5.5. Packing
5.5.1. Background
Currently, the IPU only supports static graphs. The input shape of the model needs to be fixed, since the dynamic shape will cause the model to recompile. However, in practical applications, especially those in natural language processing, the input sequence length of the model is often dynamic. In this case, the conventional processing method is to pad the variable length data to the max sequence length and then input it into the model. However, this method will lead to a lot of invalid computing, resulting in a low utilisation rate of the IPU. In this case, you can use packing to support dynamic sequence length and improve IPU utilisation.
5.5.2. Packing and unpacking
Fig. 5.6 shows an example to illustrate packing and unpacking. Assume that the maximum input length of the model is 8 and the batch size is 4. Currently, there are 7 requests of batch size 1 of different lengths. The length ranges from 1 to 7, and 0 indicates that the pad has invalid data.
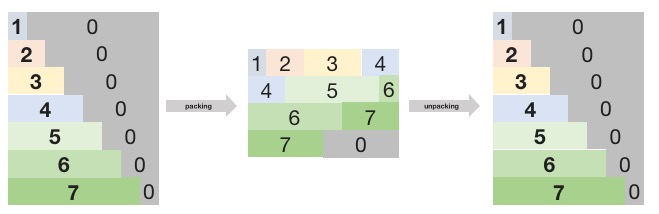
Fig. 5.6 Packing and unpacking
5.5.3. Transformer-based NLP models
Since its introduction in 2017, the application fields of transformer structures have grown considerably, from NLP in the beginning to ASR, CV, DLRM and other fields today. Transformers contain encoders and decoders. This section only focuses on encoders. The structure of a transformer encoder is shown in Fig. 5.7.
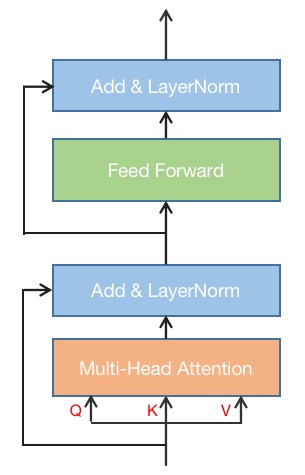
Fig. 5.7 Transformer encoder
Taking BERT as an example, the input shape of the encoder is usually [batch_size, seq_len, hidden_size]. In the encoder, except for the Multi-head Attention module, the computing of other modules is only performed in the last dimension. Therefore, for these modules, packing can be used to reduce invalid computing. For the Multi-head Attention module, since the correlation between tokens needs to be computed, the computing must be performed after unpacking without modifying the mask. Then, re-packing after the computing of Multi-head Attention is completed. The computing process can be represented by the following pseudocode:
packed_input from host
activation = packed_input
for encoer in encoders:
Unpacking
Attention
Packing
Add & LayerNorm
Feed-Forward
Add & LayerNorm
Update activation
Unpacking
unpacked_output to host
5.5.4. How to use packing
This section takes the Bert-Base-Squad model as an example. To run this example, you will need Ubuntu 20.04 and Python 3.8.15.
The complete code for this example is:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import argparse
3import csv
4import os
5import queue
6import random
7import sys
8import tempfile
9import threading
10import time
11
12from multiprocessing.pool import ThreadPool
13from queue import Queue
14
15import numpy as np
16import packing_utils
17
18from sklearn.metrics import mean_absolute_error
19
20from poprt import runtime
21from poprt.backend import get_session
22
23np.random.seed(2023)
24INPUT_IDS = "input_ids"
25POSITION_IDS = "position_ids"
26ATTENTION_MASK = "attention_mask"
27TOKEN_TYPE_IDS = "token_type_ids"
28UNPACK_INFO = "unpack_info"
29OUTPUT2 = "start_logits"
30OUTPUT1 = "end_logits"
31
32
33class BertInputs(object):
34 def __init__(
35 self,
36 input_ids,
37 attention_mask,
38 token_type_ids,
39 position_ids,
40 unpack_info,
41 input_len,
42 ):
43 self.input_ids = input_ids
44 self.attention_mask = attention_mask
45 self.token_type_ids = token_type_ids
46 self.position_ids = position_ids
47 self.input_len = input_len
48 self.unpack_info = unpack_info
49
50
51def get_synthetic_data(args):
52 input_len = np.random.normal(
53 args.avg_seq_len, args.avg_seq_len, size=args.dataset_size
54 ).astype(np.int32)
55 input_len = np.clip(input_len, 1, args.max_seq_len)
56
57 datasets = []
58 for s_len in input_len:
59 input_ids = np.random.randint(0, args.emb_size, (s_len)).astype(np.int32)
60
61 attention_mask = np.ones(s_len).astype(np.int32)
62 token_type_ids = np.random.randint(0, 2, (s_len)).astype(np.int32)
63
64 position_ids = np.arange(s_len).astype(np.int32)
65 unpack_info = np.zeros(args.max_valid_num).astype(np.int32)
66
67 feature = BertInputs(
68 input_ids, attention_mask, token_type_ids, position_ids, unpack_info, s_len
69 )
70 datasets.append(feature)
71
72 return datasets
73
74
75def dump_results(model_name, results):
76 fieldnames = [OUTPUT1, OUTPUT2]
77 filename = os.path.basename(model_name)[:-4] + 'csv'
78 with open(filename, 'w') as f:
79 writer = csv.DictWriter(f, fieldnames=fieldnames)
80 for result in results:
81 dict_name2list = {
82 OUTPUT1: result[OUTPUT1],
83 OUTPUT2: result[OUTPUT2],
84 }
85 writer.writerow(dict_name2list)
86
87
88## create batched inputs and pad samples to max_seq_len
89def padding_data(datasets, index, args):
90 feed_dicts = {}
91 feed_dicts[INPUT_IDS] = np.zeros(
92 (args.batch_size, args.max_seq_len), dtype=np.int32
93 )
94 feed_dicts[ATTENTION_MASK] = np.zeros(
95 (args.batch_size, args.max_seq_len), dtype=np.int32
96 )
97 feed_dicts[POSITION_IDS] = np.zeros(
98 (args.batch_size, args.max_seq_len), dtype=np.int32
99 )
100 feed_dicts[TOKEN_TYPE_IDS] = np.zeros(
101 (args.batch_size, args.max_seq_len), dtype=np.int32
102 )
103
104 for i in range(args.batch_size):
105 input_len = datasets[index].input_len
106 feed_dicts[INPUT_IDS][i][:input_len] = datasets[index].input_ids
107 feed_dicts[ATTENTION_MASK][i][:input_len] = datasets[index].attention_mask
108 feed_dicts[POSITION_IDS][i][:input_len] = datasets[index].position_ids
109 feed_dicts[TOKEN_TYPE_IDS][i][:input_len] = datasets[index].token_type_ids
110 index = index + 1
111 return feed_dicts
112
113
114# online pack, samples feeded to IPU can reach to maximum num of batches in each running turn
115def run_packing_model_with_pack_runner_unpack_repack(args, datasets):
116 tmpdir = tempfile.TemporaryDirectory()
117 # export popef for PackRunner
118 get_session(
119 args.model_with_packing_unpack_repack,
120 1,
121 "poprt",
122 output_dir=tmpdir.name,
123 export_popef=True,
124 ).load()
125 config = runtime.PackRunnerConfig(
126 timeout_microseconds=args.timeout_microseconds,
127 # max_valid_num=args.max_valid_num,
128 # dynamic_input_name=args.dynamic_input_name,
129 )
130
131 popef_path = tmpdir.name + '/executable.popef'
132 # popef_path = "/popconverter/examples/packed_bert_example/executable.popef"
133 pack_runner = runtime.Runner(popef_path, config)
134
135 result_queue = queue.Queue()
136 results = []
137 start_time = time.time()
138 for i in range(args.dataset_size):
139 feed_dicts = {
140 INPUT_IDS: datasets[i].input_ids,
141 ATTENTION_MASK: datasets[i].attention_mask,
142 TOKEN_TYPE_IDS: datasets[i].token_type_ids,
143 POSITION_IDS: datasets[i].position_ids,
144 # unpack_info should be hidden from user in the future
145 UNPACK_INFO: np.zeros(args.max_valid_num).astype(np.int32),
146 }
147 out_dict = {
148 OUTPUT1: np.zeros([args.max_seq_len]).astype(np.float16),
149 OUTPUT2: np.zeros([args.max_seq_len]).astype(np.float16),
150 }
151 future = pack_runner.execute_async(feed_dicts, out_dict)
152 result_queue.put((future, out_dict))
153 result_queue.put((None, None))
154 while True:
155 future, out_dict = result_queue.get()
156 if future == None:
157 break
158 future.wait()
159 results.append(out_dict)
160 end_time = time.time()
161
162 tput = args.dataset_size / (end_time - start_time)
163 latency_ms = (end_time - start_time) / args.dataset_size
164 print(
165 f"[Pack Online Unpack Repack] Throughput: {tput} samples/s, Latency : {latency_ms * 1000} ms"
166 )
167
168 if args.dump_results:
169 dump_results(
170 "online_unpack_repack" + args.model_with_packing_unpack_repack, results
171 )
172
173 tmpdir.cleanup()
174 return results
175
176
177# offline pack, samples feeded to IPU can reach to maximum num of batches in each running turn
178# model with pack / unpack ops
179def run_packing_model_with_model_runner(args, datasets, model_path, across_rows):
180 run_queue = queue.Queue()
181 start_time = time.time()
182 index = 0
183 for i in range(0, args.dataset_size):
184 transfer = packing_utils.pack_data(
185 datasets,
186 index,
187 args.batch_size,
188 seq_len=256,
189 max_valid_num=args.max_valid_num,
190 segment_num=1,
191 across_rows=across_rows,
192 )
193
194 run_queue.put(transfer)
195 index = transfer.count
196 if index == args.dataset_size:
197 break
198 run_queue.put(None)
199 duration_of_packing = time.time() - start_time
200 mean_latency_of_padding_us = duration_of_packing * 1e6 / args.dataset_size
201
202 print(f"Mean latency of packing data: {mean_latency_of_padding_us} us/sam")
203 print(f"Total latency of packing data: {duration_of_packing} s")
204
205 sess = get_session(model_path, 1, "poprt").load()
206
207 pool = ThreadPool(processes=1)
208
209 def execute(feed_dicts, valid_num):
210 outputs = sess.run([OUTPUT1, OUTPUT2], feed_dicts)
211 res = []
212 if across_rows:
213 for i in range(valid_num):
214 res1 = outputs[0][i].copy().tolist()
215 res2 = outputs[1][i].copy().tolist()
216 res.append({OUTPUT1: res1, OUTPUT2: res2})
217 else:
218 outlen = len(outputs[0][0])
219 for index in range(len(feed_dicts[ATTENTION_MASK])):
220 start = 0
221 arr = np.array(feed_dicts[ATTENTION_MASK][index])
222 while start < outlen and arr[start] > 0:
223 arr = arr - 1
224 zero_num = len(arr) - np.count_nonzero(arr)
225 out1 = [0] * outlen
226 out2 = [0] * outlen
227 out1[:zero_num] = outputs[0][index][start : start + zero_num]
228 out2[:zero_num] = outputs[1][index][start : start + zero_num]
229 res.append({OUTPUT1: out1, OUTPUT2: out2})
230 start += zero_num
231 return res
232
233 asy_results = []
234
235 total_start_time = time.time()
236 while True:
237 input_data = run_queue.get()
238 if input_data is None:
239 break
240
241 feed_dicts = {
242 INPUT_IDS: input_data.data[INPUT_IDS],
243 ATTENTION_MASK: input_data.data[ATTENTION_MASK],
244 TOKEN_TYPE_IDS: input_data.data[TOKEN_TYPE_IDS],
245 POSITION_IDS: input_data.data[POSITION_IDS],
246 # unpack_info should be hidden from user in the future
247 UNPACK_INFO: input_data.unpack_info,
248 }
249 if not across_rows:
250 feed_dicts.pop(UNPACK_INFO)
251
252 valid_num = len(input_data.specs)
253 async_result = pool.apply_async(execute, (feed_dicts, valid_num))
254 asy_results.append(async_result)
255
256 results = []
257 for asy in asy_results:
258 for res in asy.get():
259 results.append(res)
260 total_end_time = time.time()
261
262 tput = len(results) / (total_end_time - total_start_time)
263 latency = (total_end_time - total_start_time) / len(results)
264 if across_rows:
265 print(
266 f"[Pack Offline Unpack Repack] Throughput: {tput} samples/s, Latency: {latency*1000} ms"
267 )
268 else:
269 print(
270 f"[Pack Offline AttentionMask] Throughput: {tput} samples/s, Latency: {latency*1000} ms"
271 )
272
273 if args.dump_results:
274 dump_results("offline_" + model_path, results)
275
276 return results
277
278
279# online pack, samples feeded to IPU can reach to maximum num of batches in each running turn
280# model only add AttentionMask op in this mode
281def run_packing_model_with_pack_runner_attention_mask(args, datasets, algo):
282 tmpdir = tempfile.TemporaryDirectory()
283 # export popef for PackRunner
284 get_session(
285 args.model_with_packing_attention_mask,
286 1,
287 "poprt",
288 output_dir=tmpdir.name,
289 export_popef=True,
290 ).load()
291 config = runtime.PackRunnerConfig(
292 timeout_microseconds=args.timeout_microseconds,
293 max_valid_num=args.max_valid_num,
294 dynamic_input_name=args.dynamic_input_name,
295 )
296
297 if algo == "next_fit":
298 config.algorithm = runtime.PackAlgorithm.next_fit
299 else:
300 config.algorithm = runtime.PackAlgorithm.first_fit
301
302 config.enable_input_single_row_mode("attention_mask")
303 popef_path = tmpdir.name + '/executable.popef'
304 # popef_path = "/popconverter/examples/packed_bert_example/executable.popef"
305 pack_runner = runtime.Runner(popef_path, config)
306
307 result_queue = queue.Queue()
308 results = []
309 start_time = time.time()
310 for i in range(args.dataset_size):
311 feed_dicts = {
312 INPUT_IDS: datasets[i].input_ids,
313 ATTENTION_MASK: datasets[i].attention_mask,
314 TOKEN_TYPE_IDS: datasets[i].token_type_ids,
315 POSITION_IDS: datasets[i].position_ids,
316 }
317 out_dict = {
318 OUTPUT1: np.zeros([args.max_seq_len]).astype(np.float16),
319 OUTPUT2: np.zeros([args.max_seq_len]).astype(np.float16),
320 }
321 future = pack_runner.execute_async(feed_dicts, out_dict)
322 result_queue.put((future, out_dict))
323 result_queue.put((None, None))
324 while True:
325 future, out_dict = result_queue.get()
326 if future == None:
327 break
328 future.wait()
329 results.append(out_dict)
330 end_time = time.time()
331
332 tput = args.dataset_size / (end_time - start_time)
333 latency_ms = (end_time - start_time) / args.dataset_size
334 print(
335 f"[Pack Online AttentionMask({algo})] Throughput: {tput} samples/s, Latency : {latency_ms * 1000} ms"
336 )
337
338 if args.dump_results:
339 dump_results(
340 "online_attention_mask_"
341 + algo
342 + "_"
343 + args.model_with_packing_attention_mask,
344 results,
345 )
346
347 tmpdir.cleanup()
348 return results
349
350
351def latency_distribuion_with_pack_runner_attention_mask(args, datasets, algo):
352 tmpdir = tempfile.TemporaryDirectory()
353 # export popef for PackRunner
354 get_session(
355 args.model_with_packing_attention_mask,
356 1,
357 "poprt",
358 output_dir=tmpdir.name,
359 export_popef=True,
360 ).load()
361 config = runtime.PackRunnerConfig(
362 timeout_microseconds=args.timeout_microseconds,
363 max_valid_num=args.max_valid_num,
364 dynamic_input_name=args.dynamic_input_name,
365 )
366
367 if algo == "next_fit":
368 config.algorithm = runtime.PackAlgorithm.next_fit
369 else:
370 config.algorithm = runtime.PackAlgorithm.first_fit
371
372 config.enable_input_single_row_mode("attention_mask")
373 popef_path = tmpdir.name + '/executable.popef'
374 # popef_path = "/popconverter/examples/packed_bert_example/executable.popef"
375 pack_runner = runtime.Runner(popef_path, config)
376
377 sample_num = args.batch_size * args.iterations
378 clients = int(args.batch_size * 3.5)
379 count_percent = 0.6
380
381 q = Queue()
382
383 def perf_count(model_runner, iteration):
384 durations = []
385 for i in range(sample_num):
386 start_time = time.time()
387 random.randint(0, sample_num)
388 feed_dicts = {
389 INPUT_IDS: datasets[i].input_ids,
390 ATTENTION_MASK: datasets[i].attention_mask,
391 TOKEN_TYPE_IDS: datasets[i].token_type_ids,
392 }
393 out_dict = {
394 OUTPUT1: np.zeros([args.max_seq_len]).astype(np.float16),
395 OUTPUT2: np.zeros([args.max_seq_len]).astype(np.float16),
396 }
397 pack_runner.execute(feed_dicts, out_dict)
398 end_time = time.time()
399 durations.append((start_time, end_time))
400 # remove first and last example's time counter
401 ignored_samples = int(sample_num * (1 - count_percent) / 2)
402 durations = durations[ignored_samples:-ignored_samples]
403 q.put(durations, timeout=10)
404
405 thp = [
406 threading.Thread(target=perf_count, args=(pack_runner, args.iterations))
407 for _ in range(clients)
408 ]
409 for t in thp:
410 t.start()
411 for t in thp:
412 t.join()
413
414 durations_from_th = []
415 while not q.empty():
416 durations_from_th += q.get()
417 max_timestamp = max(y for _, y in durations_from_th)
418 min_timestamp = min(x for x, _ in durations_from_th)
419 clients * (sample_num * count_percent) / (max_timestamp - min_timestamp)
420 times_range = [y - x for x, y in durations_from_th]
421
422 times_range.sort()
423 tail_latency = round(times_range[int(len(times_range) * 0.99)] * 1000, 2)
424 avg_latency = round(sum(times_range) / len(times_range) * 1000, 2)
425
426 print(f"Average Latency: {avg_latency}ms, P99 latency: {tail_latency}ms.")
427 return tail_latency, avg_latency
428
429
430# no pack, padding each line with 0 if input length is not long enough.
431# samples num equals to batch at every running turn
432def run_original_model_with_model_runner(args, datasets):
433 run_queue = queue.Queue()
434 start_time = time.time()
435 for i in range(0, args.dataset_size, args.batch_size):
436 feed_dicts = padding_data(datasets, i, args)
437 run_queue.put((args.batch_size, feed_dicts))
438 run_queue.put((0, None))
439 duration_of_padding_s = time.time() - start_time
440
441 mean_latency_of_padding_us = duration_of_padding_s * 1e6 / args.dataset_size
442 print(f"Mean latency of padding data: {mean_latency_of_padding_us} us/sam")
443 print(f"Total latency of padding data: {duration_of_padding_s} s")
444
445 sess = get_session(args.model_without_packing, 1, "poprt").load()
446
447 asy_results = []
448
449 def execute(feed_dicts, valid_num):
450 outputs = sess.run([OUTPUT1, OUTPUT2], feed_dicts)
451 res = []
452 for i in range(valid_num):
453 res1 = outputs[0][i].copy().tolist()
454 res2 = outputs[1][i].copy().tolist()
455 res.append({OUTPUT1: res1, OUTPUT2: res2})
456 return res
457
458 # execute
459 pool = ThreadPool(processes=1)
460 total_start_time = time.time()
461 while True:
462 valid_num, feed_dicts = run_queue.get()
463 if feed_dicts is None:
464 break
465 async_result = pool.apply_async(execute, (feed_dicts, valid_num))
466 asy_results.append(async_result)
467 results = []
468 for asy in asy_results:
469 for res in asy.get():
470 results.append(res)
471 total_end_time = time.time()
472
473 tput = len(results) / (total_end_time - total_start_time)
474 latency = (total_end_time - total_start_time) / len(results)
475
476 if args.dump_results:
477 dump_results("original_" + args.model_without_packing, results)
478
479 print(f"[Original] Throughput: {tput} samples/s, Latency: {latency *1000} ms")
480
481 return results
482
483
484def calculate_mae(expected_results, output_results, datasets, enable_debug):
485 assert len(datasets) == len(expected_results)
486 assert len(datasets) == len(output_results)
487 maes = []
488 zipped_data = zip(datasets, expected_results, output_results)
489 for i, (data, expected, output) in enumerate(zipped_data):
490 np.testing.assert_equal(len(expected), len(output))
491 input_len = data.input_len
492 output_1_mae = mean_absolute_error(
493 expected[OUTPUT1][:input_len], output[OUTPUT1][:input_len]
494 )
495 output_2_mae = mean_absolute_error(
496 expected[OUTPUT2][:input_len], output[OUTPUT2][:input_len]
497 )
498 maes.append([i, output_1_mae, output_2_mae])
499
500 k = 10 if len(datasets) > 10 else len(datasets)
501
502 def print_topk(k, out_name, out_index):
503 for i in range(1, k + 1):
504 print(f"Sample: {maes[-i][0]}, {out_name} mae : {maes[-i][out_index]}")
505
506 if enable_debug:
507 maes.sort(key=lambda e: e[1])
508 print(f"\n***** Top {k} mae of output: {OUTPUT1} *****")
509 print_topk(k, OUTPUT1, 1)
510
511 maes.sort(key=lambda e: e[2])
512 print(f"\n***** Top {k} mae of output: {OUTPUT2} *****")
513 print_topk(k, OUTPUT2, 2)
514
515 print(f"{OUTPUT1} average mae: {np.mean(maes,axis=0)[1]}")
516 print(f"{OUTPUT2} average mae: {np.mean(maes,axis=0)[2]}")
517
518
519def main():
520 parser = argparse.ArgumentParser(description='packed bert-base-squad')
521 parser.add_argument(
522 '--avg_seq_len', type=int, default=128, help='average sequence length of input'
523 )
524 parser.add_argument(
525 '--batch_size', type=int, default=16, help='batch size of model'
526 )
527 parser.add_argument('--dump_results', action='store_true', help='dump results')
528 parser.add_argument(
529 '--dynamic_input_name', type=str, default=INPUT_IDS, help='dynamic input name'
530 )
531 parser.add_argument(
532 '--emb_size', type=int, default=30522, help='word embedding table size'
533 )
534 parser.add_argument(
535 '--enable_debug', action='store_true', help='enable output debug info'
536 )
537 parser.add_argument(
538 '--iterations', type=int, default=100, help='number of batches to run'
539 )
540 parser.add_argument(
541 '--max_seq_len', type=int, default=256, help='max sequence length of input'
542 )
543 parser.add_argument(
544 '--max_valid_num', type=int, default=40, help='max valid num for pack'
545 )
546 parser.add_argument(
547 '--model_without_packing', help='model without pack, unpack, repack op'
548 )
549 parser.add_argument(
550 '--model_with_packing_unpack_repack',
551 help='model with pack, unpack, repack op converted by PopRT',
552 )
553 parser.add_argument(
554 '--model_with_packing_attention_mask',
555 help='model with AttentionMask op converted by PopRT',
556 )
557 parser.add_argument(
558 '--timeout_microseconds',
559 type=int,
560 default=15000,
561 help='timeout in microseconds',
562 )
563
564 args = parser.parse_args()
565 args.dataset_size = args.iterations * args.batch_size
566
567 # generate synthetic dataset
568 datasets = get_synthetic_data(args)
569 original_result = run_original_model_with_model_runner(args, datasets)
570
571 offline_pack_result_unpack_repack = run_packing_model_with_model_runner(
572 args, datasets, args.model_with_packing_unpack_repack, True
573 )
574 online_pack_result_unpack_repack = run_packing_model_with_pack_runner_unpack_repack(
575 args, datasets
576 )
577
578 offline_pack_result_attention_mask = run_packing_model_with_model_runner(
579 args, datasets, args.model_with_packing_attention_mask, False
580 )
581 online_pack_result_attention_mask_first_fit = (
582 run_packing_model_with_pack_runner_attention_mask(args, datasets, "first_fit")
583 )
584 online_pack_result_attention_mask_next_fit = (
585 run_packing_model_with_pack_runner_attention_mask(args, datasets, "next_fit")
586 )
587 latency_distribuion_with_pack_runner_attention_mask(args, datasets, "first_fit")
588
589 # compare the results
590 print("\nCompare results between original and online pack(with unpack repack)")
591 calculate_mae(
592 original_result, online_pack_result_unpack_repack, datasets, args.enable_debug
593 )
594 print("\nCompare results between offline and online pack with unpack repack op")
595 calculate_mae(
596 offline_pack_result_unpack_repack,
597 online_pack_result_unpack_repack,
598 datasets,
599 args.enable_debug,
600 )
601
602 print(
603 "\nCompare results between original and online_first_fit pack with attention_mask op"
604 )
605 calculate_mae(
606 original_result,
607 online_pack_result_attention_mask_first_fit,
608 datasets,
609 args.enable_debug,
610 )
611 print(
612 "\nCompare results between original and online_next_fit pack with attention_mask op"
613 )
614 calculate_mae(
615 original_result,
616 online_pack_result_attention_mask_next_fit,
617 datasets,
618 args.enable_debug,
619 )
620
621 print(
622 "\nCompare results between offline and online_next_fit pack with attenttion_mask op"
623 )
624 calculate_mae(
625 offline_pack_result_attention_mask,
626 online_pack_result_attention_mask_next_fit,
627 datasets,
628 args.enable_debug,
629 )
630
631
632if __name__ == "__main__":
633 sys.exit(main())
Downloading the model
Before downloading the model, you need to install the dependencies:
pip install torch==1.10.0
pip install transformers[onnx]==4.25.1
Download the model:
python -m transformers.onnx --model=csarron/bert-base-uncased-squad-v1 . --feature question-answering
Converting the model
The downloaded model does not contain position_ids in the input. To use packing on the IPU, you need to pack the input on the host first.
Therefore, you need to add position_ids to the input of the model. The code is as follows:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import argparse
3import copy
4import os
5
6import onnx
7
8# Download model from huggingface
9# - python -m transformers.onnx --model=csarron/bert-base-uncased-squad-v1 . --feature question-answering
10# reference: https://huggingface.co/csarron/bert-base-uncased-squad-v1
11
12
13if __name__ == '__main__':
14 parser = argparse.ArgumentParser(description='Preprocess Bert-Squad Model')
15 parser.add_argument(
16 '--input_model', type=str, default='', help='path of input model'
17 )
18 args = parser.parse_args()
19
20 if not os.path.exists(args.input_model):
21 parser.print_usage()
22 raise FileNotFoundError(f'Unable to find model: {args.input_model}')
23
24 model = onnx.load(args.input_model)
25
26 # for packed bert, we need to export position_ids to model's input
27 # step 1: remove unneed node
28 rm_node_names = [
29 'Shape_7',
30 'Gather_9',
31 'Add_11',
32 'Unsqueeze_12',
33 'Slice_14',
34 'Constant_8',
35 'Constant_10',
36 'Constant_13',
37 ]
38 rm_nodes = []
39 for node in model.graph.node:
40 if node.name in rm_node_names:
41 rm_nodes.append(node)
42
43 assert len(rm_node_names) == len(rm_nodes)
44
45 for node in rm_nodes:
46 model.graph.node.remove(node)
47
48 # step 2: add position_ids to model's input
49 position_ids = copy.deepcopy(model.graph.input[0])
50 position_ids.name = 'position_ids'
51 model.graph.input.append(position_ids)
52
53 for node in model.graph.node:
54 if node.op_type == 'Gather' and node.name == 'Gather_18':
55 node.input[1] = position_ids.name
56
57 print(f'Save preprocessed model to bert_base_squad_pos.onnx')
58 onnx.save(model, 'bert_base_squad_pos.onnx')
To generate the model without packing, run:
poprt \
--input_model squad_bert_base_pos.onnx \
--output_model squad_bert_base_bs16_sl256.onnx \
--precision fp16 \
--input_shape input_ids=16,256 attention_mask=16,256 token_type_ids=16,256 position_ids=16,256
To generate model with packing, run:
poprt \
--input_model squad_bert_base_pos.onnx \
--output_model squad_bert_base_bs16_sl256_pack.onnx \
--precision fp16 \
--input_shape input_ids=16,256 attention_mask=16,256 token_type_ids=16,256 position_ids=16,256 \
--pack_args max_valid_num=40 segment_max_size=256
max_valid_num is used to specify the maximum batch size after unpacking, and segment_max_size indicates the maximum length.
Running the model
Run the model:
python packed_bert_example.py \
--model_with_packing squad_bert_base_bs16_sl256_pack.onnx \
--model_without_packing squad_bert_base_bs16_sl256.onnx
When the example has run, you should see the an output similar to the following:
[Original] Throughput: 1860.9792005501781 samples/s, Latency: 0.5373515188694 ms
....
[Pack Offline] Throughput: 2830.8140869025283 samples/s, Latency: 0.3532552719116211 ms
....
[Pack Online] Throughput: 2782.587696947809 samples/s, Latency : 0.3593777120113373 ms
....