Source (GitHub) | Download notebook
2.2. Efficient data loading with PopTorch
This tutorial will present how PopTorch can help to efficiently load data to your model and how to avoid common performance bottlenecks when passing data from the host to the IPU. It also covers the more general notion of data batching on IPUs which is also relevant to other frameworks.
Before starting this tutorial, we recommend that you read through our tutorial on the basics of PyTorch on the IPU and our MNIST starting tutorial.
Requirements:
A Poplar SDK environment enabled (see the Getting Started guide for your IPU system)
The PopTorch Python library installed (see Installation of the PopTorch User Guide)
To run the Jupyter notebook version of this tutorial:
Enable a Poplar SDK environment
In the same environment, install the Jupyter notebook server:
python -m pip install jupyterLaunch a Jupyter Server on a specific port:
jupyter-notebook --no-browser --port <port number>Connect via SSH to your remote machine, forwarding your chosen port:
ssh -NL <port number>:localhost:<port number> <your username>@<remote machine>
For more details about this process, or if you need troubleshooting, see our guide on using IPUs from Jupyter notebooks.
PyTorch and PopTorch DataLoader
If you are familiar with PyTorch you may have used torch.utils.data.DataLoader.
PopTorch provides its own
DataLoader
which is a wrapper around torch.utils.data.DataLoader. It accepts the same
arguments as PyTorch’s DataLoader with some extra features specific to the IPU:
It takes a
poptorch.Optionsinstance to use IPU-specific features;It automatically computes the number of elements consumed by one step;
It enables asynchronous data loading.
See the documentation for more information about asynchronous mode.
Note: When executing code from this tutorial in a Python script, it requires this conditional block:
if __name__ == '__main__':This is necessary to avoid issues with asynchronous DataLoader. The asynchronous dataloader calls the spawn method, which creates a new Python interpreter. This interpreter will import the main module of the application. Therefore, we need protection against infinite spawning of new processes and repeated, undesirable code invocations and so the entire executable part of the script should be in an
ifblock. Function and class definitions do not have to be in this block. This change does not apply to interactive Python Interpreters (for example Jupyter notebooks) which support multiprocessing in a different way.
Note: The dataset must be serializable by pickle.
Let’s reuse the model from the introductory tutorial on PopTorch and make a random dataset to experiment with the different IPU parameters.
We will start by importing the necessary libraries:
import time
from sys import exit
import poptorch
import torch
import torch.nn as nn
import os
executable_cache_dir = os.getenv("POPLAR_EXECUTABLE_CACHE_DIR", "/tmp/exe_cache/")
Now we will define some global variables that are used later. If you change any of these values then you should re-run all the cells below:
device_iterations = 50
batch_size = 16
replicas = 1
num_workers = 4
Let’s create the model:
class ClassificationModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 5, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(5, 12, 5)
self.norm = nn.GroupNorm(3, 12)
self.fc1 = nn.Linear(41772, 100)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(100, 10)
self.log_softmax = nn.LogSoftmax(dim=0)
self.loss = nn.NLLLoss()
def forward(self, x, labels=None):
x = self.pool(self.relu(self.conv1(x)))
x = self.norm(self.relu(self.conv2(x)))
x = torch.flatten(x, start_dim=1)
x = self.relu(self.fc1(x))
x = self.log_softmax(self.fc2(x))
if self.training:
return x, self.loss(x, labels)
return x
opts = poptorch.Options()
opts.deviceIterations(device_iterations)
opts.replicationFactor(replicas)
model = ClassificationModel()
model.train() # Switch the model to training mode
# Models are initialised in training mode by default, so the line above will
# have no effect. Its purpose is to show how the mode can be set explicitly.
training_model = poptorch.trainingModel(
model, opts, torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
)
Now we will create a sample random dataset, which we will later use to calculate processing time.
features = torch.randn([10000, 1, 128, 128])
labels = torch.empty([10000], dtype=torch.long).random_(10)
dataset = torch.utils.data.TensorDataset(features, labels)
In the tutorial on basics we used images from the MNIST dataset
with a size of 28x28, now we will use larger images (128x128) to simulate a
heavier data load. This change increases the input size of the layer fc1 from
self.fc1 = nn.Linear(972, 100) to self.fc1 = nn.Linear(41772, 100).
Let’s set up a PopTorch DataLoader in asynchronous mode:
training_data = poptorch.DataLoader(
opts,
dataset=dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=num_workers,
mode=poptorch.DataLoaderMode.Async,
)
The asynchronous mode of poptorch.DataLoader performs the data loading
on separate processes. This allows the data to be preprocessed asynchronously
on the CPU to minimize CPU/IPU transfer time.
Understanding batching with IPU
When developing a model for the IPU, you will encounter different notions of batching including mini-batches, replica batches and global batches. This section will explain how these hyperparameters are related to the IPU and how to compute the number of samples the DataLoader is going to fetch for one step.
Device iterations
This diagram represents a basic execution on 1 IPU with n device iterations and 1 mini-batch used per iteration.
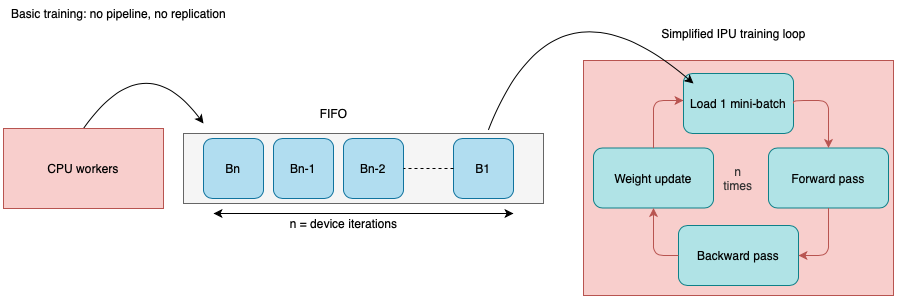
A device iteration corresponds to one iteration of the training loop executed
on the IPU, starting with data-loading and ending with a weight update.
In this simple case, when we set n deviceIterations, the host will
prepare n mini-batches in an infeed queue so the IPU can perform
efficiently n iterations.
From the host point of view, this will correspond to a single call to the model (1 step):
training_model(data, labels)
A note on returned data
The number of batches of data returned to the host depends on the option
poptorch.Options.outputMode. It defaults to Final for trainingModel and
All for inferenceModel. This is because you will usually want to receive
all the output tensors when you use a inferenceModel() while you will often
not need to receive all or any of the output tensors when you use a
trainingModel. See the
documentation
for more information about poptorch.Options.outputMode.
In this case presented above, we are using a trainingModel and
poptorch.Options.outputMode is therefore the default value Final. Since
poptorch.Options.replicationFactor defaults to 1, the number of data elements
returned to the host will just be 16, which is the batch size. The tensor shape
will then be (16, 1, 128, 128).
Gradient accumulation
This parameter must be used with pipelining. A pipelined model consists in splitting the graph into different successive computation stages. Every stage of a pipelined model can be placed on a different IPU, they all compute specific parts of the graph with their own weights. Each stage will compute the forward and backward pass of a mini-batch.
In the image below, we can see a 4 stage pipeline where 8 mini-batches
(B1-B8) are being processed:
An
fsuffix indicates a forward pass;A
bsuffix indicates a backward pass.
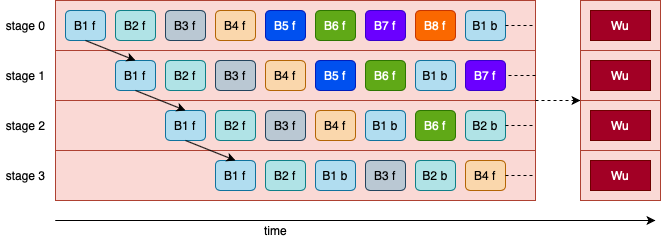
When we set up a pipelined execution, we overcome the cost of having multiple stages by computing several batches in parallel when the pipeline is full.
Every pipeline stage needs to update its weights when the gradients are ready.
However, it would be very inefficient to update them after each mini-batch
completion. The solution is the following:
After each backward pass the gradients are accumulated together for K
mini-batches. Then, the accumulators are used to update the stage weights.
This is gradient accumulation. This value can be set in PopTorch via the
option opts.Training.gradientAccumulation(K)
In the previous part, we only had 1 mini-batch per weight update. This time we have K mini-batches per weight update.
Then, for one device iteration with pipeline we have multiplied the number of samples processed by K.
More information about gradient accumulation can be found in the PopTorch User Guide.
Replication
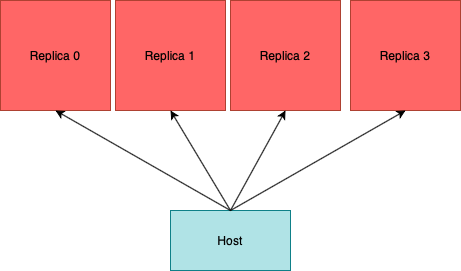
Replication describes the process of running multiple instances of the same model simultaneously on different IPUs to achieve data parallelism. This can give large improvements in throughput, as the training data is processed in parallel.
In a single device iteration, many mini-batches may be processed and the resulting gradients accumulated. We call this total number of samples processed for one optimiser step the global batch size.
If the model requires N IPUs and the replication factor is M, N x M IPUs will be necessary, but for one device iteration we have increased by M the number of mini-batches processed.
The PopTorch Dataloader will ensure that the host is sending each replica a different subset of the dataset.
Global batch size
Because several mini-batches can be processed by one device iteration (that is, for one weight update), we call global batch size this total number of samples:
Mini-batch size (sometimes called micro-batch)
The number of samples processed by one simple fwd/bwd pass.
Replica batch size
The number of samples on a single replica process before weight update Replica batch size = Mini-batch size x Gradient accumulation factor
Global batch size
The number of samples used for the weight update Global batch size = Replica batch size x Number of replicas Global batch size = (Mini-batch size x Gradient accumulation factor) x Number of replicas
How many samples will then be loaded in one step?
Considering you are iterating through the PopTorch DataLoader:
for data, labels in training_data:
training_model(data, labels)
For each step, the number of samples contained in data and labels will be:
N = Global batch size x Device iterations
Tuning hyperparameters
Evaluating the asynchronous DataLoader
How can we make sure the DataLoader is not a bottleneck for our model throughput? In this tutorial we made an example benchmark to answer this question:
As we will often measure time we will prepare a context manager which will capture the elapsed time of a code block:
class catchtime:
def __enter__(self):
self.seconds = time.time()
return self
def __exit__(self, type, value, traceback):
self.seconds = time.time() - self.seconds
Evaluate the asynchronous DataLoader throughput without the IPU.
We just loop through the DataLoader without running the model so we can estimate its maximum throughput.
steps = len(training_data)
with catchtime() as t:
for i, (data, labels) in enumerate(training_data):
a, b = data, labels
print(f"Total execution time: {t.seconds:.2f} s")
items_per_second = (steps * device_iterations * batch_size * replicas) / t.seconds
print(f"DataLoader throughput: {items_per_second:.2f} items/s")
training_data.terminate()
Total execution time: 0.14 s
DataLoader throughput: 68227.22 items/s
Note about releasing resources:
In the Jupyter environment, we have to manually detach from IPU devices and terminate worker threads of the asynchronous data loader. Workers must be manually terminated because we use the asynchronous data loader (
DataLoaderMode.Async) with a number of data samples not exactly divisible by the total of batch size multiplied by device count. This mismatch leaves some workers waiting to provide data which might not be needed with the training epoch ending before all samples are exhausted. In a production model, running from Python, this should not be necessary.
Evaluate the IPU throughput with synthetic data. To do so we will evaluate the model with synthetic data generated by the IPU. Create a new
poptorch.Options()structure, this time specifyingenableSyntheticData(True):
opts = poptorch.Options()
opts.deviceIterations(device_iterations)
opts.replicationFactor(replicas)
opts.enableSyntheticData(True)
opts.enableExecutableCaching(executable_cache_dir)
When using synthetic data, no data is copied onto the device. Hence, the throughput measured will be the upper bound of IPU/model performance.
Provided that the asynchronous DataLoader throughput is greater or equal than this upper bound, the host-side data loading will not be a bottleneck. Else, there is a risk that the DataLoader throughput is limiting performance of the model.
Note that this is only true if you’re using an asynchronous DataLoader, the synchronous one can still slow down the overall execution as it will be run serially.
Note for IPU benchmarking:
The warmup time can be avoided by calling
training_model.compile(data, labels)before any other call to the model. If not, the first call will include the compilation time, which can take few minutes.# Warmup print("Compiling + Warmup ...") training_model.compile(data, labels)
model = ClassificationModel()
training_model = poptorch.trainingModel(
model,
opts,
poptorch.optim.SGD(
model.parameters(), lr=0.001, momentum=0.9, use_combined_accum=False
),
)
training_data = poptorch.DataLoader(
opts,
dataset=dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=num_workers,
mode=poptorch.DataLoaderMode.Async,
async_options={"early_preload": True},
)
steps = len(training_data)
data_batch, labels_batch = next(iter(training_data))
training_model.compile(data_batch, labels_batch)
print(f"Evaluating: {steps} steps of {device_iterations * batch_size * replicas} items")
# With synthetic data enabled, no data is copied from the host to the IPU,
# so we don't use the dataloader, to prevent influencing the execution
# time and therefore the IPU throughput calculation
with catchtime() as t:
for _ in range(steps):
training_model(data_batch, labels_batch)
items_per_second = (steps * device_iterations * batch_size * replicas) / t.seconds
print(f"Total execution time: {t.seconds:.2f} s")
print(f"IPU throughput: {items_per_second:.2f} items/s")
training_data.terminate()
Evaluating: 12 steps of 800 items
Total execution time: 0.20 s
IPU throughput: 47323.53 items/s
What if the DataLoader throughput is too low?
You can:
Try using the asynchronous mode of
poptorch.DataLoader;Try to increase the global batch size or the number of device iterations;
Increase the number of workers;
If you are using the asynchronous mode to load a small number of elements per step, you can try setting
miss_sleep_time_in_ms = 0(See below).
Suggestions if the performance drops at the beginning of an epoch:
Re-use workers by setting the DataLoader option
persistent_workers=True;Make sure
load_indefinitelyis set toTrue(the default value);If the first iteration includes a very expensive operation (like opening or loading a large file) then increasing the
buffer_size(size of the ring buffer) combined with the options above might help hide it at the cost of using more memory;Set the option
early_preload=True. This means the data accessor starts loading tensors immediately once it’s being built (whereas usually it will wait for an iterator to be created: for instance, when you enter the main loop).If the DataLoader is created before the model compilation is called, the data will be ready to be used when the compilation is over. The main drawback is that more RAM will be used on host as the data accessor and the compilation will work at the same time.
The options
miss_sleep_time_in_ms,early_preload,load_indefinitelyandbuffer_sizeare specific to the AsynchronousDataAccessor. They will need to be passed to the DataLoader via the dictionaryasync_options:training_data = poptorch.DataLoader(opts, dataset=dataset, batch_size=16, shuffle=True, drop_last=True, num_workers=4, mode=poptorch.DataLoaderMode.Async, async_options={"early_preload": True, "miss_sleep_time_in_ms": 0})
Device iterations vs global batch size
Even if we made sure the DataLoader is not a bottleneck any more, the strategy we used for batching can be suboptimal. We must keep in mind that increasing the global batch size will improve the IPU utilisation while increasing device iterations will not.
Case of a training session
We have seen that the device can efficiently iterate while taking data prepared by the CPU in a queue. However, one iteration implies gradient computation and weight update on the device. The backward pass is computationally expensive. Then, for training it is recommended to prefer bigger global batch size over many device iterations in order to maximise parallelism.
Case of an inference session
For inference only, there is no gradient computation and weights are frozen. In that case increasing the number of device iterations and using a smaller global batch-size should not harm.
Conclusion: Training and inference sessions
Finally, as a general recommendation these two parameters have to be tuned so your DataLoader can consume the whole dataset in the smallest number of steps without throttling. We can get this number of steps just by getting the length of the DataLoader object:
steps = len(training_data)
For an IterableDataset, the whole dataset is not necessarily consumed. With the
drop_last argument, elements of the dataset may be discarded. If the batch
size does not properly divide the number of elements per worker, the last
incomplete batches will be discarded.
Experiments
We invite you to try these different sets of parameters to assess their effect. We included the throughput we obtained for illustration but it may vary depending on your configuration.
We will create a function that uses the previous code and validates the performance of our model:
def validate_model_performance(
dataset,
device_iterations=50,
batch_size=16,
replicas=2,
num_workers=4,
synthetic_data=False,
):
opts = poptorch.Options()
opts.deviceIterations(device_iterations)
opts.replicationFactor(replicas)
opts.enableExecutableCaching(executable_cache_dir)
if synthetic_data:
opts.enableSyntheticData(True)
model = ClassificationModel()
training_model = poptorch.trainingModel(
model,
opts,
poptorch.optim.SGD(
model.parameters(), lr=0.001, momentum=0.9, use_combined_accum=False
),
)
training_data = poptorch.DataLoader(
opts,
dataset=dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=num_workers,
mode=poptorch.DataLoaderMode.Async,
async_options={"early_preload": True},
)
steps = len(training_data)
data_batch, labels_batch = next(iter(training_data))
training_model.compile(data_batch, labels_batch)
with catchtime() as t:
for data_batch, labels_batch in training_data:
pass
items_per_second = (steps * device_iterations * batch_size * replicas) / t.seconds
print(f"DataLoader: {items_per_second:.2f} items/s")
print(f"Dataloader execution time: {t.seconds:.2f} s")
if synthetic_data:
# With synthetic data enabled, no data is copied from the host to the
# IPU, so we don't use the dataloader, to prevent influencing the
# execution time and therefore the IPU throughput calculation
with catchtime() as t:
for _ in range(steps):
training_model(data_batch, labels_batch)
else:
with catchtime() as t:
for data, labels in training_data:
training_model(data, labels)
training_model.detachFromDevice()
items_per_second = (steps * device_iterations * batch_size * replicas) / t.seconds
print(f"IPU throughput: {items_per_second:.2f} items/s")
print(f"Dataloader with IPU training execution time: {t.seconds:.2f} s")
training_data.terminate()
Now we are ready to conduct experiments:
Case 1: No bottleneck
mini-batch size: 16
replica: 1 (no replication)
device iterations: 50
workers: 4
=> Global batch size 16 with real data
validate_model_performance(
dataset,
batch_size=16,
replicas=1,
device_iterations=50,
num_workers=4,
synthetic_data=False,
)
Graph compilation: 100%|██████████| 100/100 [01:25<00:00]
DataLoader: 37710.01 items/s
Dataloader execution time: 0.25 s
IPU throughput: 17956.52 items/s
Dataloader with IPU training execution time: 0.53 s
=> Global batch size 16 with synthetic data
validate_model_performance(
dataset,
batch_size=16,
replicas=1,
device_iterations=50,
num_workers=4,
synthetic_data=True,
)
Graph compilation: 100%|██████████| 100/100 [01:20<00:00]
DataLoader: 40820.89 items/s
Dataloader execution time: 0.24 s
IPU throughput: 46739.05 items/s
Dataloader with IPU training execution time: 0.21 s
From the tests you should be able to see that the throughput with processing the model is less than the capabilities of the Dataloader. This means that dataloader is not a bottleneck as it is able to process more data than our model can consume.
Why is the throughput lower with real data?
As mentioned previously, using synthetic data does not include the stream copies on the IPU. It also excludes the synchronisation time with the host.
Case 2: Larger global batch size with replication
Let’s try to get better training performances by increasing the global batch size. We can choose to increase the replication factor so it avoids loading more data at a time on a single IPU.
mini-batch size: 16
replica: 2
device iterations: 50
workers: 4
=> Global batch size 32 with real data
validate_model_performance(
dataset,
batch_size=16,
replicas=2,
device_iterations=50,
num_workers=4,
synthetic_data=False,
)
Graph compilation: 100%|██████████| 100/100 [01:28<00:00]
DataLoader: 42604.88 items/s
Dataloader execution time: 0.23 s
IPU throughput: 14974.44 items/s
Dataloader with IPU training execution time: 0.64 s
=> Global batch size 32 with synthetic data
validate_model_performance(
dataset,
batch_size=16,
replicas=2,
device_iterations=50,
num_workers=4,
synthetic_data=True,
)
Graph compilation: 100%|██████████| 100/100 [01:26<00:00]
DataLoader: 36126.00 items/s
Dataloader execution time: 0.27 s
IPU throughput: 46384.23 items/s
Dataloader with IPU training execution time: 0.21 s
Throughput of dataloader for synthetic and real data should be roughly the same. However, given the small number of steps (3 steps) and the very short execution time of the application (of the order of thousandths of a second) the results may diverge slightly more.
This example gave an idea of how increasing the global batch size can improve the throughput.
The runtime script where you can play with the parameters can be found in the
file: tuto_data_loading.py. Helpful arguments:
--synthetic-data # Run with IPU-generated synthetic data
--replicas # Takes an integer parameter to set the number of replicas
Summary
To efficiently load your dataset to the IPU, the best practice is to use the dedicated PopTorch DataLoader;
During one step, N = Global batch size x Device iterations samples will be loaded;
A good way to know if the DataLoader is not a bottleneck is to compare its throughput with the model throughput on synthetic data;
Asynchronous mode can provide better throughput performance.
Further information on Host-IPU IO optimisation can be found in our memory and performance optimisation guide.
Generated:2022-11-14T16:55 Source:walkthrough.py SDK:3.1.0-EA.1+1180 SST:0.0.7