5.4. Dynamic batch size
5.4.1. Background
Since the IPU only supports static graphs, the fixed batch size needs to be specified during the model compilation stage. However, in the actual inference process, the batch size of the input data is usually not fixed. PopRT supports input data of any batch size by setting the following:
timeout_ns: The timeout period for PopRT to wait for data to form the batch size required by the PopEF model. The default setting is 5 ms.batching_dim: The dimension that contains the value for the batch size. The default value is0xFFFFFFFF, indicating that dynamic batch sizing is disabled.
Each batch of inference data processed on the IPU is based on the batch size of the loaded model. For example, the shape of the model in Fig. 5.4 is [4,2], and the dimension of the batch size is 0. This means that data with a batch size of 4 is processed each time. When the batch size of the input data is N (where N is an integer greater than or equal to 1) times the batch size of the model, the inference result is returned after N times of inference on the IPU. In this case, there is no need to wait for the timeout_ns timeout.
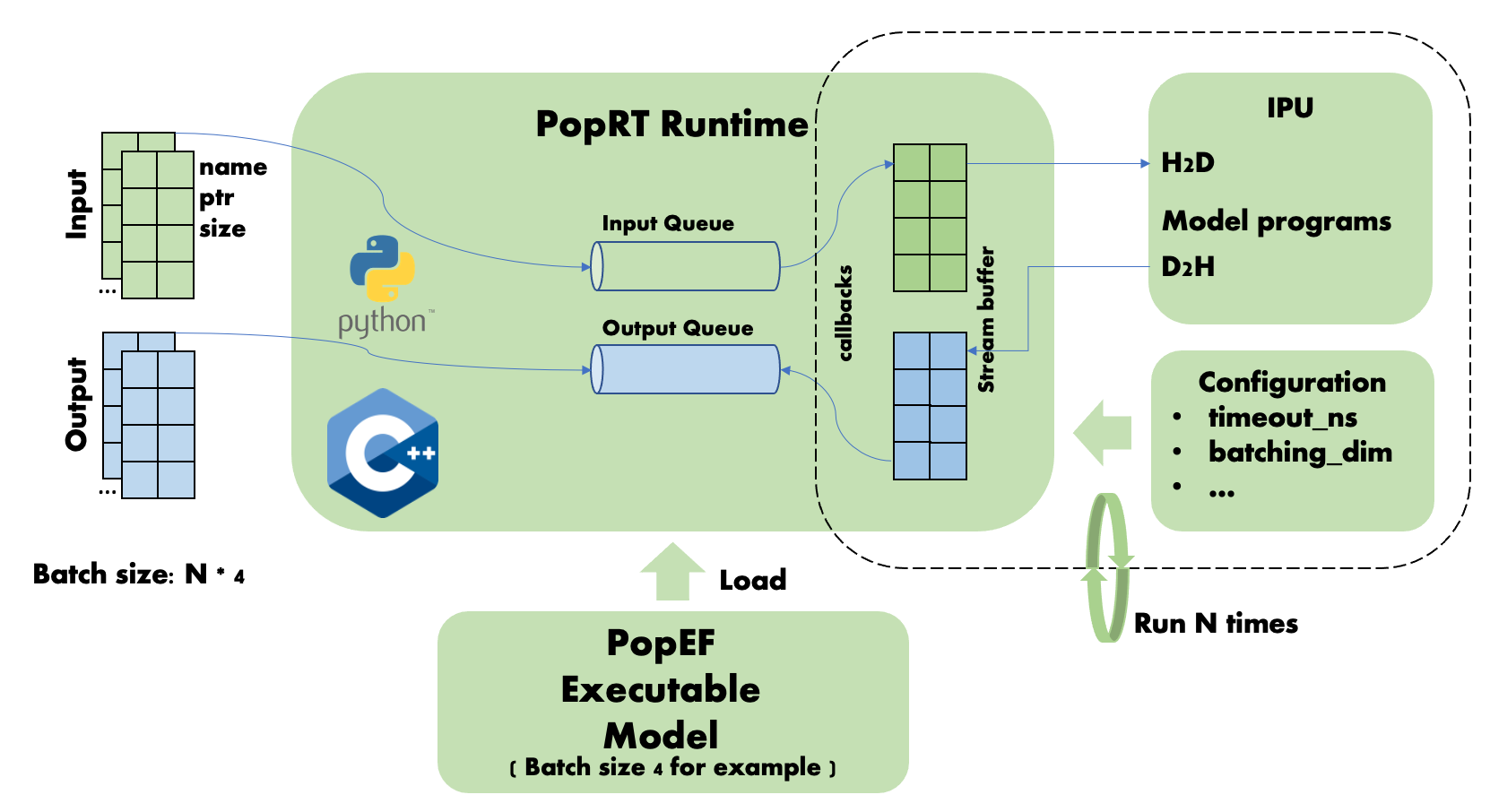
Fig. 5.4 Dynamic batch size
If the batch size of the input data is N (where N is an integer greater than or equal to 1) times the batch size of the model plus M (where M is an integer smaller than or equal to the batch size), the N times data processing is the same as the processing in Fig. 5.4, data M being smaller than the batch size of the model must wait for the timeout set by timeout_ns. If one or more subsequent sets of data are merged with the data M within this time and the batch size is reached, then an inference will be performed to obtain the result. If the data fails to reach the batch size before the timeout, the missing part will be set to 0 and an inference will be performed to obtain the result. As shown in Fig. 5.5, after two requests, batch sizes 1 and 2 are merged, the timeout is reached, and the remaining data with batch size 1 will be set to 0.
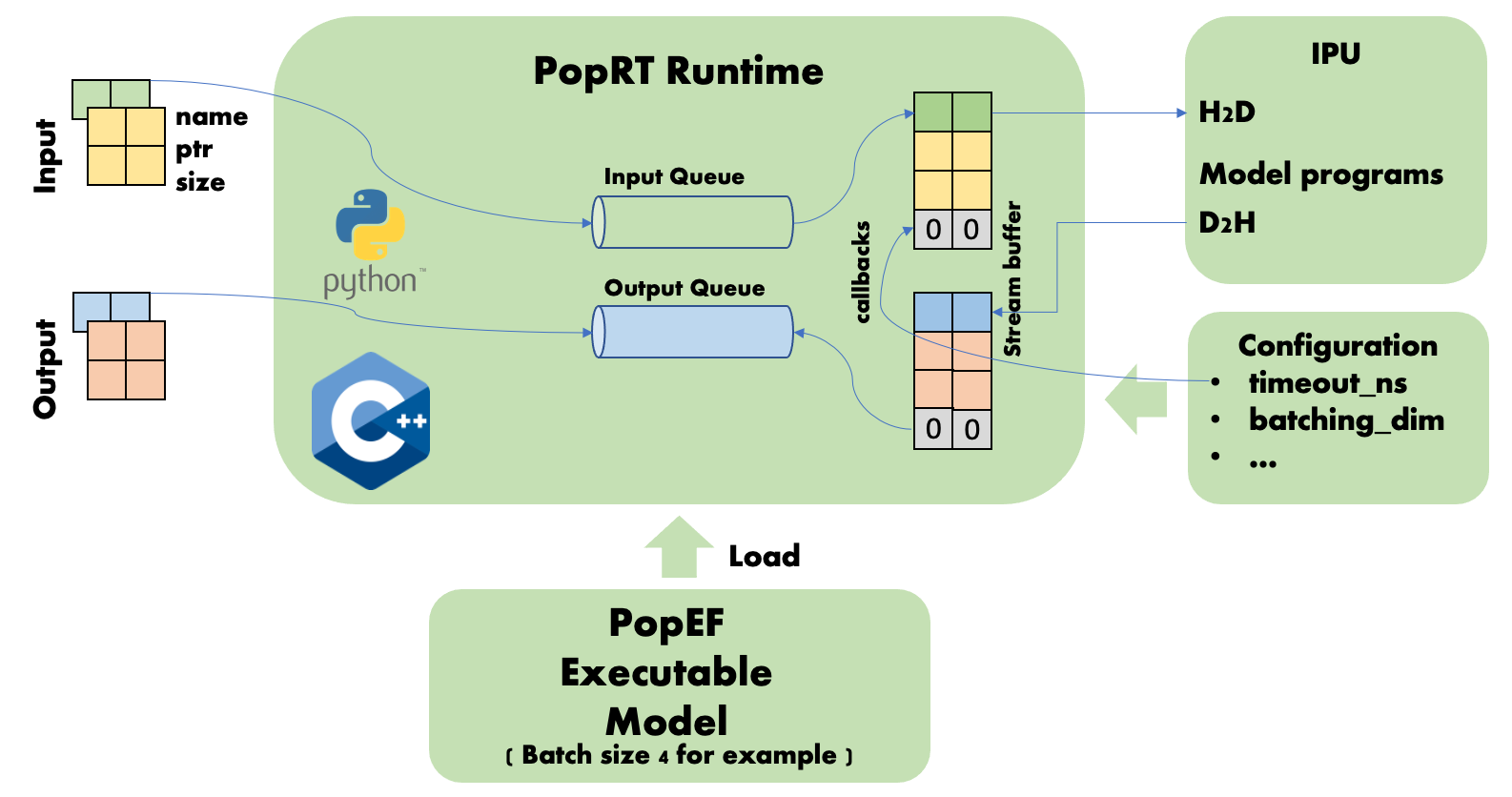
Fig. 5.5 Dynamic batch size timeout
The function of dynamic batch sizing is transparent to the user program. Users do not need to worry about the batch size of the loaded model in the current IPU. Just send the inference request data according to the requirements of the application.
5.4.2. Example
Listing 5.2 shows an example using dynamic batch sizing. In the example, we create a model with an input shape of [4, 2] and a batch size of 4. The application uses data with batch sizes of 1, 4 and 7, respectively, for inference, without considering the batch size of the loaded model.
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import numpy as np
3import numpy.testing as npt
4import onnx
5
6from onnx import helper
7
8from poprt import runtime
9from poprt.compiler import Compiler
10from poprt.runtime import RuntimeConfig
11
12
13def default_model():
14 """Create a test model."""
15 TensorProto = onnx.TensorProto
16 add = helper.make_node("Add", ["X", "Y"], ["O"])
17 graph = helper.make_graph(
18 [add],
19 "test",
20 [
21 helper.make_tensor_value_info("X", TensorProto.FLOAT, (4, 2)),
22 helper.make_tensor_value_info("Y", TensorProto.FLOAT, (4, 2)),
23 ],
24 [helper.make_tensor_value_info("O", TensorProto.FLOAT, (4, 2))],
25 )
26 opset_imports = [helper.make_opsetid("", 11)]
27 original_model = helper.make_model(graph, opset_imports=opset_imports)
28 return original_model
29
30
31def compile(model: onnx.ModelProto):
32 """Compile ONNX to PopEF."""
33 model_bytes = model.SerializeToString()
34 outputs = [o.name for o in model.graph.output]
35 executable = Compiler.compile(model_bytes, outputs)
36 return executable
37
38
39def run(executable):
40 """Run PopEF."""
41 config = RuntimeConfig()
42 config.timeout_ns = 300 * 1000 # 300us
43 config.batching_dim = 0
44 model_runner = runtime.Runner(executable, config)
45 batch_sizes = [1, 4, 7]
46 for batch_size in batch_sizes:
47 inputs = {}
48 inputs['X'] = np.random.uniform(0, 1, [batch_size, 2]).astype(np.float32)
49 inputs['Y'] = np.random.uniform(0, 1, [batch_size, 2]).astype(np.float32)
50
51 outputs = {}
52 outputs['O'] = np.zeros([batch_size, 2], dtype=np.float32)
53 model_runner.execute(inputs, outputs)
54 expected = inputs['X'] + inputs['Y']
55 npt.assert_array_equal(
56 outputs['O'],
57 expected,
58 f"Result: outputs['O'] not equal with expected: {expected}",
59 )
60 print(f'Successfully run with input data in batch size {batch_size}')
61
62
63if __name__ == '__main__':
64 model = default_model()
65 executable = compile(model)
66 run(executable)
Download dynamic_batch_size.py
When the example has run, you should see the following output:
Successfully run with input data in batch size 1
Successfully run with input data in batch size 4
Successfully run with input data in batch size 7