with each model serving as a subgraph of the fused model. The subgraphs are isolated from each other by branch operators. At runtime, controlling which subgraph to run by inputting the model index can greatly reduce the latency of model switching.
Before reading this chapter, it is necessary to be familiar with the following:
5.7.1. Implementing PopRT model fusion
At present, this feature can only be enabled through the YAML configuration file. You need to define the ONNX model to be fused and other related parameters in the YAML configuration file.
An example of the YAML file is as follows:
1output_dir: './'
2output_model: 'model_fusion.onnx'
3export_popef: True
4max_tensor_size: -1
5ipu_version: 'ipu21'
6model_fusion:
7 - input_model: 'model0.onnx'
8 input_shape: ['X=1,2', 'Y=1,2']
9 precision: 'fp32'
10
11 - input_model: 'model1.onnx'
12 input_shape: ['X=1,1']
13 precision: 'fp16'
You can configure independent parameters for each model in model_fusion. Parameters other than model_fusion are global parameters, which apply to each model to be fused.
For instance, max_tensor_size = -1 in the example, since it is defined in global parameters, it will apply to all models.
The fused model needs to be run through the PopRT Runtime; therefore, export_popef must be set to True to generate the PopEF model.
Furthermore, in order to ensure the running of the subsequent inference code, ipu_version needs to be set correctly based on the running device; for example, ipu21 needs to be set for the C600 platform..
An example of model fusion is:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import os
3
4import numpy as np
5import onnx
6
7from onnx import TensorProto, checker, helper, mapping
8
9
10def create_model0(opset_version=11):
11 g0_dtype = TensorProto.FLOAT
12 g0_add = helper.make_node("Add", ["X", "Y"], ["Z"])
13 g0_reshape = helper.make_node("Reshape", ["Z", "C"], ["O"])
14 g0 = helper.make_graph(
15 [g0_add, g0_reshape],
16 'graph',
17 [
18 helper.make_tensor_value_info("X", g0_dtype, (1, 2)),
19 helper.make_tensor_value_info("Y", g0_dtype, (1, 2)),
20 ],
21 [
22 helper.make_tensor_value_info("O", g0_dtype, (2,)),
23 ],
24 )
25
26 g0_const_type = TensorProto.INT64
27 g0_const = helper.make_tensor(
28 "C",
29 g0_const_type,
30 (1,),
31 vals=np.array([2], dtype=mapping.TENSOR_TYPE_TO_NP_TYPE[g0_const_type])
32 .flatten()
33 .tobytes(),
34 raw=True,
35 )
36 g0.initializer.append(g0_const)
37 m0 = helper.make_model(g0, opset_imports=[helper.make_opsetid("", opset_version)])
38 checker.check_model(m0)
39 return m0
40
41
42def create_model1(opset_version=11):
43 g1_dtype = TensorProto.FLOAT16
44 g1_concat = helper.make_node("Concat", ["X", "C"], ["O"], axis=1)
45 g1 = helper.make_graph(
46 [g1_concat],
47 'graph',
48 [
49 helper.make_tensor_value_info("X", g1_dtype, (1, 1)),
50 ],
51 [
52 helper.make_tensor_value_info("O", g1_dtype, (1, 3)),
53 ],
54 )
55
56 g1_const = helper.make_tensor(
57 "C",
58 g1_dtype,
59 (1, 2),
60 vals=np.array([[1.5, 2.0]], dtype=mapping.TENSOR_TYPE_TO_NP_TYPE[g1_dtype])
61 .flatten()
62 .tobytes(),
63 raw=True,
64 )
65 g1.initializer.append(g1_const)
66 m1 = helper.make_model(g1, opset_imports=[helper.make_opsetid("", opset_version)])
67 checker.check_model(m1)
68 return m1
69
70
71def create_onnx(opset):
72 model0 = create_model0(opset)
73 model1 = create_model1(opset)
74
75 onnx.save(model0, "model0.onnx")
76 onnx.save(model1, "model1.onnx")
77
78
79if __name__ == '__main__':
80 abs_path = os.path.abspath(os.path.dirname(__file__))
81 if os.getcwd() != abs_path:
82 raise RuntimeError(f"Please run program in {abs_path}")
83
84 create_onnx(opset=11)
85
86 cmd = "poprt \
87 --config_yaml config.yaml "
88
89 os.system(cmd)
This example will create the ONNX model required for the YAML file shown above, call PopRT to read the YAML file for model fusion and generate the executable.popef set in the YAML.
After the compilation is completed, you can view the metadata of the fused model through popef_dump, which is the necessary information for the subsequent runtime.
An example of the command is:
popef_dump executable.popef
After the successful running of the above command, the terminal will display the relevant information of this PopEF file. Under the Anchors keyword, you can see the input/output name, type, shape and other information of the compiled static graph, of which, there will be an input named index which is used to control the selection of subgraphs.
5.7.2. Implementing PopRT Runtime fusion model inference
To run the PopEF file compiled by the PopRT model fusion, you need to write a program for inference through the PopRT Runtime.
An example of the program is:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import os
3
4import numpy as np
5import numpy.testing as npt
6
7from poprt.runtime import Runner, RuntimeConfig
8
9if __name__ == '__main__':
10 abs_path = os.path.abspath(os.path.dirname(__file__))
11 if os.getcwd() != abs_path:
12 raise RuntimeError(f"Please run program in {abs_path}")
13
14 popef_path = f"{abs_path}/executable.popef"
15
16 config = RuntimeConfig()
17 config.timeout_ns = 0
18 config.validate_io_params = False
19 runner = Runner(popef_path, config)
20
21 g0_X = np.ones([1, 2], dtype=np.float32)
22 g0_Y = np.ones([1, 2], dtype=np.float32) * 2
23 g0_O = np.zeros([2], dtype=np.float32)
24
25 runner.execute(
26 {
27 "graph0/X": g0_X,
28 "graph0/Y": g0_Y,
29 },
30 {
31 "graph0/O": g0_O,
32 },
33 )
34 npt.assert_array_equal(g0_O, np.ones([2], dtype=np.float32) * 3)
35
36 g1_X = np.zeros([1, 1], dtype=np.float16)
37 g1_O = np.zeros([1, 3], dtype=np.float16)
38
39 runner.execute(
40 {
41 "graph1/X": g1_X,
42 },
43 {
44 "graph1/O": g1_O,
45 },
46 )
47 npt.assert_array_equal(g1_O, np.array([[0.0, 1.5, 2.0]], dtype=np.float16))
This example shows how to run the PopEF file generated above.
The first step is to create the RuntimeConfig instance and configure the running parameters of ModelRunner.
Note: be sure to set validate_io_params to False, since the fusion graph does not need to process data for each input/output. Setting this parameter to True will cause errors.
The second step is to create the ModelRunner instance and load the PopEF file, so as to load the model into the IPU.
The third step is to set the input/output of the subgraph and specify the subgraph through index. If set to 0, the subgraph 0 can be specified.
If index is not specified, PopRT Runtime will fill it automatically, as shown in the example.