1. Introduction
PopRT is a high-performance inference engine for the Graphcore IPU. It compiles and optimises models that have been trained and exported for inference, generating an executable program that can be run on IPUs.
PopRT generates the executable program as a PopEF model. The Poplar Exchange Format is a Graphcore file format that is mainly used for exporting and importing models. PopRT provides a flexible runtime to perform low-latency and high-throughput inference on PopEF models.
1.1. Background
The Graphcore Poplar SDK includes tools and libraries to support programming the IPU for various industry-standard machine learning frameworks such as TensorFlow, MXNET, ONNX, Keras, and PyTorch. The SDK packages need to balance functionality for both training and inference when performing optimisation. PopRT, on the other hand, is a specialised engine for inference that allows more targeted optimisation for inference scenarios.
The main functions of PopRT are to:
Convert an ONNX model to a lower precision (float16/float8)
Convert the opset version of the ONNX model
Apply various optimisations to the model, including general and IPU-specific optimisations
Provide a flexible runtime for inference using PopEF models.
1.2. Architecture
Fig. 1.1 shows the architecture of PopRT.
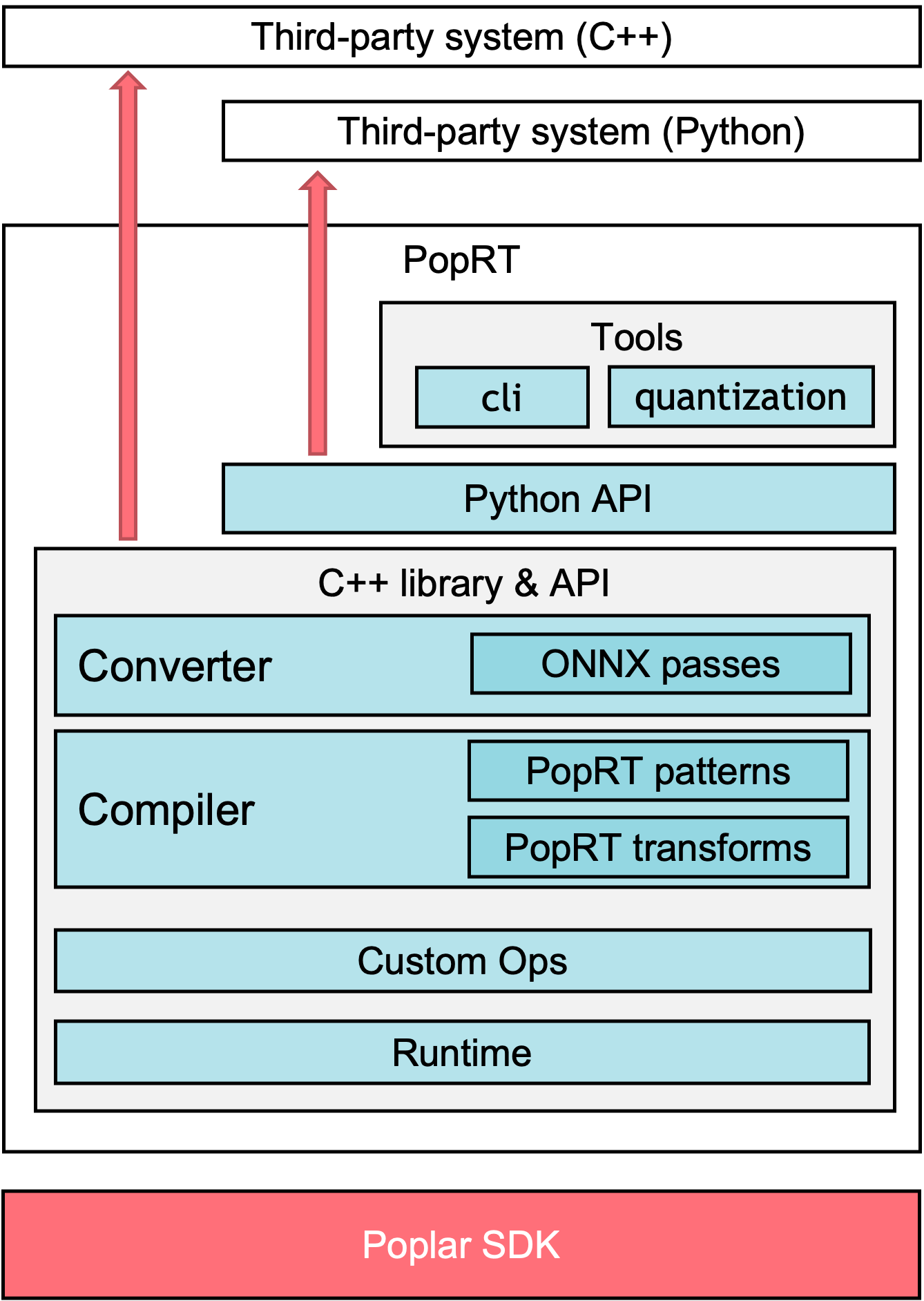
Fig. 1.1 PopRT architecture
The architecture of PopRT consists of three main parts:
Converter: A converter is responsible for optimising models exported from other frameworks. Converters are framework-specific and only the ONNX converter is currently supported.
Pass: Passes perform graph optimisation of the framework-specific model IR. Only the ONNX pass is currently supported.
Compiler: Optimises the PopART IR for inference and includes patterns and transforms. The serialisable binary PopEF model is generated after compilation.
Pattern: Matches and replaces operators.
Transform: Optimises overall graph.
Custom Ops: Additional custom operator libraries for inference scenarios.
Runtime: Loads PopEF model and performs low-latency and high-throughput inference.
Tools: Provides general tools, such as FP8 quantisation tools and command-line tools.
1.3. Workflow
The workflow of PopRT for converting, compiling and running models is shown in Fig. 1.2. PopRT provides command-line tools, a Python API and a C++ API.
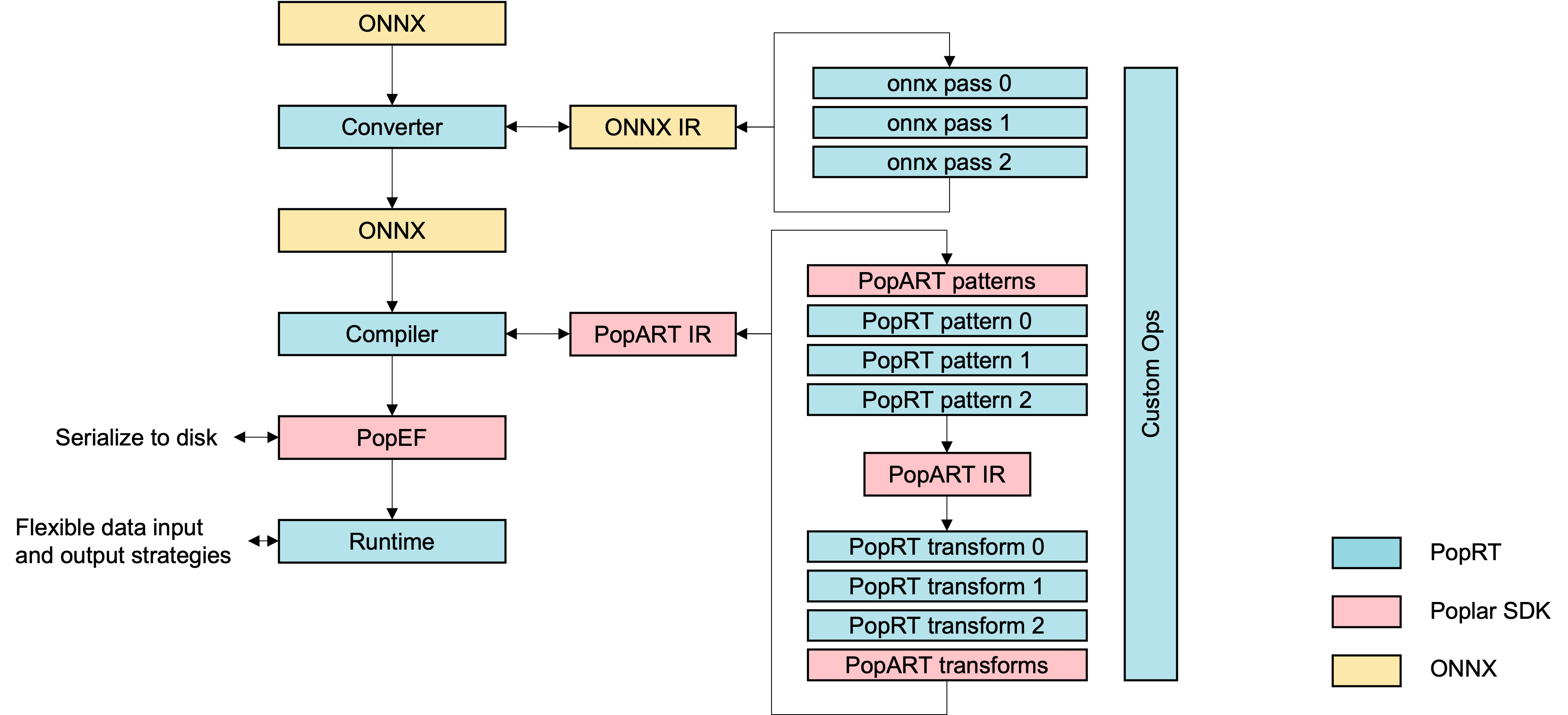
Fig. 1.2 PopRT workflow